 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Gaussian Blur
Papers and Code
Random-phase Gaussian Wave Splatting for Computer-generated Holography
Aug 24, 2025Holographic near-eye displays offer ultra-compact form factors for virtual and augmented reality systems, but rely on advanced computer-generated holography (CGH) algorithms to convert 3D scenes into interference patterns that can be displayed on spatial light modulators (SLMs). Gaussian Wave Splatting (GWS) has recently emerged as a powerful CGH paradigm that allows for the conversion of Gaussians, a state-of-the-art neural 3D representation, into holograms. However, GWS assumes smooth-phase distributions over the Gaussian primitives, limiting their ability to model view-dependent effects and reconstruct accurate defocus blur, and severely under-utilizing the space-bandwidth product of the SLM. In this work, we propose random-phase GWS (GWS-RP) to improve bandwidth utilization, which has the effect of increasing eyebox size, reconstructing accurate defocus blur and parallax, and supporting time-multiplexed rendering to suppress speckle artifacts. At the core of GWS-RP are (1) a fundamentally new wavefront compositing procedure and (2) an alpha-blending scheme specifically designed for random-phase Gaussian primitives, ensuring physically correct color reconstruction and robust occlusion handling. Additionally, we present the first formally derived algorithm for applying random phase to Gaussian primitives, grounded in rigorous statistical optics analysis and validated through practical near-eye display applications. Through extensive simulations and experimental validations, we demonstrate that these advancements, collectively with time-multiplexing, uniquely enables full-bandwith light field CGH that supports accurate accurate parallax and defocus, yielding state-of-the-art image quality and perceptually faithful 3D holograms for next-generation near-eye displays.
Training-Free Watermarking for Autoregressive Image Generation
May 20, 2025



Invisible image watermarking can protect image ownership and prevent malicious misuse of visual generative models. However, existing generative watermarking methods are mainly designed for diffusion models while watermarking for autoregressive image generation models remains largely underexplored. We propose IndexMark, a training-free watermarking framework for autoregressive image generation models. IndexMark is inspired by the redundancy property of the codebook: replacing autoregressively generated indices with similar indices produces negligible visual differences. The core component in IndexMark is a simple yet effective match-then-replace method, which carefully selects watermark tokens from the codebook based on token similarity, and promotes the use of watermark tokens through token replacement, thereby embedding the watermark without affecting the image quality. Watermark verification is achieved by calculating the proportion of watermark tokens in generated images, with precision further improved by an Index Encoder. Furthermore, we introduce an auxiliary validation scheme to enhance robustness against cropping attacks. Experiments demonstrate that IndexMark achieves state-of-the-art performance in terms of image quality and verification accuracy, and exhibits robustness against various perturbations, including cropping, noises, Gaussian blur, random erasing, color jittering, and JPEG compression.
CA-Cut: Crop-Aligned Cutout for Data Augmentation to Learn More Robust Under-Canopy Navigation
Jul 24, 2025State-of-the-art visual under-canopy navigation methods are designed with deep learning-based perception models to distinguish traversable space from crop rows. While these models have demonstrated successful performance, they require large amounts of training data to ensure reliability in real-world field deployment. However, data collection is costly, demanding significant human resources for in-field sampling and annotation. To address this challenge, various data augmentation techniques are commonly employed during model training, such as color jittering, Gaussian blur, and horizontal flip, to diversify training data and enhance model robustness. In this paper, we hypothesize that utilizing only these augmentation techniques may lead to suboptimal performance, particularly in complex under-canopy environments with frequent occlusions, debris, and non-uniform spacing of crops. Instead, we propose a novel augmentation method, so-called Crop-Aligned Cutout (CA-Cut) which masks random regions out in input images that are spatially distributed around crop rows on the sides to encourage trained models to capture high-level contextual features even when fine-grained information is obstructed. Our extensive experiments with a public cornfield dataset demonstrate that masking-based augmentations are effective for simulating occlusions and significantly improving robustness in semantic keypoint predictions for visual navigation. In particular, we show that biasing the mask distribution toward crop rows in CA-Cut is critical for enhancing both prediction accuracy and generalizability across diverse environments achieving up to a 36.9% reduction in prediction error. In addition, we conduct ablation studies to determine the number of masks, the size of each mask, and the spatial distribution of masks to maximize overall performance.
AttentionDrop: A Novel Regularization Method for Transformer Models
Apr 16, 2025



