 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModnet
Papers and Code
Modem Optimization of High-Mobility Scenarios: A Deep-Learning-Inspired Approach
Mar 21, 2024



The next generation wireless communication networks are required to support high-mobility scenarios, such as reliable data transmission for high-speed railways. Nevertheless, widely utilized multi-carrier modulation, the orthogonal frequency division multiplex (OFDM), cannot deal with the severe Doppler spread brought by high mobility. To address this problem, some new modulation schemes, e.g. orthogonal time frequency space and affine frequency division multiplexing, have been proposed with different design criteria from OFDM, which promote reliability with the cost of extremely high implementation complexity. On the other hand, end-to-end systems achieve excellent gains by exploiting neural networks to replace traditional transmitters and receivers, but have to retrain and update continually with channel varying. In this paper, we propose the Modem Network (ModNet) to design a novel modem scheme. Compared with end-to-end systems, channels are directly fed into the network and we can directly get a modem scheme through ModNet. Then, the Tri-Phase training strategy is proposed, which mainly utilizes the siamese structure to unify the learned modem scheme without retraining frequently faced up with time-varying channels. Simulation results show the proposed modem scheme outperforms OFDM systems under different highmobility channel statistics.
MODNet: Multi-offset Point Cloud Denoising Network Customized for Multi-scale Patches
Sep 01, 2022
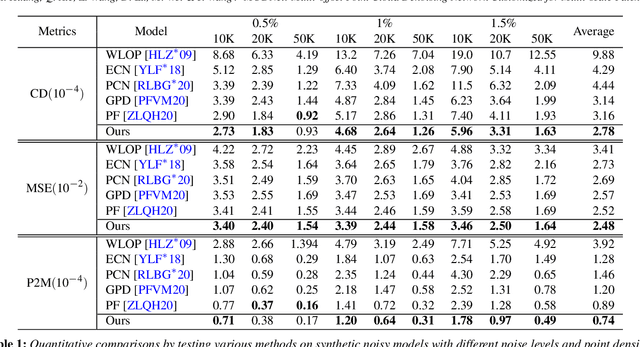
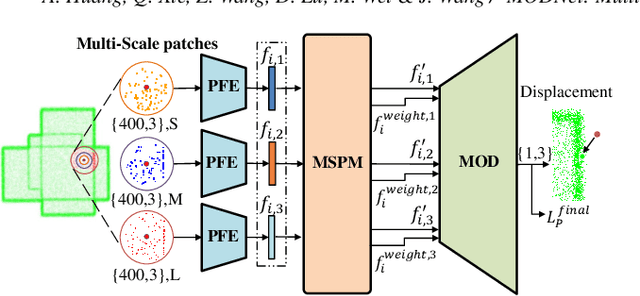
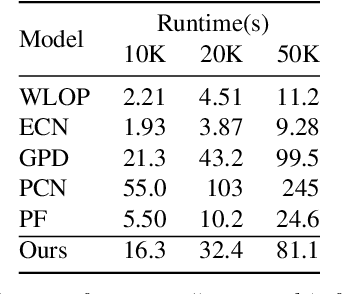
The intricacy of 3D surfaces often results cutting-edge point cloud denoising (PCD) models in surface degradation including remnant noise, wrongly-removed geometric details. Although using multi-scale patches to encode the geometry of a point has become the common wisdom in PCD, we find that simple aggregation of extracted multi-scale features can not adaptively utilize the appropriate scale information according to the geometric information around noisy points. It leads to surface degradation, especially for points close to edges and points on complex curved surfaces. We raise an intriguing question -- if employing multi-scale geometric perception information to guide the network to utilize multi-scale information, can eliminate the severe surface degradation problem? To answer it, we propose a Multi-offset Denoising Network (MODNet) customized for multi-scale patches. First, we extract the low-level feature of three scales patches by patch feature encoders. Second, a multi-scale perception module is designed to embed multi-scale geometric information for each scale feature and regress multi-scale weights to guide a multi-offset denoising displacement. Third, a multi-offset decoder regresses three scale offsets, which are guided by the multi-scale weights to predict the final displacement by weighting them adaptively. Experiments demonstrate that our method achieves new state-of-the-art performance on both synthetic and real-scanned datasets.
