 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKoniq 10k
Papers and Code
MS-SCANet: A Multiscale Transformer-Based Architecture with Dual Attention for No-Reference Image Quality Assessment
Feb 03, 2026We present the Multi-Scale Spatial Channel Attention Network (MS-SCANet), a transformer-based architecture designed for no-reference image quality assessment (IQA). MS-SCANet features a dual-branch structure that processes images at multiple scales, effectively capturing both fine and coarse details, an improvement over traditional single-scale methods. By integrating tailored spatial and channel attention mechanisms, our model emphasizes essential features while minimizing computational complexity. A key component of MS-SCANet is its cross-branch attention mechanism, which enhances the integration of features across different scales, addressing limitations in previous approaches. We also introduce two new consistency loss functions, Cross-Branch Consistency Loss and Adaptive Pooling Consistency Loss, which maintain spatial integrity during feature scaling, outperforming conventional linear and bilinear techniques. Extensive evaluations on datasets like KonIQ-10k, LIVE, LIVE Challenge, and CSIQ show that MS-SCANet consistently surpasses state-of-the-art methods, offering a robust framework with stronger correlations with subjective human scores.
* Published in ICASSP 2025, 5 pages, 3 figures
Parameter-Efficient Adaptation of mPLUG-Owl2 via Pixel-Level Visual Prompts for NR-IQA
Sep 03, 2025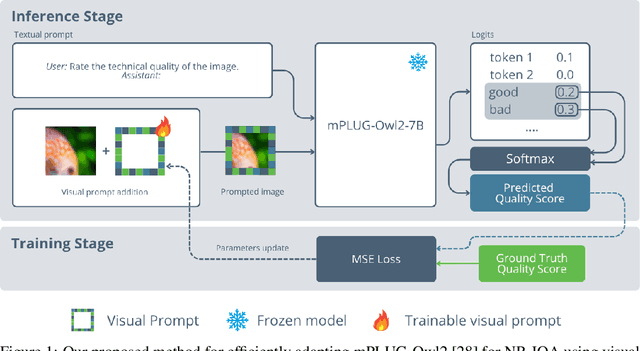


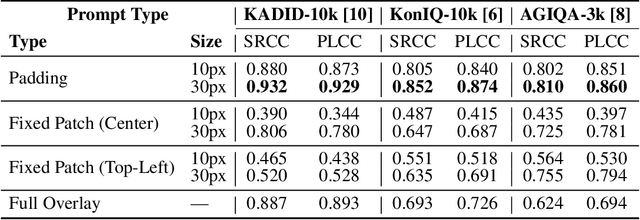
In this paper, we propose a novel parameter-efficient adaptation method for No- Reference Image Quality Assessment (NR-IQA) using visual prompts optimized in pixel-space. Unlike full fine-tuning of Multimodal Large Language Models (MLLMs), our approach trains only 600K parameters at most (< 0.01% of the base model), while keeping the underlying model fully frozen. During inference, these visual prompts are combined with images via addition and processed by mPLUG-Owl2 with the textual query "Rate the technical quality of the image." Evaluations across distortion types (synthetic, realistic, AI-generated) on KADID- 10k, KonIQ-10k, and AGIQA-3k demonstrate competitive performance against full finetuned methods and specialized NR-IQA models, achieving 0.93 SRCC on KADID-10k. To our knowledge, this is the first work to leverage pixel-space visual prompts for NR-IQA, enabling efficient MLLM adaptation for low-level vision tasks. The source code is publicly available at https: // github. com/ yahya-ben/ mplug2-vp-for-nriqa .
Maximum entropy and quantized metric models for absolute category ratings
Oct 01, 2024



The datasets of most image quality assessment studies contain ratings on a categorical scale with five levels, from bad (1) to excellent (5). For each stimulus, the number of ratings from 1 to 5 is summarized and given in the form of the mean opinion score. In this study, we investigate families of multinomial probability distributions parameterized by mean and variance that are used to fit the empirical rating distributions. To this end, we consider quantized metric models based on continuous distributions that model perceived stimulus quality on a latent scale. The probabilities for the rating categories are determined by quantizing the corresponding random variables using threshold values. Furthermore, we introduce a novel discrete maximum entropy distribution for a given mean and variance. We compare the performance of these models and the state of the art given by the generalized score distribution for two large data sets, KonIQ-10k and VQEG HDTV. Given an input distribution of ratings, our fitted two-parameter models predict unseen ratings better than the empirical distribution. In contrast to empirical ACR distributions and their discrete models, our continuous models can provide fine-grained estimates of quantiles of quality of experience that are relevant to service providers to satisfy a target fraction of the user population.