Transformer-based architectures achieve state-of-the-art performance across a wide range of tasks in natural language processing, computer vision, and speech. However, their immense capacity often leads to overfitting, especially when training data is limited or noisy. We propose AttentionDrop, a unified family of stochastic regularization techniques that operate directly on the self-attention distributions. We introduces three variants: 1. Hard Attention Masking: randomly zeroes out top-k attention logits per query to encourage diverse context utilization. 2. Blurred Attention Smoothing: applies a dynamic Gaussian convolution over attention logits to diffuse overly peaked distributions. 3. Consistency-Regularized AttentionDrop: enforces output stability under multiple independent AttentionDrop perturbations via a KL-based consistency loss.
GS-Blur: A 3D Scene-Based Dataset for Realistic Image Deblurring
Oct 31, 2024



To train a deblurring network, an appropriate dataset with paired blurry and sharp images is essential. Existing datasets collect blurry images either synthetically by aggregating consecutive sharp frames or using sophisticated camera systems to capture real blur. However, these methods offer limited diversity in blur types (blur trajectories) or require extensive human effort to reconstruct large-scale datasets, failing to fully reflect real-world blur scenarios. To address this, we propose GS-Blur, a dataset of synthesized realistic blurry images created using a novel approach. To this end, we first reconstruct 3D scenes from multi-view images using 3D Gaussian Splatting (3DGS), then render blurry images by moving the camera view along the randomly generated motion trajectories. By adopting various camera trajectories in reconstructing our GS-Blur, our dataset contains realistic and diverse types of blur, offering a large-scale dataset that generalizes well to real-world blur. Using GS-Blur with various deblurring methods, we demonstrate its ability to generalize effectively compared to previous synthetic or real blur datasets, showing significant improvements in deblurring performance.
Blind Super-Resolution via Meta-learning and Markov Chain Monte Carlo Simulation
Jun 13, 2024



Learning-based approaches have witnessed great successes in blind single image super-resolution (SISR) tasks, however, handcrafted kernel priors and learning based kernel priors are typically required. In this paper, we propose a Meta-learning and Markov Chain Monte Carlo (MCMC) based SISR approach to learn kernel priors from organized randomness. In concrete, a lightweight network is adopted as kernel generator, and is optimized via learning from the MCMC simulation on random Gaussian distributions. This procedure provides an approximation for the rational blur kernel, and introduces a network-level Langevin dynamics into SISR optimization processes, which contributes to preventing bad local optimal solutions for kernel estimation. Meanwhile, a meta-learning-based alternating optimization procedure is proposed to optimize the kernel generator and image restorer, respectively. In contrast to the conventional alternating minimization strategy, a meta-learning-based framework is applied to learn an adaptive optimization strategy, which is less-greedy and results in better convergence performance. These two procedures are iteratively processed in a plug-and-play fashion, for the first time, realizing a learning-based but plug-and-play blind SISR solution in unsupervised inference. Extensive simulations demonstrate the superior performance and generalization ability of the proposed approach when comparing with state-of-the-arts on synthesis and real-world datasets. The code is available at https://github.com/XYLGroup/MLMC.
Quantifying Smooth Muscles Regional Organization in the Rat Bladder Using Immunohistochemistry, Multiphoton Microscopy and Machine Learning
May 08, 2024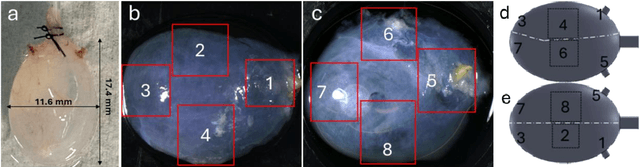
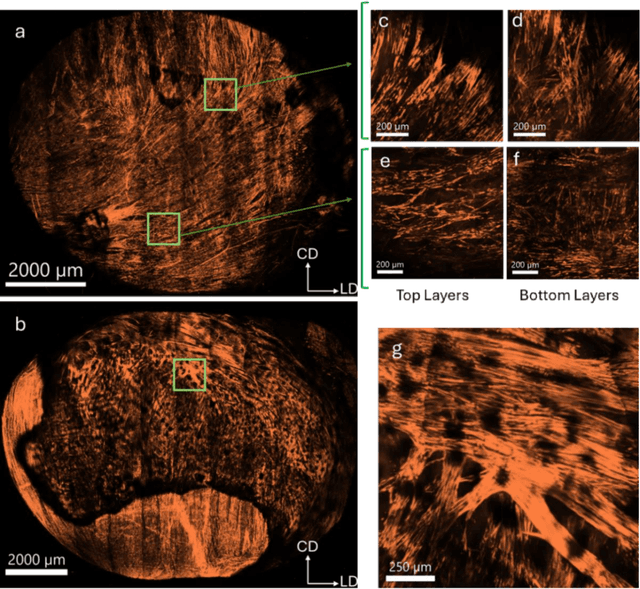