SGM-Net: Semantic Guided Matting Net
Aug 16, 2022
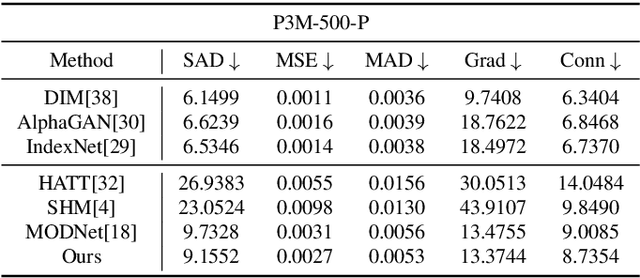
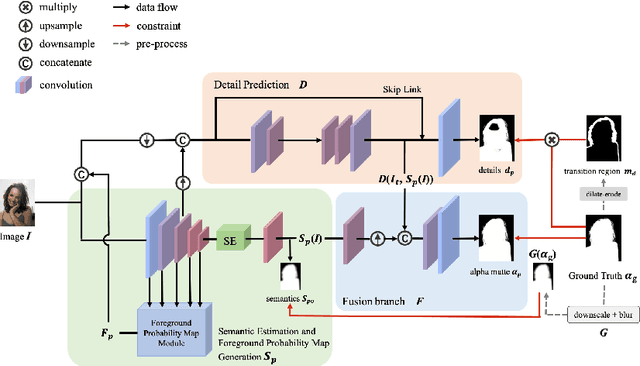
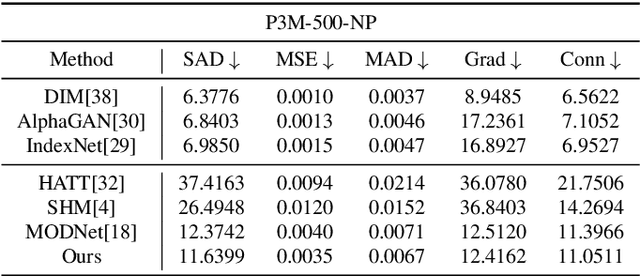
Human matting refers to extracting human parts from natural images with high quality, including human detail information such as hair, glasses, hat, etc. This technology plays an essential role in image synthesis and visual effects in the film industry. When the green screen is not available, the existing human matting methods need the help of additional inputs (such as trimap, background image, etc.), or the model with high computational cost and complex network structure, which brings great difficulties to the application of human matting in practice. To alleviate such problems, most existing methods (such as MODNet) use multi-branches to pave the way for matting through segmentation, but these methods do not make full use of the image features and only utilize the prediction results of the network as guidance information. Therefore, we propose a module to generate foreground probability map and add it to MODNet to obtain Semantic Guided Matting Net (SGM-Net). Under the condition of only one image, we can realize the human matting task. We verify our method on the P3M-10k dataset. Compared with the benchmark, our method has significantly improved in various evaluation indicators.
