 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicate Detection
Papers and Code
From Lemmas to Dependencies: What Signals Drive Light Verbs Classification?
Feb 04, 2026Light verb constructions (LVCs) are a challenging class of verbal multiword expressions, especially in Turkish, where rich morphology and productive complex predicates create minimal contrasts between idiomatic predicate meanings and literal verb--argument uses. This paper asks what signals drive LVC classification by systematically restricting model inputs. Using UD-derived supervision, we compare lemma-driven baselines (lemma TF--IDF + Logistic Regression; BERTurk trained on lemma sequences), a grammar-only Logistic Regression over UD morphosyntax (UPOS/DEPREL/MORPH), and a full-input BERTurk baseline. We evaluate on a controlled diagnostic set with Random negatives, lexical controls (NLVC), and LVC positives, reporting split-wise performance to expose decision-boundary behavior. Results show that coarse morphosyntax alone is insufficient for robust LVC detection under controlled contrasts, while lexical identity supports LVC judgments but is sensitive to calibration and normalization choices. Overall, Our findings motivate targeted evaluation of Turkish MWEs and show that ``lemma-only'' is not a single, well-defined representation, but one that depends critically on how normalization is operationalized.
GAVEL: Towards rule-based safety through activation monitoring
Jan 29, 2026Large language models (LLMs) are increasingly paired with activation-based monitoring to detect and prevent harmful behaviors that may not be apparent at the surface-text level. However, existing activation safety approaches, trained on broad misuse datasets, struggle with poor precision, limited flexibility, and lack of interpretability. This paper introduces a new paradigm: rule-based activation safety, inspired by rule-sharing practices in cybersecurity. We propose modeling activations as cognitive elements (CEs), fine-grained, interpretable factors such as ''making a threat'' and ''payment processing'', that can be composed to capture nuanced, domain-specific behaviors with higher precision. Building on this representation, we present a practical framework that defines predicate rules over CEs and detects violations in real time. This enables practitioners to configure and update safeguards without retraining models or detectors, while supporting transparency and auditability. Our results show that compositional rule-based activation safety improves precision, supports domain customization, and lays the groundwork for scalable, interpretable, and auditable AI governance. We will release GAVEL as an open-source framework and provide an accompanying automated rule creation tool.
TriCEGAR: A Trace-Driven Abstraction Mechanism for Agentic AI
Jan 30, 2026Agentic AI systems act through tools and evolve their behavior over long, stochastic interaction traces. This setting complicates assurance, because behavior depends on nondeterministic environments and probabilistic model outputs. Prior work introduced runtime verification for agentic AI via Dynamic Probabilistic Assurance (DPA), learning an MDP online and model checking quantitative properties. A key limitation is that developers must manually define the state abstraction, which couples verification to application-specific heuristics and increases adoption friction. This paper proposes TriCEGAR, a trace-driven abstraction mechanism that automates state construction from execution logs and supports online construction of an agent behavioral MDP. TriCEGAR represents abstractions as predicate trees learned from traces and refined using counterexamples. We describe a framework-native implementation that (i) captures typed agent lifecycle events, (ii) builds abstractions from traces, (iii) constructs an MDP, and (iv) performs probabilistic model checking to compute bounds such as Pmax(success) and Pmin(failure). We also show how run likelihoods enable anomaly detection as a guardrailing signal.
RoboSafe: Safeguarding Embodied Agents via Executable Safety Logic
Dec 24, 2025Embodied agents powered by vision-language models (VLMs) are increasingly capable of executing complex real-world tasks, yet they remain vulnerable to hazardous instructions that may trigger unsafe behaviors. Runtime safety guardrails, which intercept hazardous actions during task execution, offer a promising solution due to their flexibility. However, existing defenses often rely on static rule filters or prompt-level control, which struggle to address implicit risks arising in dynamic, temporally dependent, and context-rich environments. To address this, we propose RoboSafe, a hybrid reasoning runtime safeguard for embodied agents through executable predicate-based safety logic. RoboSafe integrates two complementary reasoning processes on a Hybrid Long-Short Safety Memory. We first propose a Backward Reflective Reasoning module that continuously revisits recent trajectories in short-term memory to infer temporal safety predicates and proactively triggers replanning when violations are detected. We then propose a Forward Predictive Reasoning module that anticipates upcoming risks by generating context-aware safety predicates from the long-term safety memory and the agent's multimodal observations. Together, these components form an adaptive, verifiable safety logic that is both interpretable and executable as code. Extensive experiments across multiple agents demonstrate that RoboSafe substantially reduces hazardous actions (-36.8% risk occurrence) compared with leading baselines, while maintaining near-original task performance. Real-world evaluations on physical robotic arms further confirm its practicality. Code will be released upon acceptance.
