 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Machine Paraphrased Plagiarism
Papers and Code
Language Modeling and Understanding Through Paraphrase Generation and Detection
Feb 09, 2026Language enables humans to share knowledge, reason about the world, and pass on strategies for survival and innovation across generations. At the heart of this process is not just the ability to communicate but also the remarkable flexibility in how we can express ourselves. We can express the same thoughts in virtually infinite ways using different words and structures - this ability to rephrase and reformulate expressions is known as paraphrase. Modeling paraphrases is a keystone to meaning in computational language models; being able to construct different variations of texts that convey the same meaning or not shows strong abilities of semantic understanding. If computational language models are to represent meaning, they must understand and control the different aspects that construct the same meaning as opposed to different meanings at a fine granularity. Yet most existing approaches reduce paraphrasing to a binary decision between two texts or to producing a single rewrite of a source, obscuring which linguistic factors are responsible for meaning preservation. In this thesis, I propose that decomposing paraphrases into their constituent linguistic aspects (paraphrase types) offers a more fine-grained and cognitively grounded view of semantic equivalence. I show that even advanced machine learning models struggle with this task. Yet, when explicitly trained on paraphrase types, models achieve stronger performance on related paraphrase tasks and downstream applications. For example, in plagiarism detection, language models trained on paraphrase types surpass human baselines: 89.6% accuracy compared to 78.4% for plagiarism cases from Wikipedia, and 66.5% compared to 55.7% for plagiarism of scientific papers from arXiv. In identifying duplicate questions on Quora, models trained with paraphrase types improve over models trained on binary pairs. Furthermore, I demonstrate that...
Your Language Model Can Secretly Write Like Humans: Contrastive Paraphrase Attacks on LLM-Generated Text Detectors
May 21, 2025



The misuse of large language models (LLMs), such as academic plagiarism, has driven the development of detectors to identify LLM-generated texts. To bypass these detectors, paraphrase attacks have emerged to purposely rewrite these texts to evade detection. Despite the success, existing methods require substantial data and computational budgets to train a specialized paraphraser, and their attack efficacy greatly reduces when faced with advanced detection algorithms. To address this, we propose \textbf{Co}ntrastive \textbf{P}araphrase \textbf{A}ttack (CoPA), a training-free method that effectively deceives text detectors using off-the-shelf LLMs. The first step is to carefully craft instructions that encourage LLMs to produce more human-like texts. Nonetheless, we observe that the inherent statistical biases of LLMs can still result in some generated texts carrying certain machine-like attributes that can be captured by detectors. To overcome this, CoPA constructs an auxiliary machine-like word distribution as a contrast to the human-like distribution generated by the LLM. By subtracting the machine-like patterns from the human-like distribution during the decoding process, CoPA is able to produce sentences that are less discernible by text detectors. Our theoretical analysis suggests the superiority of the proposed attack. Extensive experiments validate the effectiveness of CoPA in fooling text detectors across various scenarios.
Detecting Document-level Paraphrased Machine Generated Content: Mimicking Human Writing Style and Involving Discourse Features
Dec 17, 2024



The availability of high-quality APIs for Large Language Models (LLMs) has facilitated the widespread creation of Machine-Generated Content (MGC), posing challenges such as academic plagiarism and the spread of misinformation. Existing MGC detectors often focus solely on surface-level information, overlooking implicit and structural features. This makes them susceptible to deception by surface-level sentence patterns, particularly for longer texts and in texts that have been subsequently paraphrased. To overcome these challenges, we introduce novel methodologies and datasets. Besides the publicly available dataset Plagbench, we developed the paraphrased Long-Form Question and Answer (paraLFQA) and paraphrased Writing Prompts (paraWP) datasets using GPT and DIPPER, a discourse paraphrasing tool, by extending artifacts from their original versions. To address the challenge of detecting highly similar paraphrased texts, we propose MhBART, an encoder-decoder model designed to emulate human writing style while incorporating a novel difference score mechanism. This model outperforms strong classifier baselines and identifies deceptive sentence patterns. To better capture the structure of longer texts at document level, we propose DTransformer, a model that integrates discourse analysis through PDTB preprocessing to encode structural features. It results in substantial performance gains across both datasets -- 15.5\% absolute improvement on paraLFQA, 4\% absolute improvement on paraWP, and 1.5\% absolute improvement on M4 compared to SOTA approaches.
RADAR: Robust AI-Text Detection via Adversarial Learning
Jul 07, 2023Recent advances in large language models (LLMs) and the intensifying popularity of ChatGPT-like applications have blurred the boundary of high-quality text generation between humans and machines. However, in addition to the anticipated revolutionary changes to our technology and society, the difficulty of distinguishing LLM-generated texts (AI-text) from human-generated texts poses new challenges of misuse and fairness, such as fake content generation, plagiarism, and false accusation of innocent writers. While existing works show that current AI-text detectors are not robust to LLM-based paraphrasing, this paper aims to bridge this gap by proposing a new framework called RADAR, which jointly trains a Robust AI-text Detector via Adversarial leaRning. RADAR is based on adversarial training of a paraphraser and a detector. The paraphraser's goal is to generate realistic contents to evade AI-text detection. RADAR uses the feedback from the detector to update the paraphraser, and vice versa. Evaluated with 8 different LLMs (Pythia, Dolly 2.0, Palmyra, Camel, GPT-J, Dolly 1.0, LLaMA, and Vicuna) across 4 datasets, experimental results show that RADAR significantly outperforms existing AI-text detection methods, especially when paraphrasing is in place. We also identify the strong transferability of RADAR from instruction-tuned LLMs to other LLMs, and evaluate the improved capability of RADAR via GPT-3.5.
How Large Language Models are Transforming Machine-Paraphrased Plagiarism
Oct 07, 2022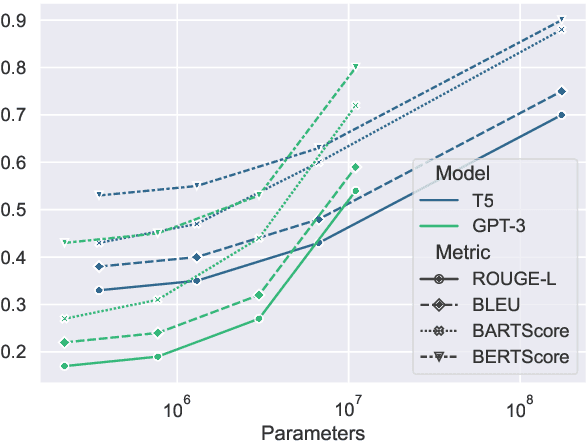

