 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoenix14t
Papers and Code
M3T: Discrete Multi-Modal Motion Tokens for Sign Language Production
Mar 24, 2026Sign language production requires more than hand motion generation. Non-manual features, including mouthings, eyebrow raises, gaze, and head movements, are grammatically obligatory and cannot be recovered from manual articulators alone. Existing 3D production systems face two barriers to integrating them: the standard body model provides a facial space too low-dimensional to encode these articulations, and when richer representations are adopted, standard discrete tokenization suffers from codebook collapse, leaving most of the expression space unreachable. We propose SMPL-FX, which couples FLAME's rich expression space with the SMPL-X body, and tokenize the resulting representation with modality-specific Finite Scalar Quantization VAEs for body, hands, and face. M3T is an autoregressive transformer trained on this multi-modal motion vocabulary, with an auxiliary translation objective that encourages semantically grounded embeddings. Across three standard benchmarks (How2Sign, CSL-Daily, Phoenix14T) M3T achieves state-of-the-art sign language production quality, and on NMFs-CSL, where signs are distinguishable only by non-manual features, reaches 58.3% accuracy against 49.0% for the strongest comparable pose baseline.
EASLT: Emotion-Aware Sign Language Translation
Jan 07, 2026Sign Language Translation (SLT) is a complex cross-modal task requiring the integration of Manual Signals (MS) and Non-Manual Signals (NMS). While recent gloss-free SLT methods have made strides in translating manual gestures, they frequently overlook the semantic criticality of facial expressions, resulting in ambiguity when distinct concepts share identical manual articulations. To address this, we present **EASLT** (**E**motion-**A**ware **S**ign **L**anguage **T**ranslation), a framework that treats facial affect not as auxiliary information, but as a robust semantic anchor. Unlike methods that relegate facial expressions to a secondary role, EASLT incorporates a dedicated emotional encoder to capture continuous affective dynamics. These representations are integrated via a novel *Emotion-Aware Fusion* (EAF) module, which adaptively recalibrates spatio-temporal sign features based on affective context to resolve semantic ambiguities. Extensive evaluations on the PHOENIX14T and CSL-Daily benchmarks demonstrate that EASLT establishes advanced performance among gloss-free methods, achieving BLEU-4 scores of 26.15 and 22.80, and BLEURT scores of 61.0 and 57.8, respectively. Ablation studies confirm that explicitly modeling emotion effectively decouples affective semantics from manual dynamics, significantly enhancing translation fidelity. Code is available at https://github.com/TuGuobin/EASLT.
USTM: Unified Spatial and Temporal Modeling for Continuous Sign Language Recognition
Dec 15, 2025Continuous sign language recognition (CSLR) requires precise spatio-temporal modeling to accurately recognize sequences of gestures in videos. Existing frameworks often rely on CNN-based spatial backbones combined with temporal convolution or recurrent modules. These techniques fail in capturing fine-grained hand and facial cues and modeling long-range temporal dependencies. To address these limitations, we propose the Unified Spatio-Temporal Modeling (USTM) framework, a spatio-temporal encoder that effectively models complex patterns using a combination of a Swin Transformer backbone enhanced with lightweight temporal adapter with positional embeddings (TAPE). Our framework captures fine-grained spatial features alongside short and long-term temporal context, enabling robust sign language recognition from RGB videos without relying on multi-stream inputs or auxiliary modalities. Extensive experiments on benchmarked datasets including PHOENIX14, PHOENIX14T, and CSL-Daily demonstrate that USTM achieves state-of-the-art performance against RGB-based as well as multi-modal CSLR approaches, while maintaining competitive performance against multi-stream approaches. These results highlight the strength and efficacy of the USTM framework for CSLR. The code is available at https://github.com/gufranSabri/USTM
Towards Skeletal and Signer Noise Reduction in Sign Language Production via Quaternion-Based Pose Encoding and Contrastive Learning
Aug 20, 2025One of the main challenges in neural sign language production (SLP) lies in the high intra-class variability of signs, arising from signer morphology and stylistic variety in the training data. To improve robustness to such variations, we propose two enhancements to the standard Progressive Transformers (PT) architecture (Saunders et al., 2020). First, we encode poses using bone rotations in quaternion space and train with a geodesic loss to improve the accuracy and clarity of angular joint movements. Second, we introduce a contrastive loss to structure decoder embeddings by semantic similarity, using either gloss overlap or SBERT-based sentence similarity, aiming to filter out anatomical and stylistic features that do not convey relevant semantic information. On the Phoenix14T dataset, the contrastive loss alone yields a 16% improvement in Probability of Correct Keypoint over the PT baseline. When combined with quaternion-based pose encoding, the model achieves a 6% reduction in Mean Bone Angle Error. These results point to the benefit of incorporating skeletal structure modeling and semantically guided contrastive objectives on sign pose representations into the training of Transformer-based SLP models.