Exploring Kolmogorov-Arnold networks for realistic image sharpness assessment
Sep 12, 2024



Score prediction is crucial in realistic image sharpness assessment after informative features are collected. Recently, Kolmogorov-Arnold networks (KANs) have been developed and witnessed remarkable success in data fitting. This study presents Taylor series based KAN (TaylorKAN). Then, different KANs are explored on four realistic image databases (BID2011, CID2013, CLIVE, and KonIQ-10k) for score prediction by using 15 mid-level features and 2048 high-level features. When setting support vector regression as the baseline, experimental results indicate KANs are generally better or competitive, TaylorKAN is the best on three databases using mid-level feature input, while KANs are inferior on CLIVE when high-level features are used. This is the first study that explores KANs for image quality assessment. It sheds lights on how to select and improve KANs on related tasks.
JNDMix: JND-Based Data Augmentation for No-reference Image Quality Assessment
Feb 20, 2023



Despite substantial progress in no-reference image quality assessment (NR-IQA), previous training models often suffer from over-fitting due to the limited scale of used datasets, resulting in model performance bottlenecks. To tackle this challenge, we explore the potential of leveraging data augmentation to improve data efficiency and enhance model robustness. However, most existing data augmentation methods incur a serious issue, namely that it alters the image quality and leads to training images mismatching with their original labels. Additionally, although only a few data augmentation methods are available for NR-IQA task, their ability to enrich dataset diversity is still insufficient. To address these issues, we propose a effective and general data augmentation based on just noticeable difference (JND) noise mixing for NR-IQA task, named JNDMix. In detail, we randomly inject the JND noise, imperceptible to the human visual system (HVS), into the training image without any adjustment to its label. Extensive experiments demonstrate that JNDMix significantly improves the performance and data efficiency of various state-of-the-art NR-IQA models and the commonly used baseline models, as well as the generalization ability. More importantly, JNDMix facilitates MANIQA to achieve the state-of-the-art performance on LIVEC and KonIQ-10k.
Learning Transformer Features for Image Quality Assessment
Dec 01, 2021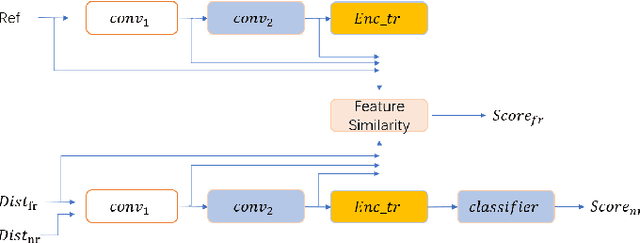
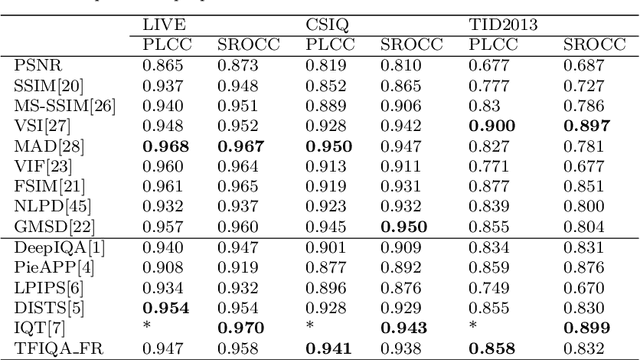
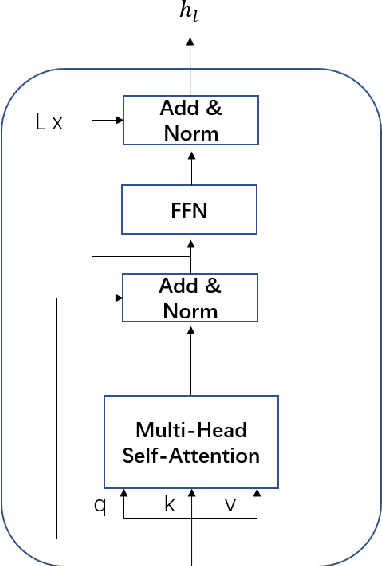
Objective image quality evaluation is a challenging task, which aims to measure the quality of a given image automatically. According to the availability of the reference images, there are Full-Reference and No-Reference IQA tasks, respectively. Most deep learning approaches use regression from deep features extracted by Convolutional Neural Networks. For the FR task, another option is conducting a statistical comparison on deep features. For all these methods, non-local information is usually neglected. In addition, the relationship between FR and NR tasks is less explored. Motivated by the recent success of transformers in modeling contextual information, we propose a unified IQA framework that utilizes CNN backbone and transformer encoder to extract features. The proposed framework is compatible with both FR and NR modes and allows for a joint training scheme. Evaluation experiments on three standard IQA datasets, i.e., LIVE, CSIQ and TID2013, and KONIQ-10K, show that our proposed model can achieve state-of-the-art FR performance. In addition, comparable NR performance is achieved in extensive experiments, and the results show that the NR performance can be leveraged by the joint training scheme.