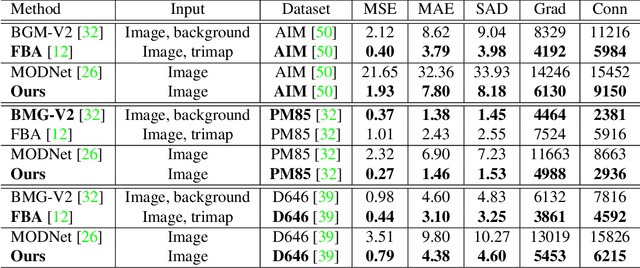
MODNet-V: Improving Portrait Video Matting via Background Restoration
Sep 24, 2021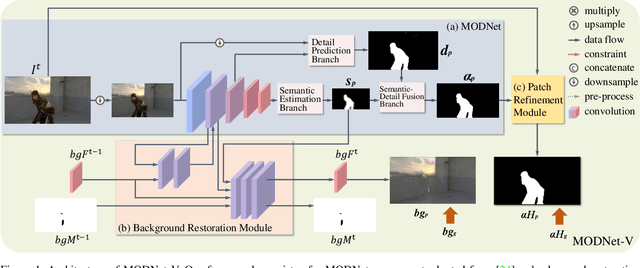

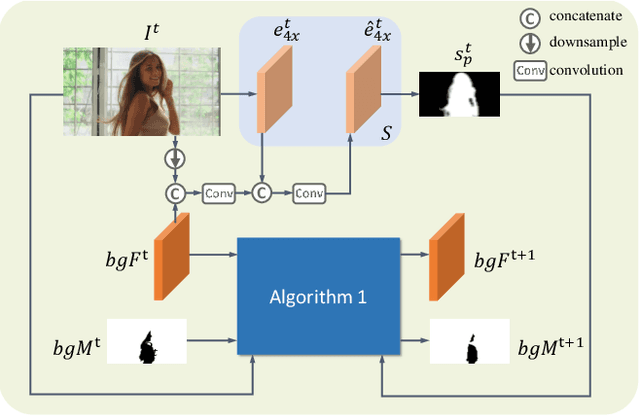
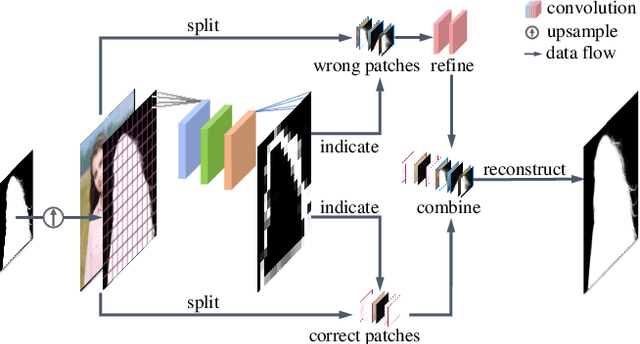
To address the challenging portrait video matting problem more precisely, existing works typically apply some matting priors that require additional user efforts to obtain, such as annotated trimaps or background images. In this work, we observe that instead of asking the user to explicitly provide a background image, we may recover it from the input video itself. To this end, we first propose a novel background restoration module (BRM) to recover the background image dynamically from the input video. BRM is extremely lightweight and can be easily integrated into existing matting models. By combining BRM with a recent image matting model, MODNet, we then present MODNet-V for portrait video matting. Benefited from the strong background prior provided by BRM, MODNet-V has only 1/3 of the parameters of MODNet but achieves comparable or even better performances. Our design allows MODNet-V to be trained in an end-to-end manner on a single NVIDIA 3090 GPU. Finally, we introduce a new patch refinement module (PRM) to adapt MODNet-V for high-resolution videos while keeping MODNet-V lightweight and fast.
BEV-MODNet: Monocular Camera based Bird's Eye View Moving Object Detection for Autonomous Driving
Jul 11, 2021



Detection of moving objects is a very important task in autonomous driving systems. After the perception phase, motion planning is typically performed in Bird's Eye View (BEV) space. This would require projection of objects detected on the image plane to top view BEV plane. Such a projection is prone to errors due to lack of depth information and noisy mapping in far away areas. CNNs can leverage the global context in the scene to project better. In this work, we explore end-to-end Moving Object Detection (MOD) on the BEV map directly using monocular images as input. To the best of our knowledge, such a dataset does not exist and we create an extended KITTI-raw dataset consisting of 12.9k images with annotations of moving object masks in BEV space for five classes. The dataset is intended to be used for class agnostic motion cue based object detection and classes are provided as meta-data for better tuning. We design and implement a two-stream RGB and optical flow fusion architecture which outputs motion segmentation directly in BEV space. We compare it with inverse perspective mapping of state-of-the-art motion segmentation predictions on the image plane. We observe a significant improvement of 13% in mIoU using the simple baseline implementation. This demonstrates the ability to directly learn motion segmentation output in BEV space. Qualitative results of our baseline and the dataset annotations can be found in https://sites.google.com/view/bev-modnet.