Beyond Gloss: A Hand-Centric Framework for Gloss-Free Sign Language Translation
Jul 31, 2025Sign Language Translation (SLT) is a challenging task that requires bridging the modality gap between visual and linguistic information while capturing subtle variations in hand shapes and movements. To address these challenges, we introduce \textbf{BeyondGloss}, a novel gloss-free SLT framework that leverages the spatio-temporal reasoning capabilities of Video Large Language Models (VideoLLMs). Since existing VideoLLMs struggle to model long videos in detail, we propose a novel approach to generate fine-grained, temporally-aware textual descriptions of hand motion. A contrastive alignment module aligns these descriptions with video features during pre-training, encouraging the model to focus on hand-centric temporal dynamics and distinguish signs more effectively. To further enrich hand-specific representations, we distill fine-grained features from HaMeR. Additionally, we apply a contrastive loss between sign video representations and target language embeddings to reduce the modality gap in pre-training. \textbf{BeyondGloss} achieves state-of-the-art performance on the Phoenix14T and CSL-Daily benchmarks, demonstrating the effectiveness of the proposed framework. We will release the code upon acceptance of the paper.
StgcDiff: Spatial-Temporal Graph Condition Diffusion for Sign Language Transition Generation
Jun 16, 2025Sign language transition generation seeks to convert discrete sign language segments into continuous sign videos by synthesizing smooth transitions. However,most existing methods merely concatenate isolated signs, resulting in poor visual coherence and semantic accuracy in the generated videos. Unlike textual languages,sign language is inherently rich in spatial-temporal cues, making it more complex to model. To address this,we propose StgcDiff, a graph-based conditional diffusion framework that generates smooth transitions between discrete signs by capturing the unique spatial-temporal dependencies of sign language. Specifically, we first train an encoder-decoder architecture to learn a structure-aware representation of spatial-temporal skeleton sequences. Next, we optimize a diffusion denoiser conditioned on the representations learned by the pre-trained encoder, which is tasked with predicting transition frames from noise. Additionally, we design the Sign-GCN module as the key component in our framework, which effectively models the spatial-temporal features. Extensive experiments conducted on the PHOENIX14T, USTC-CSL100,and USTC-SLR500 datasets demonstrate the superior performance of our method.
SignAligner: Harmonizing Complementary Pose Modalities for Coherent Sign Language Generation
Jun 13, 2025Sign language generation aims to produce diverse sign representations based on spoken language. However, achieving realistic and naturalistic generation remains a significant challenge due to the complexity of sign language, which encompasses intricate hand gestures, facial expressions, and body movements. In this work, we introduce PHOENIX14T+, an extended version of the widely-used RWTH-PHOENIX-Weather 2014T dataset, featuring three new sign representations: Pose, Hamer and Smplerx. We also propose a novel method, SignAligner, for realistic sign language generation, consisting of three stages: text-driven pose modalities co-generation, online collaborative correction of multimodality, and realistic sign video synthesis. First, by incorporating text semantics, we design a joint sign language generator to simultaneously produce posture coordinates, gesture actions, and body movements. The text encoder, based on a Transformer architecture, extracts semantic features, while a cross-modal attention mechanism integrates these features to generate diverse sign language representations, ensuring accurate mapping and controlling the diversity of modal features. Next, online collaborative correction is introduced to refine the generated pose modalities using a dynamic loss weighting strategy and cross-modal attention, facilitating the complementarity of information across modalities, eliminating spatiotemporal conflicts, and ensuring semantic coherence and action consistency. Finally, the corrected pose modalities are fed into a pre-trained video generation network to produce high-fidelity sign language videos. Extensive experiments demonstrate that SignAligner significantly improves both the accuracy and expressiveness of the generated sign videos.
