 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetamerism
Papers and Code
Generating metamers of human scene understanding
Jan 16, 2026Human vision combines low-resolution "gist" information from the visual periphery with sparse but high-resolution information from fixated locations to construct a coherent understanding of a visual scene. In this paper, we introduce MetamerGen, a tool for generating scenes that are aligned with latent human scene representations. MetamerGen is a latent diffusion model that combines peripherally obtained scene gist information with information obtained from scene-viewing fixations to generate image metamers for what humans understand after viewing a scene. Generating images from both high and low resolution (i.e. "foveated") inputs constitutes a novel image-to-image synthesis problem, which we tackle by introducing a dual-stream representation of the foveated scenes consisting of DINOv2 tokens that fuse detailed features from fixated areas with peripherally degraded features capturing scene context. To evaluate the perceptual alignment of MetamerGen generated images to latent human scene representations, we conducted a same-different behavioral experiment where participants were asked for a "same" or "different" response between the generated and the original image. With that, we identify scene generations that are indeed metamers for the latent scene representations formed by the viewers. MetamerGen is a powerful tool for understanding scene understanding. Our proof-of-concept analyses uncovered specific features at multiple levels of visual processing that contributed to human judgments. While it can generate metamers even conditioned on random fixations, we find that high-level semantic alignment most strongly predicts metamerism when the generated scenes are conditioned on viewers' own fixated regions.
Optimization of DNN-based HSI Segmentation FPGA-based SoC for ADS: A Practical Approach
Jul 22, 2025The use of HSI for autonomous navigation is a promising research field aimed at improving the accuracy and robustness of detection, tracking, and scene understanding systems based on vision sensors. Combining advanced computer algorithms, such as DNNs, with small-size snapshot HSI cameras enhances the reliability of these systems. HSI overcomes intrinsic limitations of greyscale and RGB imaging in depicting physical properties of targets, particularly regarding spectral reflectance and metamerism. Despite promising results in HSI-based vision developments, safety-critical systems like ADS demand strict constraints on latency, resource consumption, and security, motivating the shift of ML workloads to edge platforms. This involves a thorough software/hardware co-design scheme to distribute and optimize the tasks efficiently among the limited resources of computing platforms. With respect to inference, the over-parameterized nature of DNNs poses significant computational challenges for real-time on-the-edge deployment. In addition, the intensive data preprocessing required by HSI, which is frequently overlooked, must be carefully managed in terms of memory arrangement and inter-task communication to enable an efficient integrated pipeline design on a SoC. This work presents a set of optimization techniques for the practical co-design of a DNN-based HSI segmentation processor deployed on a FPGA-based SoC targeted at ADS, including key optimizations such as functional software/hardware task distribution, hardware-aware preprocessing, ML model compression, and a complete pipelined deployment. Applied compression techniques significantly reduce the complexity of the designed DNN to 24.34% of the original operations and to 1.02% of the original number of parameters, achieving a 2.86x speed-up in the inference task without noticeable degradation of the segmentation accuracy.
MAME: Multidimensional Adaptive Metamer Exploration with Human Perceptual Feedback
Mar 17, 2025



Alignment between human brain networks and artificial models is actively studied in machine learning and neuroscience. A widely adopted approach to explore their functional alignment is to identify metamers for both humans and models. Metamers refer to input stimuli that are physically different but equivalent within a given system. If a model's metameric space completely matched the human metameric space, the model would achieve functional alignment with humans. However, conventional methods lack direct ways to search for human metamers. Instead, researchers first develop biologically inspired models and then infer about human metamers indirectly by testing whether model metamers also appear as metamers to humans. Here, we propose the Multidimensional Adaptive Metamer Exploration (MAME) framework, enabling direct high-dimensional exploration of human metameric space. MAME leverages online image generation guided by human perceptual feedback. Specifically, it modulates reference images across multiple dimensions by leveraging hierarchical responses from convolutional neural networks (CNNs). Generated images are presented to participants whose perceptual discriminability is assessed in a behavioral task. Based on participants' responses, subsequent image generation parameters are adaptively updated online. Using our MAME framework, we successfully measured a human metameric space of over fifty dimensions within a single experiment. Experimental results showed that human discrimination sensitivity was lower for metameric images based on low-level features compared to high-level features, which image contrast metrics could not explain. The finding suggests that the model computes low-level information not essential for human perception. Our framework has the potential to contribute to developing interpretable AI and understanding of brain function in neuroscience.