Bridging Modalities and Transferring Knowledge: Enhanced Multimodal Understanding and Recognition
Dec 23, 2025This manuscript explores multimodal alignment, translation, fusion, and transference to enhance machine understanding of complex inputs. We organize the work into five chapters, each addressing unique challenges in multimodal machine learning. Chapter 3 introduces Spatial-Reasoning Bert for translating text-based spatial relations into 2D arrangements between clip-arts. This enables effective decoding of spatial language into visual representations, paving the way for automated scene generation aligned with human spatial understanding. Chapter 4 presents a method for translating medical texts into specific 3D locations within an anatomical atlas. We introduce a loss function leveraging spatial co-occurrences of medical terms to create interpretable mappings, significantly enhancing medical text navigability. Chapter 5 tackles translating structured text into canonical facts within knowledge graphs. We develop a benchmark for linking natural language to entities and predicates, addressing ambiguities in text extraction to provide clearer, actionable insights. Chapter 6 explores multimodal fusion methods for compositional action recognition. We propose a method fusing video frames and object detection representations, improving recognition robustness and accuracy. Chapter 7 investigates multimodal knowledge transference for egocentric action recognition. We demonstrate how multimodal knowledge distillation enables RGB-only models to mimic multimodal fusion-based capabilities, reducing computational requirements while maintaining performance. These contributions advance methodologies for spatial language understanding, medical text interpretation, knowledge graph enrichment, and action recognition, enhancing computational systems' ability to process complex, multimodal inputs across diverse applications.
ODKE+: Ontology-Guided Open-Domain Knowledge Extraction with LLMs
Sep 04, 2025



Knowledge graphs (KGs) are foundational to many AI applications, but maintaining their freshness and completeness remains costly. We present ODKE+, a production-grade system that automatically extracts and ingests millions of open-domain facts from web sources with high precision. ODKE+ combines modular components into a scalable pipeline: (1) the Extraction Initiator detects missing or stale facts, (2) the Evidence Retriever collects supporting documents, (3) hybrid Knowledge Extractors apply both pattern-based rules and ontology-guided prompting for large language models (LLMs), (4) a lightweight Grounder validates extracted facts using a second LLM, and (5) the Corroborator ranks and normalizes candidate facts for ingestion. ODKE+ dynamically generates ontology snippets tailored to each entity type to align extractions with schema constraints, enabling scalable, type-consistent fact extraction across 195 predicates. The system supports batch and streaming modes, processing over 9 million Wikipedia pages and ingesting 19 million high-confidence facts with 98.8% precision. ODKE+ significantly improves coverage over traditional methods, achieving up to 48% overlap with third-party KGs and reducing update lag by 50 days on average. Our deployment demonstrates that LLM-based extraction, grounded in ontological structure and verification workflows, can deliver trustworthiness, production-scale knowledge ingestion with broad real-world applicability. A recording of the system demonstration is included with the submission and is also available at https://youtu.be/UcnE3_GsTWs.
Hallucinate, Ground, Repeat: A Framework for Generalized Visual Relationship Detection
Jun 06, 2025Understanding relationships between objects is central to visual intelligence, with applications in embodied AI, assistive systems, and scene understanding. Yet, most visual relationship detection (VRD) models rely on a fixed predicate set, limiting their generalization to novel interactions. A key challenge is the inability to visually ground semantically plausible, but unannotated, relationships hypothesized from external knowledge. This work introduces an iterative visual grounding framework that leverages large language models (LLMs) as structured relational priors. Inspired by expectation-maximization (EM), our method alternates between generating candidate scene graphs from detected objects using an LLM (expectation) and training a visual model to align these hypotheses with perceptual evidence (maximization). This process bootstraps relational understanding beyond annotated data and enables generalization to unseen predicates. Additionally, we introduce a new benchmark for open-world VRD on Visual Genome with 21 held-out predicates and evaluate under three settings: seen, unseen, and mixed. Our model outperforms LLM-only, few-shot, and debiased baselines, achieving mean recall (mR@50) of 15.9, 13.1, and 11.7 on predicate classification on these three sets. These results highlight the promise of grounded LLM priors for scalable open-world visual understanding.
RvLLM: LLM Runtime Verification with Domain Knowledge
May 24, 2025Large language models (LLMs) have emerged as a dominant AI paradigm due to their exceptional text understanding and generation capabilities. However, their tendency to generate inconsistent or erroneous outputs challenges their reliability, especially in high-stakes domains requiring accuracy and trustworthiness. Existing research primarily focuses on detecting and mitigating model misbehavior in general-purpose scenarios, often overlooking the potential of integrating domain-specific knowledge. In this work, we advance misbehavior detection by incorporating domain knowledge. The core idea is to design a general specification language that enables domain experts to customize domain-specific predicates in a lightweight and intuitive manner, supporting later runtime verification of LLM outputs. To achieve this, we design a novel specification language, ESL, and introduce a runtime verification framework, RvLLM, to validate LLM output against domain-specific constraints defined in ESL. We evaluate RvLLM on three representative tasks: violation detection against Singapore Rapid Transit Systems Act, numerical comparison, and inequality solving. Experimental results demonstrate that RvLLM effectively detects erroneous outputs across various LLMs in a lightweight and flexible manner. The results reveal that despite their impressive capabilities, LLMs remain prone to low-level errors due to limited interpretability and a lack of formal guarantees during inference, and our framework offers a potential long-term solution by leveraging expert domain knowledge to rigorously and efficiently verify LLM outputs.