Alpha Matte Generation from Single Input for Portrait Matting
Jun 14, 2021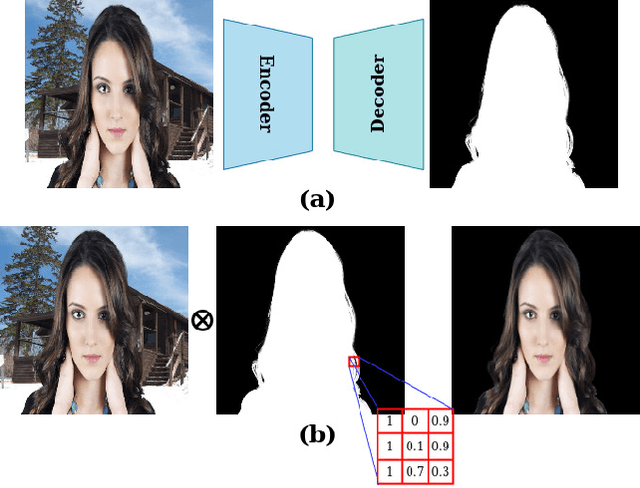
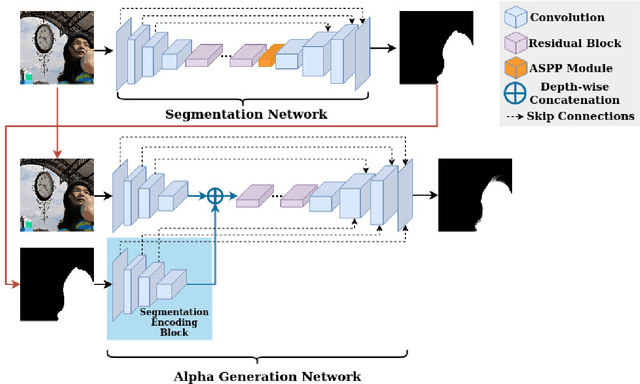
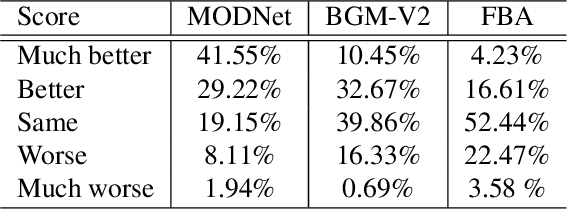
Portrait matting is an important research problem with a wide range of applications, such as video conference app, image/video editing, and post-production. The goal is to predict an alpha matte that identifies the effect of each pixel on the foreground subject. Traditional approaches and most of the existing works utilized an additional input, e.g., trimap, background image, to predict alpha matte. However, providing additional input is not always practical. Besides, models are too sensitive to these additional inputs. In this paper, we introduce an additional input-free approach to perform portrait matting using Generative Adversarial Nets (GANs). We divide the main task into two subtasks. For this, we propose a segmentation network for the person segmentation and the alpha generation network for alpha matte prediction. While the segmentation network takes an input image and produces a coarse segmentation map, the alpha generation network utilizes the same input image as well as a coarse segmentation map that is produced by the segmentation network to predict the alpha matte. Besides, we present a segmentation encoding block to downsample the coarse segmentation map and provide feature representation to the residual block. Furthermore, we propose border loss to penalize only the borders of the subject separately which is more likely to be challenging and we also adapt perceptual loss for portrait matting. To train the proposed system, we combine two different popular training datasets to improve the amount of data as well as diversity to address domain shift problems in the inference time. We tested our model on three different benchmark datasets, namely Adobe Image Matting dataset, Portrait Matting dataset, and Distinctions dataset. The proposed method outperformed the MODNet method that also takes a single input.