A spatiotemporal style transfer algorithm for dynamic visual stimulus generation
Mar 07, 2024



Understanding how visual information is encoded in biological and artificial systems often requires vision scientists to generate appropriate stimuli to test specific hypotheses. Although deep neural network models have revolutionized the field of image generation with methods such as image style transfer, available methods for video generation are scarce. Here, we introduce the Spatiotemporal Style Transfer (STST) algorithm, a dynamic visual stimulus generation framework that allows powerful manipulation and synthesis of video stimuli for vision research. It is based on a two-stream deep neural network model that factorizes spatial and temporal features to generate dynamic visual stimuli whose model layer activations are matched to those of input videos. As an example, we show that our algorithm enables the generation of model metamers, dynamic stimuli whose layer activations within our two-stream model are matched to those of natural videos. We show that these generated stimuli match the low-level spatiotemporal features of their natural counterparts but lack their high-level semantic features, making it a powerful paradigm to study object recognition. Late layer activations in deep vision models exhibited a lower similarity between natural and metameric stimuli compared to early layers, confirming the lack of high-level information in the generated stimuli. Finally, we use our generated stimuli to probe the representational capabilities of predictive coding deep networks. These results showcase potential applications of our algorithm as a versatile tool for dynamic stimulus generation in vision science.
Limitations of Data-Driven Spectral Reconstruction -- An Optics-Aware Analysis
Jan 08, 2024



Hyperspectral imaging empowers computer vision systems with the distinct capability of identifying materials through recording their spectral signatures. Recent efforts in data-driven spectral reconstruction aim at extracting spectral information from RGB images captured by cost-effective RGB cameras, instead of dedicated hardware. In this paper we systematically analyze the performance of such methods, evaluating both the practical limitations with respect to current datasets and overfitting, as well as fundamental limits with respect to the nature of the information encoded in the RGB images, and the dependency of this information on the optical system of the camera. We find that the current models are not robust under slight variations, e.g., in noise level or compression of the RGB file. Both the methods and the datasets are also limited in their ability to cope with metameric colors. This issue can in part be overcome with metameric data augmentation. Moreover, optical lens aberrations can help to improve the encoding of the metameric information into the RGB image, which paves the road towards higher performing spectral imaging and reconstruction approaches.
Dynamic models for Planar Peristaltic Locomotion of a Metameric Earthworm-like Robot
Mar 21, 2023



The development of versatile robots capable of traversing challenging and irregular environments is of increasing interest in the field of robotics, and metameric robots have been identified as a promising solution due to their slender, deformable bodies. Inspired by the effective locomotion of earthworms, earthworm-like robots capable of both rectilinear and planar locomotion have been designed and prototyped. While much research has focused on developing kinematic models to describe the planar locomotion of earthworm-like robots, the authors argue that the development of dynamic models is critical to improving the accuracy and efficiency of these robots. A comprehensive analysis of the dynamics of a metameric earthworm-like robot capable of planar motion is presented in this work. The model takes into account the complex interactions between the robot's deformable body and the forces acting on it and draws on the methods previously used to develop mathematical models of snake-like robots. The proposed model represents a significant advancement in the field of metameric robotics and has the potential to enhance the performance of earthworm-like robots in a variety of challenging environments, such as underground pipes and tunnels, and serves as a foundation for future research into the dynamics of soft-bodied robots.
Deep-learning-based on-chip rapid spectral imaging with high spatial resolution
Jan 16, 2023Spectral imaging extends the concept of traditional color cameras to capture images across multiple spectral channels and has broad application prospects. Conventional spectral cameras based on scanning methods suffer from low acquisition speed and large volume. On-chip computational spectral imaging based on metasurface filters provides a promising scheme for portable applications, but endures long computation time for point-by-point iterative spectral reconstruction and mosaic effect in the reconstructed spectral images. In this study, we demonstrated on-chip rapid spectral imaging eliminating the mosaic effect in the spectral image by deep-learning-based spectral data cube reconstruction. We experimentally achieved four orders of magnitude speed improvement than iterative spectral reconstruction and high fidelity of spectral reconstruction over 99% for a standard color board. In particular, we demonstrated video-rate spectral imaging for moving objects and outdoor driving scenes with good performance for recognizing metamerism, where the concolorous sky and white cars can be distinguished via their spectra, showing great potential for autonomous driving and other practical applications in the field of intelligent perception.
