 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePop909
Papers and Code
D3PIA: A Discrete Denoising Diffusion Model for Piano Accompaniment Generation From Lead sheet
Feb 03, 2026Generating piano accompaniments in the symbolic music domain is a challenging task that requires producing a complete piece of piano music from given melody and chord constraints, such as those provided by a lead sheet. In this paper, we propose a discrete diffusion-based piano accompaniment generation model, D3PIA, leveraging local alignment between lead sheet and accompaniment in piano-roll representation. D3PIA incorporates Neighborhood Attention (NA) to both encode the lead sheet and condition it for predicting note states in the piano accompaniment. This design enhances local contextual modeling by efficiently attending to nearby melody and chord conditions. We evaluate our model using the POP909 dataset, a widely used benchmark for piano accompaniment generation. Objective evaluation results demonstrate that D3PIA preserves chord conditions more faithfully compared to continuous diffusion-based and Transformer-based baselines. Furthermore, a subjective listening test indicates that D3PIA generates more musically coherent accompaniments than the comparison models.
Music102: An $D_{12}$-equivariant transformer for chord progression accompaniment
Oct 23, 2024



We present Music102, an advanced model built upon the Music101 prototype, aimed at enhancing chord progression accompaniment through a D12-equivariant transformer. Inspired by group theory and symbolic music structures, Music102 leverages musical symmetry--such as transposition and reflection operations--integrating these properties into the transformer architecture. By encoding prior music knowledge, the model maintains equivariance across both melody and chord sequences. The POP909 dataset was employed to train and evaluate Music102, revealing significant improvements over Music101 in both weighted loss and exact accuracy metrics, despite using fewer parameters. This work showcases the adaptability of self-attention mechanisms and layer normalization to the discrete musical domain, addressing challenges in computational music analysis. With its stable and flexible neural framework, Music102 sets the stage for further exploration in equivariant music generation and computational composition tools, bridging mathematical theory with practical music performance.
MeloTrans: A Text to Symbolic Music Generation Model Following Human Composition Habit
Oct 17, 2024



At present, neural network models show powerful sequence prediction ability and are used in many automatic composition models. In comparison, the way humans compose music is very different from it. Composers usually start by creating musical motifs and then develop them into music through a series of rules. This process ensures that the music has a specific structure and changing pattern. However, it is difficult for neural network models to learn these composition rules from training data, which results in a lack of musicality and diversity in the generated music. This paper posits that integrating the learning capabilities of neural networks with human-derived knowledge may lead to better results. To archive this, we develop the POP909$\_$M dataset, the first to include labels for musical motifs and their variants, providing a basis for mimicking human compositional habits. Building on this, we propose MeloTrans, a text-to-music composition model that employs principles of motif development rules. Our experiments demonstrate that MeloTrans excels beyond existing music generation models and even surpasses Large Language Models (LLMs) like ChatGPT-4. This highlights the importance of merging human insights with neural network capabilities to achieve superior symbolic music generation.
Generating High-quality Symbolic Music Using Fine-grained Discriminators
Aug 03, 2024



Existing symbolic music generation methods usually utilize discriminator to improve the quality of generated music via global perception of music. However, considering the complexity of information in music, such as rhythm and melody, a single discriminator cannot fully reflect the differences in these two primary dimensions of music. In this work, we propose to decouple the melody and rhythm from music, and design corresponding fine-grained discriminators to tackle the aforementioned issues. Specifically, equipped with a pitch augmentation strategy, the melody discriminator discerns the melody variations presented by the generated samples. By contrast, the rhythm discriminator, enhanced with bar-level relative positional encoding, focuses on the velocity of generated notes. Such a design allows the generator to be more explicitly aware of which aspects should be adjusted in the generated music, making it easier to mimic human-composed music. Experimental results on the POP909 benchmark demonstrate the favorable performance of the proposed method compared to several state-of-the-art methods in terms of both objective and subjective metrics.