Multilingual Gloss-free Sign Language Translation: Towards Building a Sign Language Foundation Model
May 30, 2025Sign Language Translation (SLT) aims to convert sign language (SL) videos into spoken language text, thereby bridging the communication gap between the sign and the spoken community. While most existing works focus on translating a single sign language into a single spoken language (one-to-one SLT), leveraging multilingual resources could mitigate low-resource issues and enhance accessibility. However, multilingual SLT (MLSLT) remains unexplored due to language conflicts and alignment difficulties across SLs and spoken languages. To address these challenges, we propose a multilingual gloss-free model with dual CTC objectives for token-level SL identification and spoken text generation. Our model supports 10 SLs and handles one-to-one, many-to-one, and many-to-many SLT tasks, achieving competitive performance compared to state-of-the-art methods on three widely adopted benchmarks: multilingual SP-10, PHOENIX14T, and CSL-Daily.
ADAT: Time-Series-Aware Adaptive Transformer Architecture for Sign Language Translation
Apr 16, 2025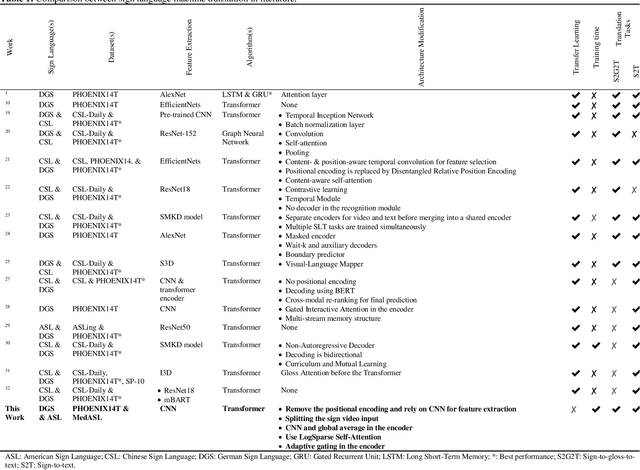



Current sign language machine translation systems rely on recognizing hand movements, facial expressions and body postures, and natural language processing, to convert signs into text. Recent approaches use Transformer architectures to model long-range dependencies via positional encoding. However, they lack accuracy in recognizing fine-grained, short-range temporal dependencies between gestures captured at high frame rates. Moreover, their high computational complexity leads to inefficient training. To mitigate these issues, we propose an Adaptive Transformer (ADAT), which incorporates components for enhanced feature extraction and adaptive feature weighting through a gating mechanism to emphasize contextually relevant features while reducing training overhead and maintaining translation accuracy. To evaluate ADAT, we introduce MedASL, the first public medical American Sign Language dataset. In sign-to-gloss-to-text experiments, ADAT outperforms the encoder-decoder transformer, improving BLEU-4 accuracy by 0.1% while reducing training time by 14.33% on PHOENIX14T and 3.24% on MedASL. In sign-to-text experiments, it improves accuracy by 8.7% and reduces training time by 2.8% on PHOENIX14T and achieves 4.7% higher accuracy and 7.17% faster training on MedASL. Compared to encoder-only and decoder-only baselines in sign-to-text, ADAT is at least 6.8% more accurate despite being up to 12.1% slower due to its dual-stream structure.
Disentangle and Regularize: Sign Language Production with Articulator-Based Disentanglement and Channel-Aware Regularization
Apr 09, 2025



In this work, we propose a simple gloss-free, transformer-based sign language production (SLP) framework that directly maps spoken-language text to sign pose sequences. We first train a pose autoencoder that encodes sign poses into a compact latent space using an articulator-based disentanglement strategy, where features corresponding to the face, right hand, left hand, and body are modeled separately to promote structured and interpretable representation learning. Next, a non-autoregressive transformer decoder is trained to predict these latent representations from sentence-level text embeddings. To guide this process, we apply channel-aware regularization by aligning predicted latent distributions with priors extracted from the ground-truth encodings using a KL-divergence loss. The contribution of each channel to the loss is weighted according to its associated articulator region, enabling the model to account for the relative importance of different articulators during training. Our approach does not rely on gloss supervision or pretrained models, and achieves state-of-the-art results on the PHOENIX14T dataset using only a modest training set.