Finding Biological Plausibility for Adversarially Robust Features via Metameric Tasks
Feb 04, 2022
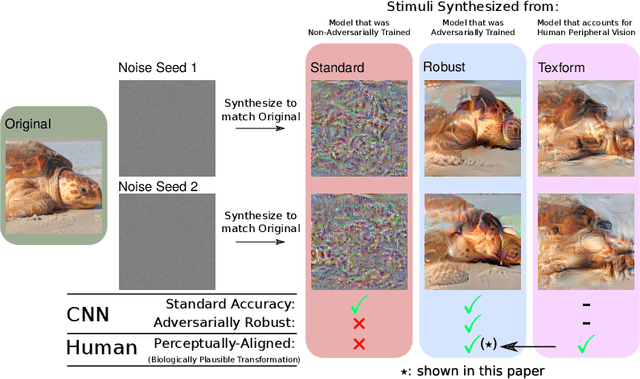
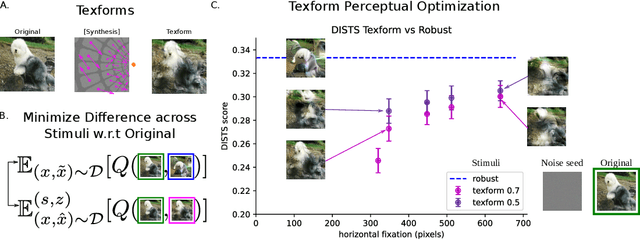
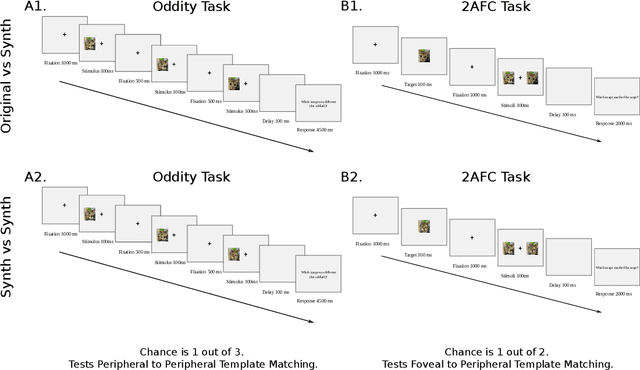
Recent work suggests that representations learned by adversarially robust networks are more human perceptually-aligned than non-robust networks via image manipulations. Despite appearing closer to human visual perception, it is unclear if the constraints in robust DNN representations match biological constraints found in human vision. Human vision seems to rely on texture-based/summary statistic representations in the periphery, which have been shown to explain phenomena such as crowding and performance on visual search tasks. To understand how adversarially robust optimizations/representations compare to human vision, we performed a psychophysics experiment using a set of metameric discrimination tasks where we evaluated how well human observers could distinguish between images synthesized to match adversarially robust representations compared to non-robust representations and a texture synthesis model of peripheral vision (Texforms). We found that the discriminability of robust representation and texture model images decreased to near chance performance as stimuli were presented farther in the periphery. Moreover, performance on robust and texture-model images showed similar trends within participants, while performance on non-robust representations changed minimally across the visual field. These results together suggest that (1) adversarially robust representations capture peripheral computation better than non-robust representations and (2) robust representations capture peripheral computation similar to current state-of-the-art texture peripheral vision models. More broadly, our findings support the idea that localized texture summary statistic representations may drive human invariance to adversarial perturbations and that the incorporation of such representations in DNNs could give rise to useful properties like adversarial robustness.