Controllable deep melody generation via hierarchical music structure representation
Sep 02, 2021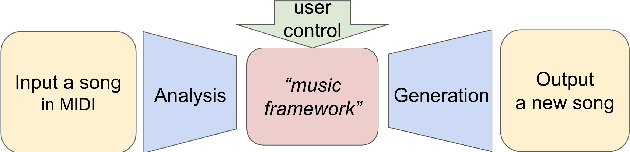
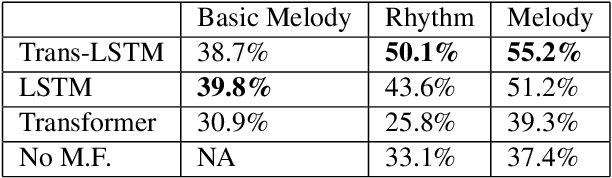
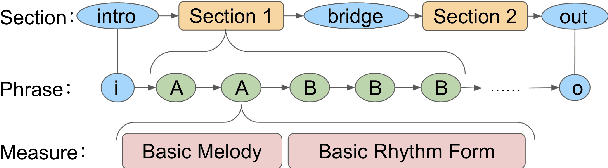
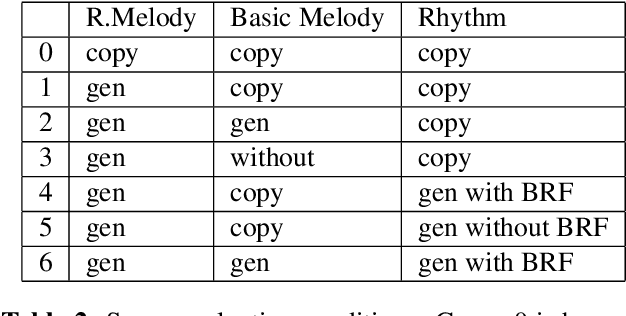
Recent advances in deep learning have expanded possibilities to generate music, but generating a customizable full piece of music with consistent long-term structure remains a challenge. This paper introduces MusicFrameworks, a hierarchical music structure representation and a multi-step generative process to create a full-length melody guided by long-term repetitive structure, chord, melodic contour, and rhythm constraints. We first organize the full melody with section and phrase-level structure. To generate melody in each phrase, we generate rhythm and basic melody using two separate transformer-based networks, and then generate the melody conditioned on the basic melody, rhythm and chords in an auto-regressive manner. By factoring music generation into sub-problems, our approach allows simpler models and requires less data. To customize or add variety, one can alter chords, basic melody, and rhythm structure in the music frameworks, letting our networks generate the melody accordingly. Additionally, we introduce new features to encode musical positional information, rhythm patterns, and melodic contours based on musical domain knowledge. A listening test reveals that melodies generated by our method are rated as good as or better than human-composed music in the POP909 dataset about half the time.
