 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICPR 2024 Competition on Safe Segmentation of Drive Scenes in Unstructured Traffic and Adverse Weather Conditions
Sep 09, 2024



The ICPR 2024 Competition on Safe Segmentation of Drive Scenes in Unstructured Traffic and Adverse Weather Conditions served as a rigorous platform to evaluate and benchmark state-of-the-art semantic segmentation models under challenging conditions for autonomous driving. Over several months, participants were provided with the IDD-AW dataset, consisting of 5000 high-quality RGB-NIR image pairs, each annotated at the pixel level and captured under adverse weather conditions such as rain, fog, low light, and snow. A key aspect of the competition was the use and improvement of the Safe mean Intersection over Union (Safe mIoU) metric, designed to penalize unsafe incorrect predictions that could be overlooked by traditional mIoU. This innovative metric emphasized the importance of safety in developing autonomous driving systems. The competition showed significant advancements in the field, with participants demonstrating models that excelled in semantic segmentation and prioritized safety and robustness in unstructured and adverse conditions. The results of the competition set new benchmarks in the domain, highlighting the critical role of safety in deploying autonomous vehicles in real-world scenarios. The contributions from this competition are expected to drive further innovation in autonomous driving technology, addressing the critical challenges of operating in diverse and unpredictable environments.
IDD-AW: A Benchmark for Safe and Robust Segmentation of Drive Scenes in Unstructured Traffic and Adverse Weather
Nov 24, 2023



Large-scale deployment of fully autonomous vehicles requires a very high degree of robustness to unstructured traffic, and weather conditions, and should prevent unsafe mispredictions. While there are several datasets and benchmarks focusing on segmentation for drive scenes, they are not specifically focused on safety and robustness issues. We introduce the IDD-AW dataset, which provides 5000 pairs of high-quality images with pixel-level annotations, captured under rain, fog, low light, and snow in unstructured driving conditions. As compared to other adverse weather datasets, we provide i.) more annotated images, ii.) paired Near-Infrared (NIR) image for each frame, iii.) larger label set with a 4-level label hierarchy to capture unstructured traffic conditions. We benchmark state-of-the-art models for semantic segmentation in IDD-AW. We also propose a new metric called ''Safe mean Intersection over Union (Safe mIoU)'' for hierarchical datasets which penalizes dangerous mispredictions that are not captured in the traditional definition of mean Intersection over Union (mIoU). The results show that IDD-AW is one of the most challenging datasets to date for these tasks. The dataset and code will be available here: http://iddaw.github.io.
Semantic Map Injected GAN Training for Image-to-Image Translation
Dec 03, 2021
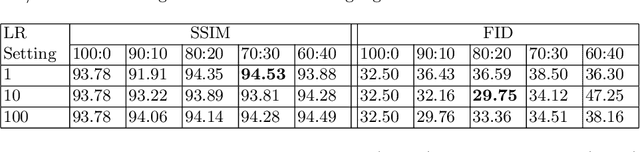

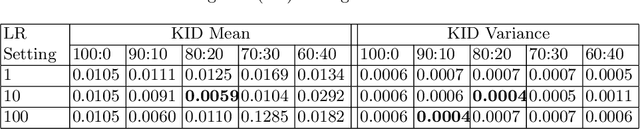
Image-to-image translation is the recent trend to transform images from one domain to another domain using generative adversarial network (GAN). The existing GAN models perform the training by only utilizing the input and output modalities of transformation. In this paper, we perform the semantic injected training of GAN models. Specifically, we train with original input and output modalities and inject a few epochs of training for translation from input to semantic map. Lets refer the original training as the training for the translation of input image into target domain. The injection of semantic training in the original training improves the generalization capability of the trained GAN model. Moreover, it also preserves the categorical information in a better way in the generated image. The semantic map is only utilized at the training time and is not required at the test time. The experiments are performed using state-of-the-art GAN models over CityScapes and RGB-NIR stereo datasets. We observe the improved performance in terms of the SSIM, FID and KID scores after injecting semantic training as compared to original training.