 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage To Image Translation On Cityscapes To
Papers and Code
Adaptive Spatial Augmentation for Semi-supervised Semantic Segmentation
May 29, 2025



In semi-supervised semantic segmentation (SSSS), data augmentation plays a crucial role in the weak-to-strong consistency regularization framework, as it enhances diversity and improves model generalization. Recent strong augmentation methods have primarily focused on intensity-based perturbations, which have minimal impact on the semantic masks. In contrast, spatial augmentations like translation and rotation have long been acknowledged for their effectiveness in supervised semantic segmentation tasks, but they are often ignored in SSSS. In this work, we demonstrate that spatial augmentation can also contribute to model training in SSSS, despite generating inconsistent masks between the weak and strong augmentations. Furthermore, recognizing the variability among images, we propose an adaptive augmentation strategy that dynamically adjusts the augmentation for each instance based on entropy. Extensive experiments show that our proposed Adaptive Spatial Augmentation (\textbf{ASAug}) can be integrated as a pluggable module, consistently improving the performance of existing methods and achieving state-of-the-art results on benchmark datasets such as PASCAL VOC 2012, Cityscapes, and COCO.
Enhanced Unsupervised Image-to-Image Translation Using Contrastive Learning and Histogram of Oriented Gradients
Sep 26, 2024



Image-to-Image Translation is a vital area of computer vision that focuses on transforming images from one visual domain to another while preserving their core content and structure. However, this field faces two major challenges: first, the data from the two domains are often unpaired, making it difficult to train generative adversarial networks effectively; second, existing methods tend to produce artifacts or hallucinations during image generation, leading to a decline in image quality. To address these issues, this paper proposes an enhanced unsupervised image-to-image translation method based on the Contrastive Unpaired Translation (CUT) model, incorporating Histogram of Oriented Gradients (HOG) features. This novel approach ensures the preservation of the semantic structure of images, even without semantic labels, by minimizing the loss between the HOG features of input and generated images. The method was tested on translating synthetic game environments from GTA5 dataset to realistic urban scenes in cityscapes dataset, demonstrating significant improvements in reducing hallucinations and enhancing image quality.
SVS-GAN: Leveraging GANs for Semantic Video Synthesis
Sep 09, 2024



In recent years, there has been a growing interest in Semantic Image Synthesis (SIS) through the use of Generative Adversarial Networks (GANs) and diffusion models. This field has seen innovations such as the implementation of specialized loss functions tailored for this task, diverging from the more general approaches in Image-to-Image (I2I) translation. While the concept of Semantic Video Synthesis (SVS)$\unicode{x2013}$the generation of temporally coherent, realistic sequences of images from semantic maps$\unicode{x2013}$is newly formalized in this paper, some existing methods have already explored aspects of this field. Most of these approaches rely on generic loss functions designed for video-to-video translation or require additional data to achieve temporal coherence. In this paper, we introduce the SVS-GAN, a framework specifically designed for SVS, featuring a custom architecture and loss functions. Our approach includes a triple-pyramid generator that utilizes SPADE blocks. Additionally, we employ a U-Net-based network for the image discriminator, which performs semantic segmentation for the OASIS loss. Through this combination of tailored architecture and objective engineering, our framework aims to bridge the existing gap between SIS and SVS, outperforming current state-of-the-art models on datasets like Cityscapes and KITTI-360.
BlenDA: Domain Adaptive Object Detection through diffusion-based blending
Jan 18, 2024



Unsupervised domain adaptation (UDA) aims to transfer a model learned using labeled data from the source domain to unlabeled data in the target domain. To address the large domain gap issue between the source and target domains, we propose a novel regularization method for domain adaptive object detection, BlenDA, by generating the pseudo samples of the intermediate domains and their corresponding soft domain labels for adaptation training. The intermediate samples are generated by dynamically blending the source images with their corresponding translated images using an off-the-shelf pre-trained text-to-image diffusion model which takes the text label of the target domain as input and has demonstrated superior image-to-image translation quality. Based on experimental results from two adaptation benchmarks, our proposed approach can significantly enhance the performance of the state-of-the-art domain adaptive object detector, Adversarial Query Transformer (AQT). Particularly, in the Cityscapes to Foggy Cityscapes adaptation, we achieve an impressive 53.4% mAP on the Foggy Cityscapes dataset, surpassing the previous state-of-the-art by 1.5%. It is worth noting that our proposed method is also applicable to various paradigms of domain adaptive object detection. The code is available at:https://github.com/aiiu-lab/BlenDA
Improving Panoptic Segmentation for Nighttime or Low-Illumination Urban Driving Scenes
Jun 23, 2023