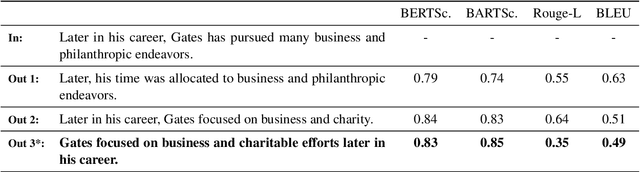
The recent success of large language models for text generation poses a severe threat to academic integrity, as plagiarists can generate realistic paraphrases indistinguishable from original work. However, the role of large autoregressive transformers in generating machine-paraphrased plagiarism and their detection is still developing in the literature. This work explores T5 and GPT-3 for machine-paraphrase generation on scientific articles from arXiv, student theses, and Wikipedia. We evaluate the detection performance of six automated solutions and one commercial plagiarism detection software and perform a human study with 105 participants regarding their detection performance and the quality of generated examples. Our results suggest that large models can rewrite text humans have difficulty identifying as machine-paraphrased (53% mean acc.). Human experts rate the quality of paraphrases generated by GPT-3 as high as original texts (clarity 4.0/5, fluency 4.2/5, coherence 3.8/5). The best-performing detection model (GPT-3) achieves a 66% F1-score in detecting paraphrases.
Identifying Machine-Paraphrased Plagiarism
Mar 22, 2021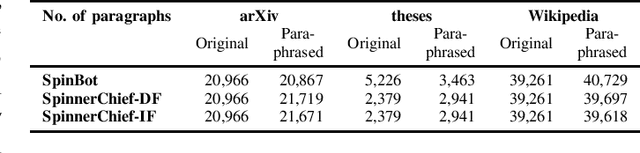

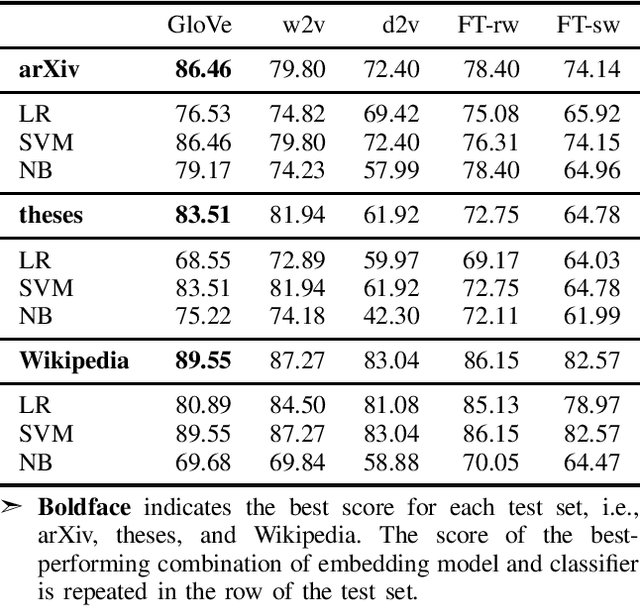
Employing paraphrasing tools to conceal plagiarized text is a severe threat to academic integrity. To enable the detection of machine-paraphrased text, we evaluate the effectiveness of five pre-trained word embedding models combined with machine learning classifiers and state-of-the-art neural language models. We analyze preprints of research papers, graduation theses, and Wikipedia articles, which we paraphrased using different configurations of the tools SpinBot and SpinnerChief. The best performing technique, Longformer, achieved an average F1 score of 80.99% (F1=99.68% for SpinBot and F1=71.64% for SpinnerChief cases), while human evaluators achieved F1=78.4% for SpinBot and F1=65.6% for SpinnerChief cases. We show that the automated classification alleviates shortcomings of widely-used text-matching systems, such as Turnitin and PlagScan. To facilitate future research, all data, code, and two web applications showcasing our contributions are openly available.