POP909: A Pop-song Dataset for Music Arrangement Generation
Aug 17, 2020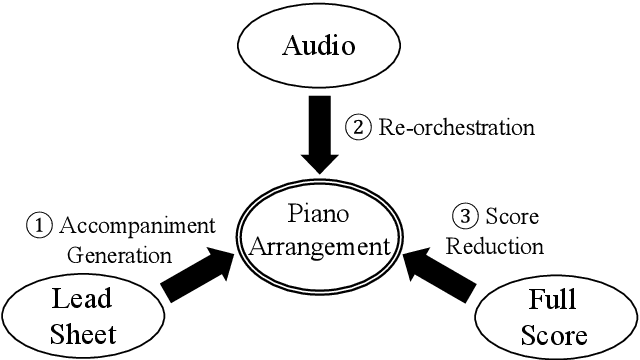
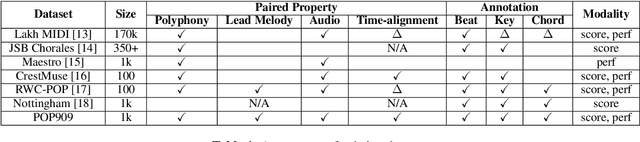
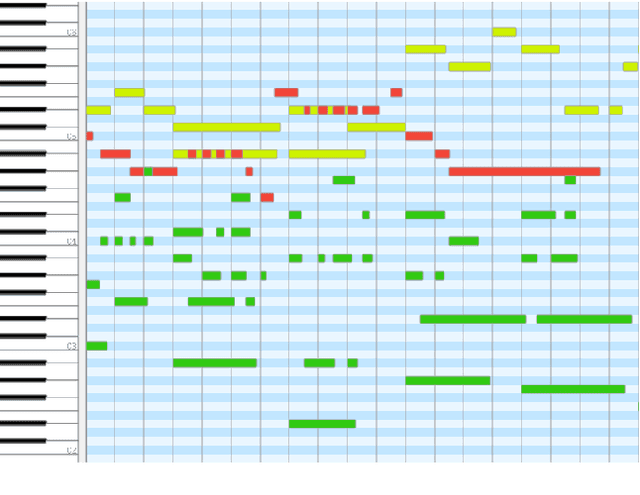
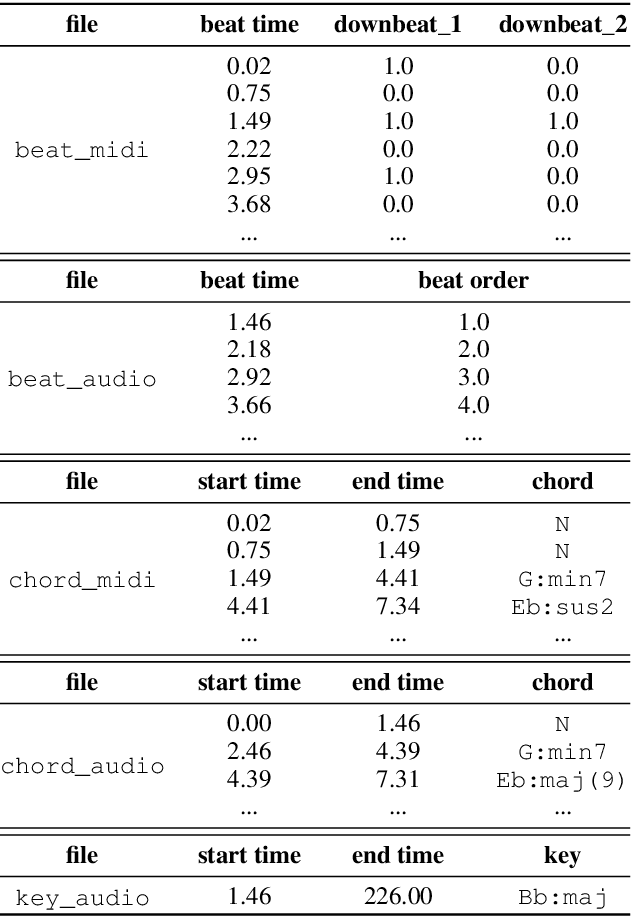
Music arrangement generation is a subtask of automatic music generation, which involves reconstructing and re-conceptualizing a piece with new compositional techniques. Such a generation process inevitably requires reference from the original melody, chord progression, or other structural information. Despite some promising models for arrangement, they lack more refined data to achieve better evaluations and more practical results. In this paper, we propose POP909, a dataset which contains multiple versions of the piano arrangements of 909 popular songs created by professional musicians. The main body of the dataset contains the vocal melody, the lead instrument melody, and the piano accompaniment for each song in MIDI format, which are aligned to the original audio files. Furthermore, we provide the annotations of tempo, beat, key, and chords, where the tempo curves are hand-labeled and others are done by MIR algorithms. Finally, we conduct several baseline experiments with this dataset using standard deep music generation algorithms.