An Earthworm-Inspired Multi-Mode Underwater Locomotion Robot: Design, Modeling, and Experiments
Aug 12, 2021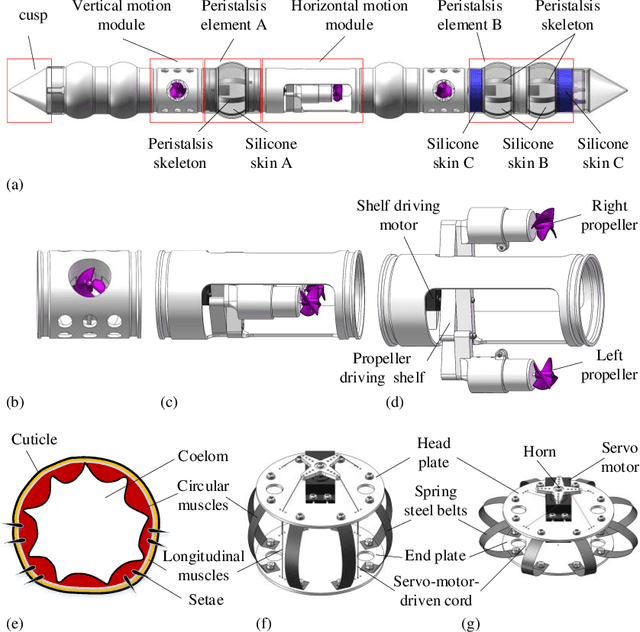
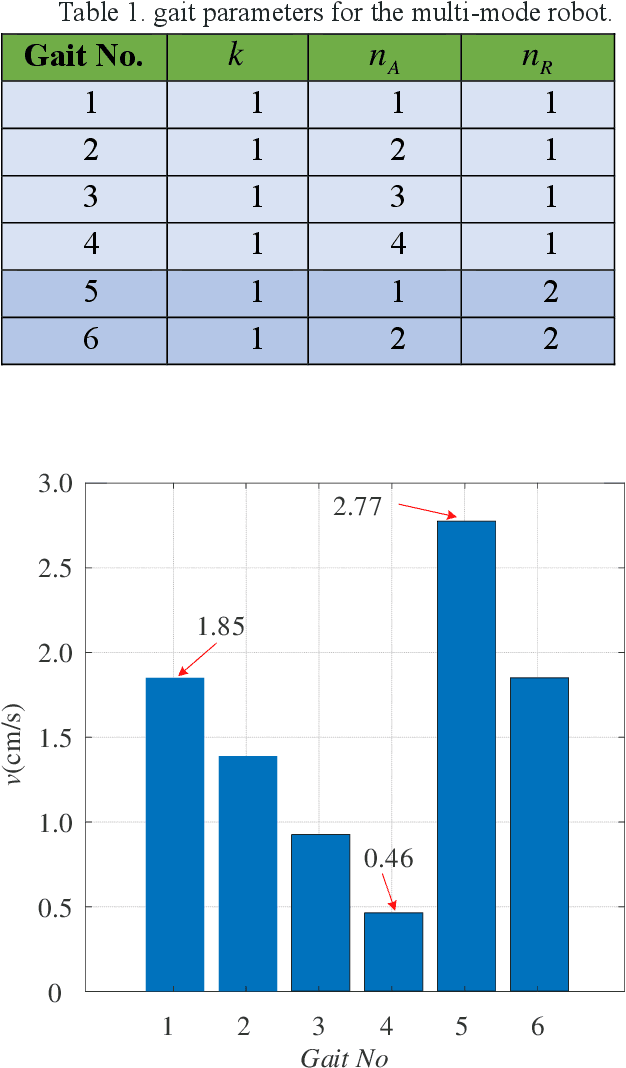
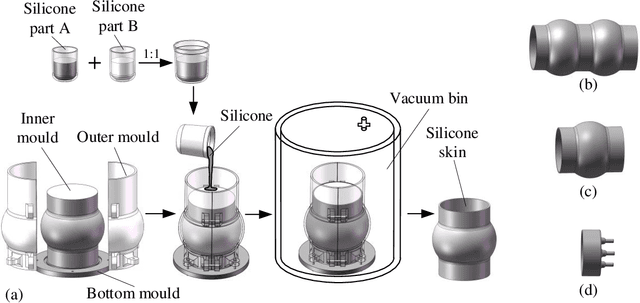
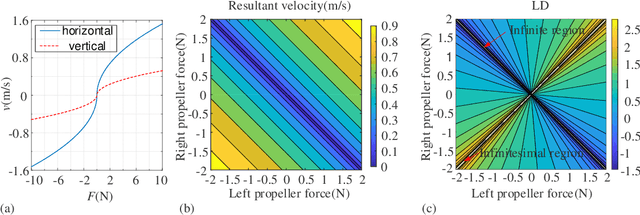
Faced with strong demand for robots working in underwater pipeline environments, a novel underwater multi-model locomotion robot is designed and studied in this research. By mimicking the earthworm's metameric body, the robot is segmented in the structure; by synthesizing the earthworm-like peristaltic locomotion mechanism and the propeller-driven swimming mechanism, the robot possesses unique multi-mode locomotion capability. In detail, the in-pipe earthworm-like peristaltic crawling is achieved based on servomotor-driven cords and pre-bent spring-steel belts that work antagonistically, and the three-dimensional underwater swimming is realized by four independently-controlled propellers. With a robot covering made of silicon rubber, the two locomotion modes are tested in the underwater environment, through which, the rationality and the effectiveness of the robot design are demonstrated. Aiming at predicting the robotic locomotion performance, mechanical models of the robot are further developed. For the underwater swimming mode, by considering the robot as a spheroid, an equivalent dynamic model is constructed, whose validity is verified via computational fluid dynamics (CFD) simulations; for the in-pipe crawling mode, a classical kinematics model is employed to predict the average locomotion speeds under different gait controls. The outcomes of this research could offer useful design and modeling guidelines for the development of earthworm-like locomotion robots with unique underwater multi-mode locomotion capability.
Polarimetric Spatio-Temporal Light Transport Probing
May 25, 2021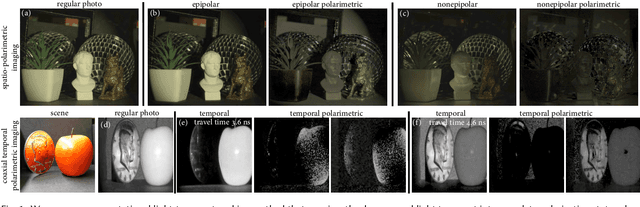