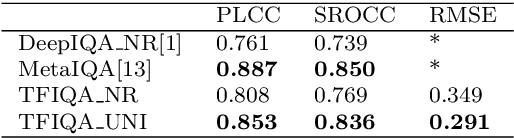
MUSIQ: Multi-scale Image Quality Transformer
Aug 12, 2021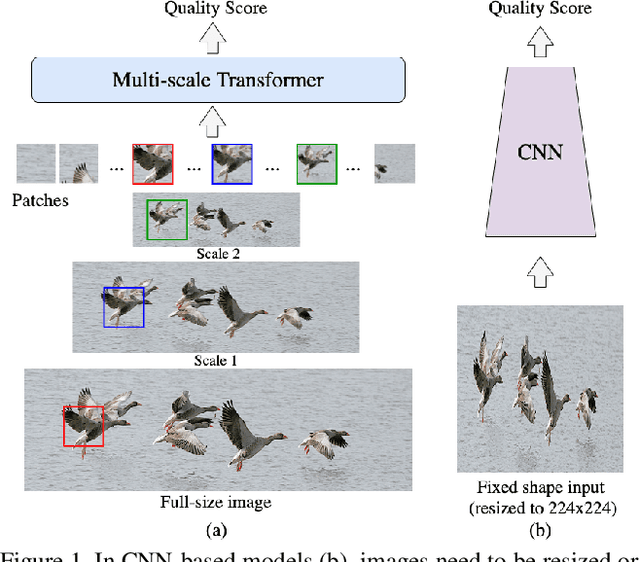
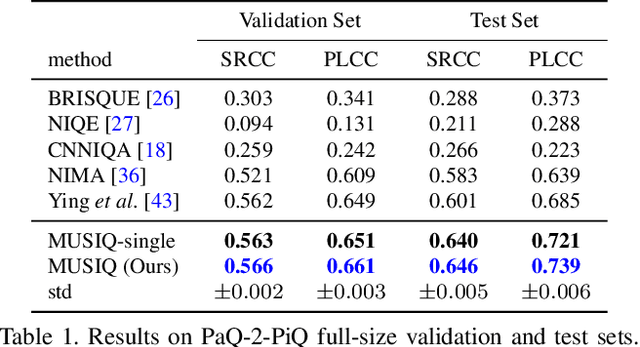
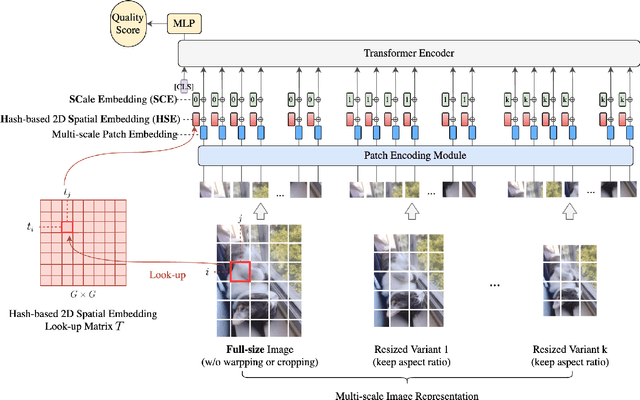
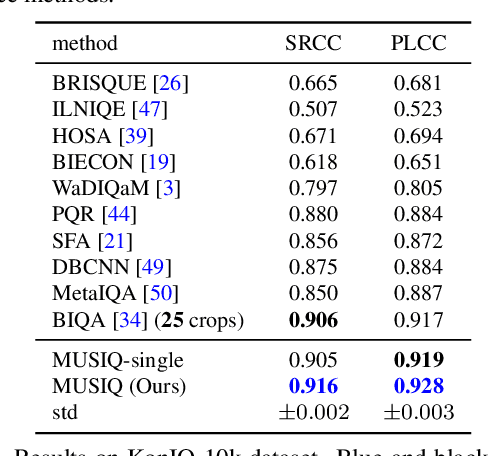
Image quality assessment (IQA) is an important research topic for understanding and improving visual experience. The current state-of-the-art IQA methods are based on convolutional neural networks (CNNs). The performance of CNN-based models is often compromised by the fixed shape constraint in batch training. To accommodate this, the input images are usually resized and cropped to a fixed shape, causing image quality degradation. To address this, we design a multi-scale image quality Transformer (MUSIQ) to process native resolution images with varying sizes and aspect ratios. With a multi-scale image representation, our proposed method can capture image quality at different granularities. Furthermore, a novel hash-based 2D spatial embedding and a scale embedding is proposed to support the positional embedding in the multi-scale representation. Experimental results verify that our method can achieve state-of-the-art performance on multiple large scale IQA datasets such as PaQ-2-PiQ, SPAQ and KonIQ-10k.