A Modulation Front-End for Music Audio Tagging
May 25, 2021
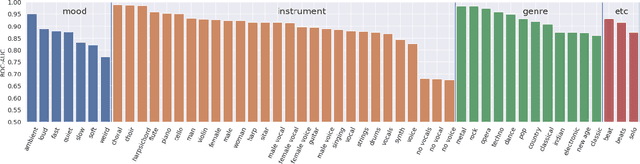
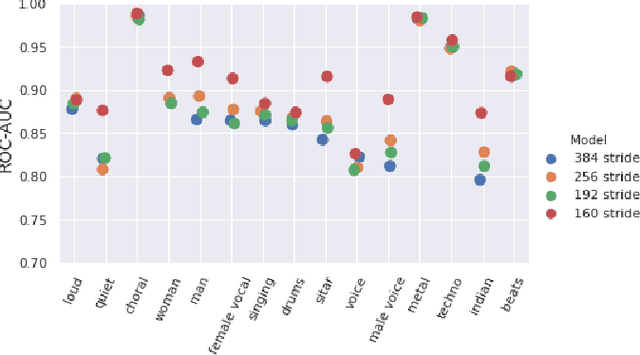
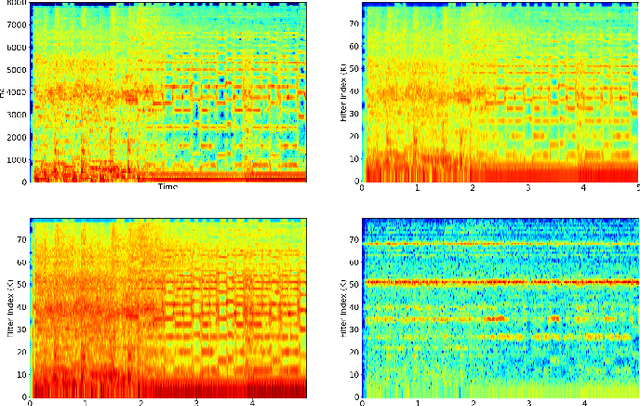
Convolutional Neural Networks have been extensively explored in the task of automatic music tagging. The problem can be approached by using either engineered time-frequency features or raw audio as input. Modulation filter bank representations that have been actively researched as a basis for timbre perception have the potential to facilitate the extraction of perceptually salient features. We explore end-to-end learned front-ends for audio representation learning, ModNet and SincModNet, that incorporate a temporal modulation processing block. The structure is effectively analogous to a modulation filter bank, where the FIR filter center frequencies are learned in a data-driven manner. The expectation is that a perceptually motivated filter bank can provide a useful representation for identifying music features. Our experimental results provide a fully visualisable and interpretable front-end temporal modulation decomposition of raw audio. We evaluate the performance of our model against the state-of-the-art of music tagging on the MagnaTagATune dataset. We analyse the impact on performance for particular tags when time-frequency bands are subsampled by the modulation filters at a progressively reduced rate. We demonstrate that modulation filtering provides promising results for music tagging and feature representation, without using extensive musical domain knowledge in the design of this front-end.
VM-MODNet: Vehicle Motion aware Moving Object Detection for Autonomous Driving
Apr 22, 2021



Moving object Detection (MOD) is a critical task in autonomous driving as moving agents around the ego-vehicle need to be accurately detected for safe trajectory planning. It also enables appearance agnostic detection of objects based on motion cues. There are geometric challenges like motion-parallax ambiguity which makes it a difficult problem. In this work, we aim to leverage the vehicle motion information and feed it into the model to have an adaptation mechanism based on ego-motion. The motivation is to enable the model to implicitly perform ego-motion compensation to improve performance. We convert the six degrees of freedom vehicle motion into a pixel-wise tensor which can be fed as input to the CNN model. The proposed model using Vehicle Motion Tensor (VMT) achieves an absolute improvement of 5.6% in mIoU over the baseline architecture. We also achieve state-of-the-art results on the public KITTI_MoSeg_Extended dataset even compared to methods which make use of LiDAR and additional input frames. Our model is also lightweight and runs at 85 fps on a TitanX GPU. Qualitative results are provided in https://youtu.be/ezbfjti-kTk.
Is a Green Screen Really Necessary for Real-Time Portrait Matting?