The smooth muscle bundles (SMBs) in the bladder act as contractile elements which enable the bladder to void effectively. In contrast to skeletal muscles, these bundles are not highly aligned, rather they are oriented more heterogeneously throughout the bladder wall. In this work, for the first time, this regional orientation of the SMBs is quantified across the whole bladder, without the need for optical clearing or cryosectioning. Immunohistochemistry staining was utilized to visualize smooth muscle cell actin in multiphoton microscopy (MPM) images of bladder smooth muscle bundles (SMBs). Feature vectors for each pixel were generated using a range of filters, including Gaussian blur, Gaussian gradient magnitude, Laplacian of Gaussian, Hessian eigenvalues, structure tensor eigenvalues, Gabor, and Sobel gradients. A Random Forest classifier was subsequently trained to automate the segmentation of SMBs in the MPM images. Finally, the orientation of SMBs in each bladder region was quantified using the CT-FIRE package. This information is essential for biomechanical models of the bladder that include contractile elements.
Universal Robustness via Median Randomized Smoothing for Real-World Super-Resolution
May 23, 2024



Most of the recent literature on image Super-Resolution (SR) can be classified into two main approaches. The first one involves learning a corruption model tailored to a specific dataset, aiming to mimic the noise and corruption in low-resolution images, such as sensor noise. However, this approach is data-specific, tends to lack adaptability, and its accuracy diminishes when faced with unseen types of image corruptions. A second and more recent approach, referred to as Robust Super-Resolution (RSR), proposes to improve real-world SR by harnessing the generalization capabilities of a model by making it robust to adversarial attacks. To delve further into this second approach, our paper explores the universality of various methods for enhancing the robustness of deep learning SR models. In other words, we inquire: "Which robustness method exhibits the highest degree of adaptability when dealing with a wide range of adversarial attacks ?". Our extensive experimentation on both synthetic and real-world images empirically demonstrates that median randomized smoothing (MRS) is more general in terms of robustness compared to adversarial learning techniques, which tend to focus on specific types of attacks. Furthermore, as expected, we also illustrate that the proposed universal robust method enables the SR model to handle standard corruptions more effectively, such as blur and Gaussian noise, and notably, corruptions naturally present in real-world images. These results support the significance of shifting the paradigm in the development of real-world SR methods towards RSR, especially via MRS.
Reference-Free Image Quality Metric for Degradation and Reconstruction Artifacts
May 01, 2024



Image Quality Assessment (IQA) is essential in various Computer Vision tasks such as image deblurring and super-resolution. However, most IQA methods require reference images, which are not always available. While there are some reference-free IQA metrics, they have limitations in simulating human perception and discerning subtle image quality variations. We hypothesize that the JPEG quality factor is representatives of image quality measurement, and a well-trained neural network can learn to accurately evaluate image quality without requiring a clean reference, as it can recognize image degradation artifacts based on prior knowledge. Thus, we developed a reference-free quality evaluation network, dubbed "Quality Factor (QF) Predictor", which does not require any reference. Our QF Predictor is a lightweight, fully convolutional network comprising seven layers. The model is trained in a self-supervised manner: it receives JPEG compressed image patch with a random QF as input, is trained to accurately predict the corresponding QF. We demonstrate the versatility of the model by applying it to various tasks. First, our QF Predictor can generalize to measure the severity of various image artifacts, such as Gaussian Blur and Gaussian noise. Second, we show that the QF Predictor can be trained to predict the undersampling rate of images reconstructed from Magnetic Resonance Imaging (MRI) data.
A Dynamic Kernel Prior Model for Unsupervised Blind Image Super-Resolution
Apr 26, 2024



Deep learning-based methods have achieved significant successes on solving the blind super-resolution (BSR) problem. However, most of them request supervised pre-training on labelled datasets. This paper proposes an unsupervised kernel estimation model, named dynamic kernel prior (DKP), to realize an unsupervised and pre-training-free learning-based algorithm for solving the BSR problem. DKP can adaptively learn dynamic kernel priors to realize real-time kernel estimation, and thereby enables superior HR image restoration performances. This is achieved by a Markov chain Monte Carlo sampling process on random kernel distributions. The learned kernel prior is then assigned to optimize a blur kernel estimation network, which entails a network-based Langevin dynamic optimization strategy. These two techniques ensure the accuracy of the kernel estimation. DKP can be easily used to replace the kernel estimation models in the existing methods, such as Double-DIP and FKP-DIP, or be added to the off-the-shelf image restoration model, such as diffusion model. In this paper, we incorporate our DKP model with DIP and diffusion model, referring to DIP-DKP and Diff-DKP, for validations. Extensive simulations on Gaussian and motion kernel scenarios demonstrate that the proposed DKP model can significantly improve the kernel estimation with comparable runtime and memory usage, leading to state-of-the-art BSR results. The code is available at https://github.com/XYLGroup/DKP.