Norm-in-Norm Loss with Faster Convergence and Better Performance for Image Quality Assessment
Aug 10, 2020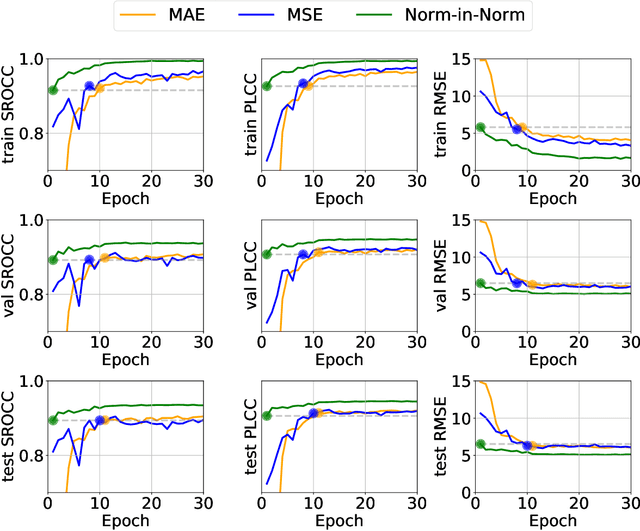

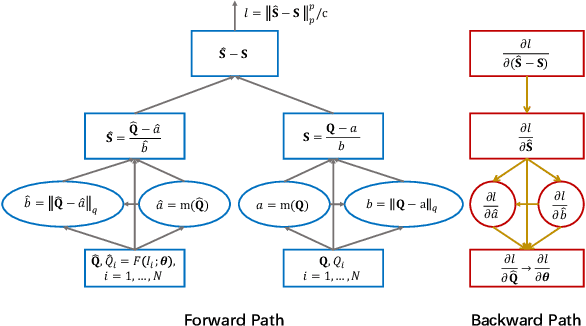
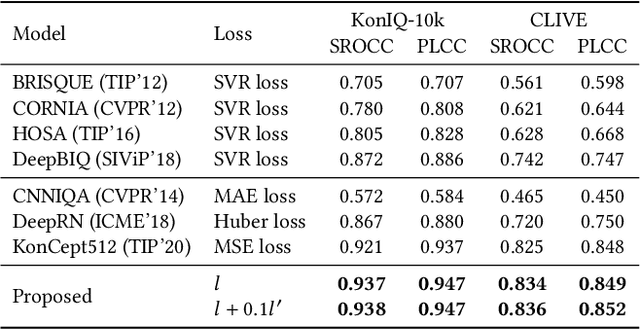
Currently, most image quality assessment (IQA) models are supervised by the MAE or MSE loss with empirically slow convergence. It is well-known that normalization can facilitate fast convergence. Therefore, we explore normalization in the design of loss functions for IQA. Specifically, we first normalize the predicted quality scores and the corresponding subjective quality scores. Then, the loss is defined based on the norm of the differences between these normalized values. The resulting "Norm-in-Norm'' loss encourages the IQA model to make linear predictions with respect to subjective quality scores. After training, the least squares regression is applied to determine the linear mapping from the predicted quality to the subjective quality. It is shown that the new loss is closely connected with two common IQA performance criteria (PLCC and RMSE). Through theoretical analysis, it is proved that the embedded normalization makes the gradients of the loss function more stable and more predictable, which is conducive to the faster convergence of the IQA model. Furthermore, to experimentally verify the effectiveness of the proposed loss, it is applied to solve a challenging problem: quality assessment of in-the-wild images. Experiments on two relevant datasets (KonIQ-10k and CLIVE) show that, compared to MAE or MSE loss, the new loss enables the IQA model to converge about 10 times faster and the final model achieves better performance. The proposed model also achieves state-of-the-art prediction performance on this challenging problem. For reproducible scientific research, our code is publicly available at https://github.com/lidq92/LinearityIQA.
