 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLD
Papers and Code
BEV-SLD: Self-Supervised Scene Landmark Detection for Global Localization with LiDAR Bird's-Eye View Images
Mar 17, 2026We present BEV-SLD, a LiDAR global localization method building on the Scene Landmark Detection (SLD) concept. Unlike scene-agnostic pipelines, our self-supervised approach leverages bird's-eye-view (BEV) images to discover scene-specific patterns at a prescribed spatial density and treat them as landmarks. A consistency loss aligns learnable global landmark coordinates with per-frame heatmaps, yielding consistent landmark detections across the scene. Across campus, industrial, and forest environments, BEV-SLD delivers robust localization and achieves strong performance compared to state-of-the-art methods.
SLD-L2S: Hierarchical Subspace Latent Diffusion for High-Fidelity Lip to Speech Synthesis
Feb 12, 2026Although lip-to-speech synthesis (L2S) has achieved significant progress in recent years, current state-of-the-art methods typically rely on intermediate representations such as mel-spectrograms or discrete self-supervised learning (SSL) tokens. The potential of latent diffusion models (LDMs) in this task remains largely unexplored. In this paper, we introduce SLD-L2S, a novel L2S framework built upon a hierarchical subspace latent diffusion model. Our method aims to directly map visual lip movements to the continuous latent space of a pre-trained neural audio codec, thereby avoiding the information loss inherent in traditional intermediate representations. The core of our method is a hierarchical architecture that processes visual representations through multiple parallel subspaces, initiated by a subspace decomposition module. To efficiently enhance interactions within and between these subspaces, we design the diffusion convolution block (DiCB) as our network backbone. Furthermore, we employ a reparameterized flow matching technique to directly generate the target latent vectors. This enables a principled inclusion of speech language model (SLM) and semantic losses during training, moving beyond conventional flow matching objectives and improving synthesized speech quality. Our experiments show that SLD-L2S achieves state-of-the-art generation quality on multiple benchmark datasets, surpassing existing methods in both objective and subjective evaluations.
SLD: Segmentation-Based Landmark Detection for Spinal Ligaments
Jan 23, 2026In biomechanical modeling, the representation of ligament attachments is crucial for a realistic simulation of the forces acting between the vertebrae. These forces are typically modeled as vectors connecting ligament landmarks on adjacent vertebrae, making precise identification of these landmarks a key requirement for constructing reliable spine models. Existing automated detection methods are either limited to specific spinal regions or lack sufficient accuracy. This work presents a novel approach for detecting spinal ligament landmarks, which first performs shape-based segmentation of 3D vertebrae and subsequently applies domain-specific rules to identify different types of attachment points. The proposed method outperforms existing approaches by achieving high accuracy and demonstrating strong generalization across all spinal regions. Validation on two independent spinal datasets from multiple patients yielded a mean absolute error (MAE) of 0.7 mm and a root mean square error (RMSE) of 1.1 mm.
A Multi-Mode Structured Light 3D Imaging System with Multi-Source Information Fusion for Underwater Pipeline Detection
Dec 12, 2025



Underwater pipelines are highly susceptible to corrosion, which not only shorten their service life but also pose significant safety risks. Compared with manual inspection, the intelligent real-time imaging system for underwater pipeline detection has become a more reliable and practical solution. Among various underwater imaging techniques, structured light 3D imaging can restore the sufficient spatial detail for precise defect characterization. Therefore, this paper develops a multi-mode underwater structured light 3D imaging system for pipeline detection (UW-SLD system) based on multi-source information fusion. First, a rapid distortion correction (FDC) method is employed for efficient underwater image rectification. To overcome the challenges of extrinsic calibration among underwater sensors, a factor graph-based parameter optimization method is proposed to estimate the transformation matrix between the structured light and acoustic sensors. Furthermore, a multi-mode 3D imaging strategy is introduced to adapt to the geometric variability of underwater pipelines. Given the presence of numerous disturbances in underwater environments, a multi-source information fusion strategy and an adaptive extended Kalman filter (AEKF) are designed to ensure stable pose estimation and high-accuracy measurements. In particular, an edge detection-based ICP (ED-ICP) algorithm is proposed. This algorithm integrates pipeline edge detection network with enhanced point cloud registration to achieve robust and high-fidelity reconstruction of defect structures even under variable motion conditions. Extensive experiments are conducted under different operation modes, velocities, and depths. The results demonstrate that the developed system achieves superior accuracy, adaptability and robustness, providing a solid foundation for autonomous underwater pipeline detection.