Nov 29, 2020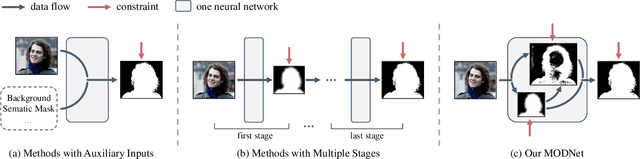
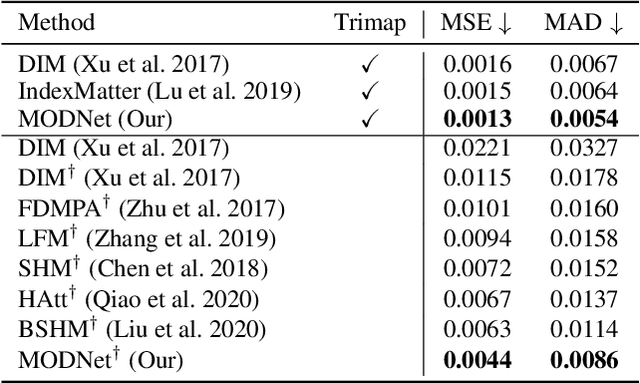
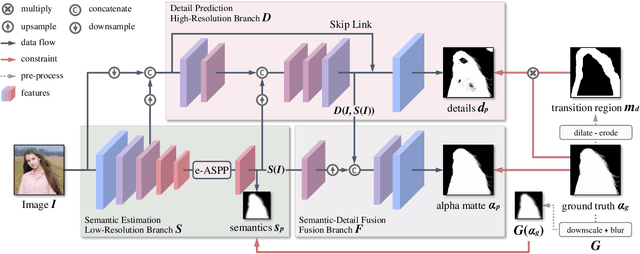
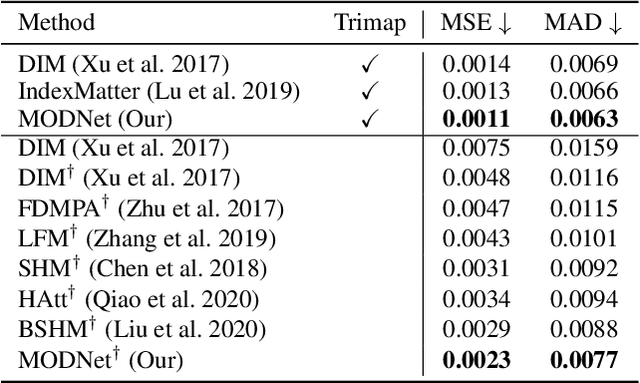
For portrait matting without the green screen, existing works either require auxiliary inputs that are costly to obtain or use multiple models that are computationally expensive. Consequently, they are unavailable in real-time applications. In contrast, we present a light-weight matting objective decomposition network (MODNet), which can process portrait matting from a single input image in real time. The design of MODNet benefits from optimizing a series of correlated sub-objectives simultaneously via explicit constraints. Moreover, since trimap-free methods usually suffer from the domain shift problem in practice, we introduce (1) a self-supervised strategy based on sub-objectives consistency to adapt MODNet to real-world data and (2) a one-frame delay trick to smooth the results when applying MODNet to portrait video sequence. MODNet is easy to be trained in an end-to-end style. It is much faster than contemporaneous matting methods and runs at 63 frames per second. On a carefully designed portrait matting benchmark newly proposed in this work, MODNet greatly outperforms prior trimap-free methods. More importantly, our method achieves remarkable results in daily photos and videos. Now, do you really need a green screen for real-time portrait matting?
RST-MODNet: Real-time Spatio-temporal Moving Object Detection for Autonomous Driving
Dec 01, 2019



Moving Object Detection (MOD) is a critical task for autonomous vehicles as moving objects represent higher collision risk than static ones. The trajectory of the ego-vehicle is planned based on the future states of detected moving objects. It is quite challenging as the ego-motion has to be modelled and compensated to be able to understand the motion of the surrounding objects. In this work, we propose a real-time end-to-end CNN architecture for MOD utilizing spatio-temporal context to improve robustness. We construct a novel time-aware architecture exploiting temporal motion information embedded within sequential images in addition to explicit motion maps using optical flow images.We demonstrate the impact of our algorithm on KITTI dataset where we obtain an improvement of 8% relative to the baselines. We compare our algorithm with state-of-the-art methods and achieve competitive results on KITTI-Motion dataset in terms of accuracy at three times better run-time. The proposed algorithm runs at 23 fps on a standard desktop GPU targeting deployment on embedded platforms.