KonIQ-10k: An ecologically valid database for deep learning of blind image quality assessment
Oct 14, 2019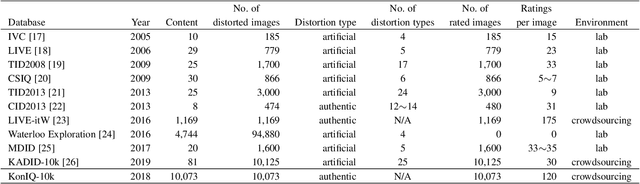
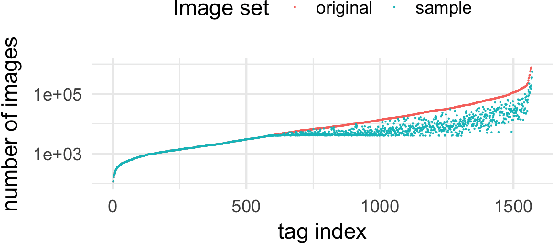

Deep learning methods for image quality assessment (IQA) are limited due to the small size of existing datasets. Extensive datasets require substantial resources both for generating publishable content, and annotating it accurately. We present a systematic and scalable approach to create KonIQ-10k, the largest IQA dataset to date consisting of 10,073 quality scored images. This is the first in-the-wild database aiming for ecological validity, with regard to the authenticity of distortions, the diversity of content, and quality-related indicators. Through the use of crowdsourcing, we obtained 1.2 million reliable quality ratings from 1,459 crowd workers, paving the way for more general IQA models. We propose a novel, deep learning model (KonCept512), to show an excellent generalization beyond the test set (0.921 SROCC), to the current state-of-the-art database LIVE-in-the-Wild (0.825 SROCC). The model derives its core performance from the InceptionResNet architecture, being trained at a higher resolution than previous models (512x384). A correlation analysis shows that KonCept512 performs similar to having 9 subjective scores for each test image.
KonIQ-10k: Towards an ecologically valid and large-scale IQA database
Mar 22, 2018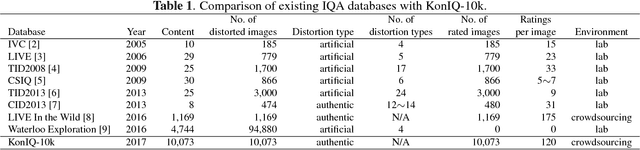
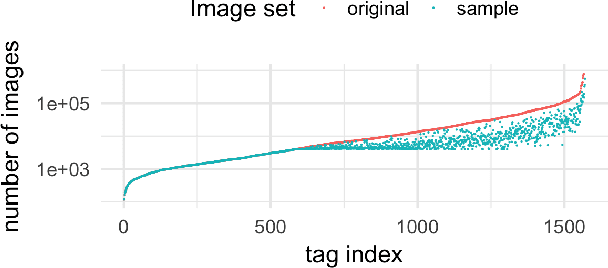

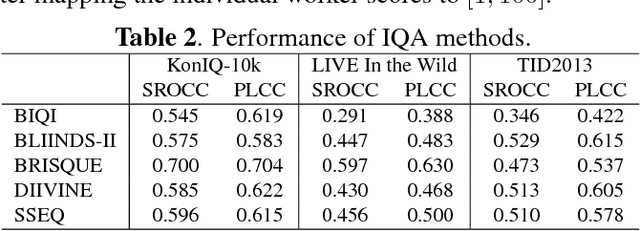
The main challenge in applying state-of-the-art deep learning methods to predict image quality in-the-wild is the relatively small size of existing quality scored datasets. The reason for the lack of larger datasets is the massive resources required in generating diverse and publishable content. We present a new systematic and scalable approach to create large-scale, authentic and diverse image datasets for Image Quality Assessment (IQA). We show how we built an IQA database, KonIQ-10k, consisting of 10,073 images, on which we performed very large scale crowdsourcing experiments in order to obtain reliable quality ratings from 1,467 crowd workers (1.2 million ratings). We argue for its ecological validity by analyzing the diversity of the dataset, by comparing it to state-of-the-art IQA databases, and by checking the reliability of our user studies.