FreqU-FNet: Frequency-Aware U-Net for Imbalanced Medical Image Segmentation
May 23, 2025Medical image segmentation faces persistent challenges due to severe class imbalance and the frequency-specific distribution of anatomical structures. Most conventional CNN-based methods operate in the spatial domain and struggle to capture minority class signals, often affected by frequency aliasing and limited spectral selectivity. Transformer-based models, while powerful in modeling global dependencies, tend to overlook critical local details necessary for fine-grained segmentation. To overcome these limitations, we propose FreqU-FNet, a novel U-shaped segmentation architecture operating in the frequency domain. Our framework incorporates a Frequency Encoder that leverages Low-Pass Frequency Convolution and Daubechies wavelet-based downsampling to extract multi-scale spectral features. To reconstruct fine spatial details, we introduce a Spatial Learnable Decoder (SLD) equipped with an adaptive multi-branch upsampling strategy. Furthermore, we design a frequency-aware loss (FAL) function to enhance minority class learning. Extensive experiments on multiple medical segmentation benchmarks demonstrate that FreqU-FNet consistently outperforms both CNN and Transformer baselines, particularly in handling under-represented classes, by effectively exploiting discriminative frequency bands.
Swapped Logit Distillation via Bi-level Teacher Alignment
Apr 27, 2025Knowledge distillation (KD) compresses the network capacity by transferring knowledge from a large (teacher) network to a smaller one (student). It has been mainstream that the teacher directly transfers knowledge to the student with its original distribution, which can possibly lead to incorrect predictions. In this article, we propose a logit-based distillation via swapped logit processing, namely Swapped Logit Distillation (SLD). SLD is proposed under two assumptions: (1) the wrong prediction occurs when the prediction label confidence is not the maximum; (2) the "natural" limit of probability remains uncertain as the best value addition to the target cannot be determined. To address these issues, we propose a swapped logit processing scheme. Through this approach, we find that the swap method can be effectively extended to teacher and student outputs, transforming into two teachers. We further introduce loss scheduling to boost the performance of two teachers' alignment. Extensive experiments on image classification tasks demonstrate that SLD consistently performs best among previous state-of-the-art methods.
On the Logical Content of Logic Programs
Mar 07, 2025Logic programming (LP) is typically understood through operational semantics (e.g., SLD-resolution) or model-theoretic interpretations (e.g., the least Herbrand model). This paper introduces a novel perspective on LP by defining a ``support'' relation that explicates what a program ``knows''. This interpretation is shown to express classical and intuitionistic logic, as well as an intermediate logic, depending on certain choices regarding LP and the meanings of disjunction and negation. These results are formalized using the idea of base-extension semantics within proof-theoretic semantics. Our approach offers new insights into the logical foundations of LP and has potential applications in knowledge representation, automated reasoning, and formal verification.