Autonomous vehicles and driving systems use scene parsing as an essential tool to understand the surrounding environment. Panoptic segmentation is a state-of-the-art technique which proves to be pivotal in this use case. Deep learning-based architectures have been utilized for effective and efficient Panoptic Segmentation in recent times. However, when it comes to adverse conditions like dark scenes with poor illumination or nighttime images, existing methods perform poorly in comparison to daytime images. One of the main factors for poor results is the lack of sufficient and accurately annotated nighttime images for urban driving scenes. In this work, we propose two new methods, first to improve the performance, and second to improve the robustness of panoptic segmentation in nighttime or poor illumination urban driving scenes using a domain translation approach. The proposed approach makes use of CycleGAN (Zhu et al., 2017) to translate daytime images with existing panoptic annotations into nighttime images, which are then utilized to retrain a Panoptic segmentation model to improve performance and robustness under poor illumination and nighttime conditions. In our experiments, Approach-1 demonstrates a significant improvement in the Panoptic segmentation performance on the converted Cityscapes dataset with more than +10% PQ, +12% RQ, +2% SQ, +14% mIoU and +10% AP50 absolute gain. Approach-2 demonstrates improved robustness to varied nighttime driving environments. Both the approaches are supported via comprehensive quantitative and qualitative analysis.
Domain Adaptation of Synthetic Driving Datasets for Real-World Autonomous Driving
Feb 08, 2023While developing perception based deep learning models, the benefit of synthetic data is enormous. However, performance of networks trained with synthetic data for certain computer vision tasks degrade significantly when tested on real world data due to the domain gap between them. One of the popular solutions in bridging this gap between synthetic and actual world data is to frame it as a domain adaptation task. In this paper, we propose and evaluate novel ways for the betterment of such approaches. In particular we build upon the method of UNIT-GAN. In normal GAN training for the task of domain translation, pairing of images from both the domains (viz, real and synthetic) is done randomly. We propose a novel method to efficiently incorporate semantic supervision into this pair selection, which helps in boosting the performance of the model along with improving the visual quality of such transformed images. We illustrate our empirical findings on Cityscapes \cite{cityscapes} and challenging synthetic dataset Synscapes. Though the findings are reported on the base network of UNIT-GAN, they can be easily extended to any other similar network.
Towards Pragmatic Semantic Image Synthesis for Urban Scenes
May 16, 2023



The need for large amounts of training and validation data is a huge concern in scaling AI algorithms for autonomous driving. Semantic Image Synthesis (SIS), or label-to-image translation, promises to address this issue by translating semantic layouts to images, providing a controllable generation of photorealistic data. However, they require a large amount of paired data, incurring extra costs. In this work, we present a new task: given a dataset with synthetic images and labels and a dataset with unlabeled real images, our goal is to learn a model that can generate images with the content of the input mask and the appearance of real images. This new task reframes the well-known unsupervised SIS task in a more practical setting, where we leverage cheaply available synthetic data from a driving simulator to learn how to generate photorealistic images of urban scenes. This stands in contrast to previous works, which assume that labels and images come from the same domain but are unpaired during training. We find that previous unsupervised works underperform on this task, as they do not handle distribution shifts between two different domains. To bypass these problems, we propose a novel framework with two main contributions. First, we leverage the synthetic image as a guide to the content of the generated image by penalizing the difference between their high-level features on a patch level. Second, in contrast to previous works which employ one discriminator that overfits the target domain semantic distribution, we employ a discriminator for the whole image and multiscale discriminators on the image patches. Extensive comparisons on the benchmarks GTA-V $\rightarrow$ Cityscapes and GTA-V $\rightarrow$ Mapillary show the superior performance of the proposed model against state-of-the-art on this task.
Semantically Consistent Image-to-Image Translation for Unsupervised Domain Adaptation
Nov 25, 2021
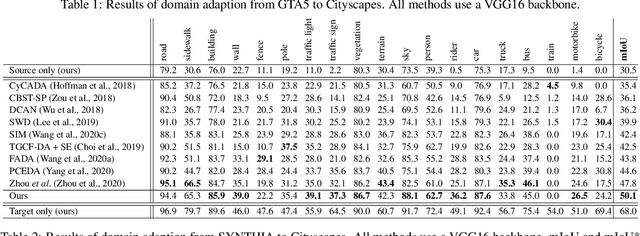
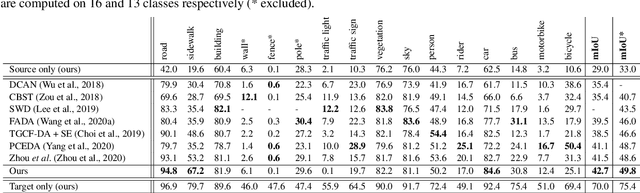