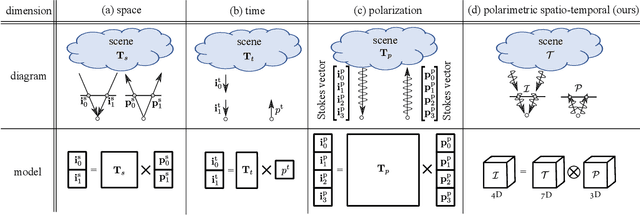

Light can undergo complex interactions with multiple scene surfaces of different material types before being reflected towards a detector. During this transport, every surface reflection and propagation is encoded in the properties of the photons that ultimately reach the detector, including travel time, direction, intensity, wavelength and polarization. Conventional imaging systems capture intensity by integrating over all other dimensions of the light into a single quantity, hiding this rich scene information in the accumulated measurements. Existing methods can untangle these into their spatial and temporal dimensions, fueling geometric scene understanding. However, examining polarimetric material properties jointly with geometric properties is an open challenge that could enable unprecedented capabilities beyond geometric understanding, allowing to incorporate material-dependent semantics. In this work, we propose a computational light-transport imaging method that captures the spatially- and temporally-resolved complete polarimetric response of a scene. Our method hinges on a novel 7D tensor theory of light transport. We discover low-rank structures in the polarimetric tensor dimension and propose a data-driven rotating ellipsometry method that learns to exploit redundancy of the polarimetric structures. We instantiate our theory in two imaging prototypes: spatio-polarimetric imaging and coaxial temporal-polarimetric imaging. This allows us to decompose scene light transport into temporal, spatial, and complete polarimetric dimensions that unveil scene properties hidden to conventional methods. We validate the applicability of our method on diverse tasks, including shape reconstruction with subsurface scattering, seeing through scattering medium, untangling multi-bounce light transport, breaking metamerism with polarization, and spatio-polarimetric decomposition of crystals.