Illuminating Spaces: Deep Reinforcement Learning and Laser-Wall Partitioning for Architectural Layout Generation
Feb 06, 2025Space layout design (SLD), occurring in the early stages of the design process, nonetheless influences both the functionality and aesthetics of the ultimate architectural outcome. The complexity of SLD necessitates innovative approaches to efficiently explore vast solution spaces. While image-based generative AI has emerged as a potential solution, they often rely on pixel-based space composition methods that lack intuitive representation of architectural processes. This paper leverages deep Reinforcement Learning (RL), as it offers a procedural approach that intuitively mimics the process of human designers. Effectively using RL for SLD requires an explorative space composing method to generate desirable design solutions. We introduce "laser-wall", a novel space partitioning method that conceptualizes walls as emitters of imaginary light beams to partition spaces. This approach bridges vector-based and pixel-based partitioning methods, offering both flexibility and exploratory power in generating diverse layouts. We present two planning strategies: one-shot planning, which generates entire layouts in a single pass, and dynamic planning, which allows for adaptive refinement by continuously transforming laser-walls. Additionally, we introduce on-light and off-light wall transformations for smooth and fast layout refinement, as well as identity-less and identity-full walls for versatile room assignment. We developed SpaceLayoutGym, an open-source OpenAI Gym compatible simulator for generating and evaluating space layouts. The RL agent processes the input design scenarios and generates solutions following a reward function that balances geometrical and topological requirements. Our results demonstrate that the RL-based laser-wall approach can generate diverse and functional space layouts that satisfy both geometric constraints and topological requirements and is architecturally intuitive.
Segment-Level Diffusion: A Framework for Controllable Long-Form Generation with Diffusion Language Models
Dec 15, 2024



Diffusion models have shown promise in text generation but often struggle with generating long, coherent, and contextually accurate text. Token-level diffusion overlooks word-order dependencies and enforces short output windows, while passage-level diffusion struggles with learning robust representation for long-form text. To address these challenges, we propose Segment-Level Diffusion (SLD), a framework that enhances diffusion-based text generation through text segmentation, robust representation training with adversarial and contrastive learning, and improved latent-space guidance. By segmenting long-form outputs into separate latent representations and decoding them with an autoregressive decoder, SLD simplifies diffusion predictions and improves scalability. Experiments on XSum, ROCStories, DialogSum, and DeliData demonstrate that SLD achieves competitive or superior performance in fluency, coherence, and contextual compatibility across automatic and human evaluation metrics comparing with other diffusion and autoregressive baselines. Ablation studies further validate the effectiveness of our segmentation and representation learning strategies.
AdvI2I: Adversarial Image Attack on Image-to-Image Diffusion models
Oct 28, 2024
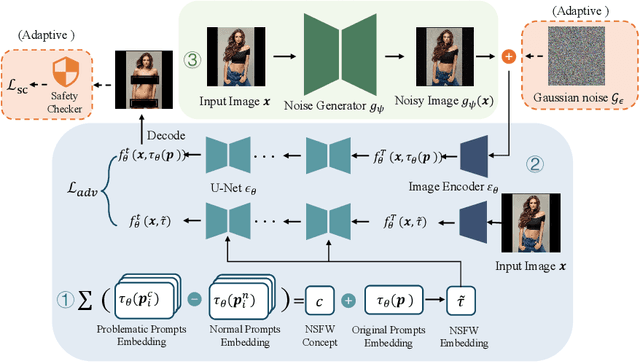


Recent advances in diffusion models have significantly enhanced the quality of image synthesis, yet they have also introduced serious safety concerns, particularly the generation of Not Safe for Work (NSFW) content. Previous research has demonstrated that adversarial prompts can be used to generate NSFW content. However, such adversarial text prompts are often easily detectable by text-based filters, limiting their efficacy. In this paper, we expose a previously overlooked vulnerability: adversarial image attacks targeting Image-to-Image (I2I) diffusion models. We propose AdvI2I, a novel framework that manipulates input images to induce diffusion models to generate NSFW content. By optimizing a generator to craft adversarial images, AdvI2I circumvents existing defense mechanisms, such as Safe Latent Diffusion (SLD), without altering the text prompts. Furthermore, we introduce AdvI2I-Adaptive, an enhanced version that adapts to potential countermeasures and minimizes the resemblance between adversarial images and NSFW concept embeddings, making the attack more resilient against defenses. Through extensive experiments, we demonstrate that both AdvI2I and AdvI2I-Adaptive can effectively bypass current safeguards, highlighting the urgent need for stronger security measures to address the misuse of I2I diffusion models.