Unsupervised Domain Adaptation (UDA) aims to adapt models trained on a source domain to a new target domain where no labelled data is available. In this work, we investigate the problem of UDA from a synthetic computer-generated domain to a similar but real-world domain for learning semantic segmentation. We propose a semantically consistent image-to-image translation method in combination with a consistency regularisation method for UDA. We overcome previous limitations on transferring synthetic images to real looking images. We leverage pseudo-labels in order to learn a generative image-to-image translation model that receives additional feedback from semantic labels on both domains. Our method outperforms state-of-the-art methods that combine image-to-image translation and semi-supervised learning on relevant domain adaptation benchmarks, i.e., on GTA5 to Cityscapes and SYNTHIA to Cityscapes.
Semi-supervised domain adaptation with CycleGAN guided by a downstream task loss
Aug 18, 2022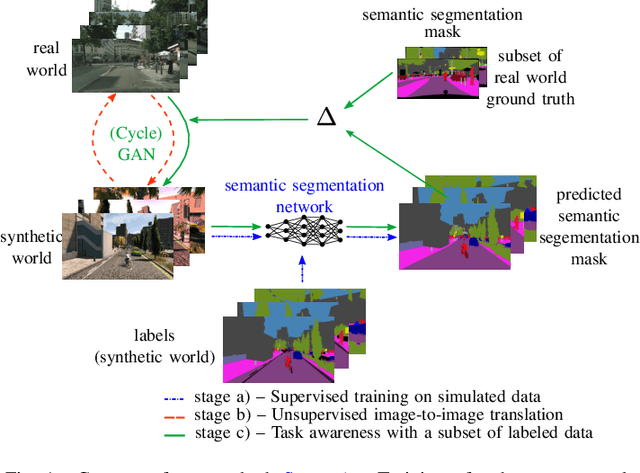
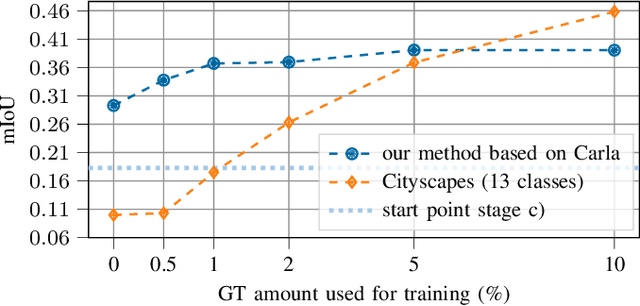


Domain adaptation is of huge interest as labeling is an expensive and error-prone task, especially when labels are needed on pixel-level like in semantic segmentation. Therefore, one would like to be able to train neural networks on synthetic domains, where data is abundant and labels are precise. However, these models often perform poorly on out-of-domain images. To mitigate the shift in the input, image-to-image approaches can be used. Nevertheless, standard image-to-image approaches that bridge the domain of deployment with the synthetic training domain do not focus on the downstream task but only on the visual inspection level. We therefore propose a "task aware" version of a GAN in an image-to-image domain adaptation approach. With the help of a small amount of labeled ground truth data, we guide the image-to-image translation to a more suitable input image for a semantic segmentation network trained on synthetic data (synthetic-domain expert). The main contributions of this work are 1) a modular semi-supervised domain adaptation method for semantic segmentation by training a downstream task aware CycleGAN while refraining from adapting the synthetic semantic segmentation expert 2) the demonstration that the method is applicable to complex domain adaptation tasks and 3) a less biased domain gap analysis by using from scratch networks. We evaluate our method on a classification task as well as on semantic segmentation. Our experiments demonstrate that our method outperforms CycleGAN - a standard image-to-image approach - by 7 percent points in accuracy in a classification task using only 70 (10%) ground truth images. For semantic segmentation we can show an improvement of about 4 to 7 percent points in mean Intersection over union on the Cityscapes evaluation dataset with only 14 ground truth images during training.
Semantic Map Injected GAN Training for Image-to-Image Translation
Dec 03, 2021
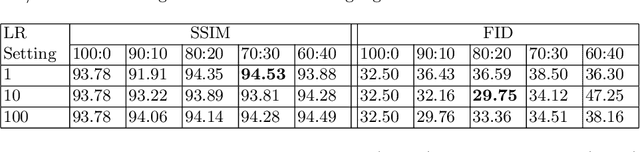

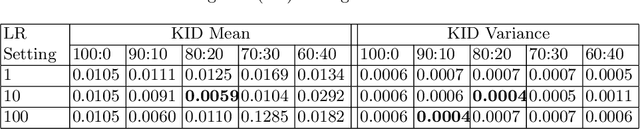
Image-to-image translation is the recent trend to transform images from one domain to another domain using generative adversarial network (GAN). The existing GAN models perform the training by only utilizing the input and output modalities of transformation. In this paper, we perform the semantic injected training of GAN models. Specifically, we train with original input and output modalities and inject a few epochs of training for translation from input to semantic map. Lets refer the original training as the training for the translation of input image into target domain. The injection of semantic training in the original training improves the generalization capability of the trained GAN model. Moreover, it also preserves the categorical information in a better way in the generated image. The semantic map is only utilized at the training time and is not required at the test time. The experiments are performed using state-of-the-art GAN models over CityScapes and RGB-NIR stereo datasets. We observe the improved performance in terms of the SSIM, FID and KID scores after injecting semantic training as compared to original training.