Property-Preserving Hashing for $\ell_1$-Distance Predicates: Applications to Countering Adversarial Input Attacks
Apr 23, 2025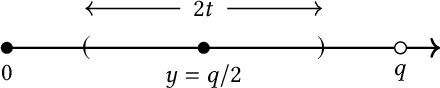
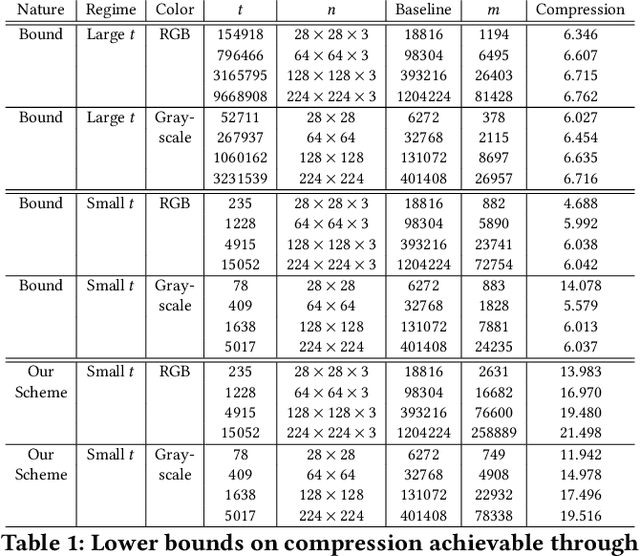
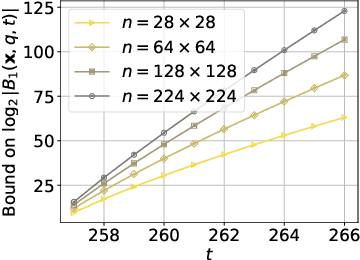
Perceptual hashing is used to detect whether an input image is similar to a reference image with a variety of security applications. Recently, they have been shown to succumb to adversarial input attacks which make small imperceptible changes to the input image yet the hashing algorithm does not detect its similarity to the original image. Property-preserving hashing (PPH) is a recent construct in cryptography, which preserves some property (predicate) of its inputs in the hash domain. Researchers have so far shown constructions of PPH for Hamming distance predicates, which, for instance, outputs 1 if two inputs are within Hamming distance $t$. A key feature of PPH is its strong correctness guarantee, i.e., the probability that the predicate will not be correctly evaluated in the hash domain is negligible. Motivated by the use case of detecting similar images under adversarial setting, we propose the first PPH construction for an $\ell_1$-distance predicate. Roughly, this predicate checks if the two one-sided $\ell_1$-distances between two images are within a threshold $t$. Since many adversarial attacks use $\ell_2$-distance (related to $\ell_1$-distance) as the objective function to perturb the input image, by appropriately choosing the threshold $t$, we can force the attacker to add considerable noise to evade detection, and hence significantly deteriorate the image quality. Our proposed scheme is highly efficient, and runs in time $O(t^2)$. For grayscale images of size $28 \times 28$, we can evaluate the predicate in $0.0784$ seconds when pixel values are perturbed by up to $1 \%$. For larger RGB images of size $224 \times 224$, by dividing the image into 1,000 blocks, we achieve times of $0.0128$ seconds per block for $1 \%$ change, and up to $0.2641$ seconds per block for $14\%$ change.
Leveraging Knowledge Graphs and LLMs for Structured Generation of Misinformation
May 30, 2025The rapid spread of misinformation, further amplified by recent advances in generative AI, poses significant threats to society, impacting public opinion, democratic stability, and national security. Understanding and proactively assessing these threats requires exploring methodologies that enable structured and scalable misinformation generation. In this paper, we propose a novel approach that leverages knowledge graphs (KGs) as structured semantic resources to systematically generate fake triplets. By analyzing the structural properties of KGs, such as the distance between entities and their predicates, we identify plausibly false relationships. These triplets are then used to guide large language models (LLMs) in generating misinformation statements with varying degrees of credibility. By utilizing structured semantic relationships, our deterministic approach produces misinformation inherently challenging for humans to detect, drawing exclusively upon publicly available KGs (e.g., WikiGraphs). Additionally, we investigate the effectiveness of LLMs in distinguishing between genuine and artificially generated misinformation. Our analysis highlights significant limitations in current LLM-based detection methods, underscoring the necessity for enhanced detection strategies and a deeper exploration of inherent biases in generative models.