 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcoustic Novelty Detection
Papers and Code
AquaSignal: An Integrated Framework for Robust Underwater Acoustic Analysis
May 20, 2025This paper presents AquaSignal, a modular and scalable pipeline for preprocessing, denoising, classification, and novelty detection of underwater acoustic signals. Designed to operate effectively in noisy and dynamic marine environments, AquaSignal integrates state-of-the-art deep learning architectures to enhance the reliability and accuracy of acoustic signal analysis. The system is evaluated on a combined dataset from the Deepship and Ocean Networks Canada (ONC) benchmarks, providing a diverse set of real-world underwater scenarios. AquaSignal employs a U-Net architecture for denoising, a ResNet18 convolutional neural network for classifying known acoustic events, and an AutoEncoder-based model for unsupervised detection of novel or anomalous signals. To our knowledge, this is the first comprehensive study to apply and evaluate this combination of techniques on maritime vessel acoustic data. Experimental results show that AquaSignal improves signal clarity and task performance, achieving 71% classification accuracy and 91% accuracy in novelty detection. Despite slightly lower classification performance compared to some state-of-the-art models, differences in data partitioning strategies limit direct comparisons. Overall, AquaSignal demonstrates strong potential for real-time underwater acoustic monitoring in scientific, environmental, and maritime domains.
Audio-Based Classification of Insect Species Using Machine Learning Models: Cicada, Beetle, Termite, and Cricket
Feb 19, 2025This project addresses the challenge of classifying insect species: Cicada, Beetle, Termite, and Cricket using sound recordings. Accurate species identification is crucial for ecological monitoring and pest management. We employ machine learning models such as XGBoost, Random Forest, and K Nearest Neighbors (KNN) to analyze audio features, including Mel Frequency Cepstral Coefficients (MFCC). The potential novelty of this work lies in the combination of diverse audio features and machine learning models to tackle insect classification, specifically focusing on capturing subtle acoustic variations between species that have not been fully leveraged in previous research. The dataset is compiled from various open sources, and we anticipate achieving high classification accuracy, contributing to improved automated insect detection systems.
Representational learning for an anomalous sound detection system with source separation model
Oct 29, 2024The detection of anomalous sounds in machinery operation presents a significant challenge due to the difficulty in generalizing anomalous acoustic patterns. This task is typically approached as an unsupervised learning or novelty detection problem, given the complexities associated with the acquisition of comprehensive anomalous acoustic data. Conventional methodologies for training anomalous sound detection systems primarily employ auto-encoder architectures or representational learning with auxiliary tasks. However, both approaches have inherent limitations. Auto-encoder structures are constrained to utilizing only the target machine's operational sounds, while training with auxiliary tasks, although capable of incorporating diverse acoustic inputs, may yield representations that lack correlation with the characteristic acoustic signatures of anomalous conditions. We propose a training method based on the source separation model (CMGAN) that aims to isolate non-target machine sounds from a mixture of target and non-target class acoustic signals. This approach enables the effective utilization of diverse machine sounds and facilitates the training of complex neural network architectures with limited sample sizes. Our experimental results demonstrate that the proposed method yields better performance compared to both conventional auto-encoder training approaches and source separation techniques that focus on isolating target machine signals. Moreover, our experimental results demonstrate that the proposed method exhibits the potential for enhanced representation learning as the quantity of non-target data increases, even while maintaining a constant volume of target class data.
DCASE 2024 Task 4: Sound Event Detection with Heterogeneous Data and Missing Labels
Jun 12, 2024


The Detection and Classification of Acoustic Scenes and Events Challenge Task 4 aims to advance sound event detection (SED) systems in domestic environments by leveraging training data with different supervision uncertainty. Participants are challenged in exploring how to best use training data from different domains and with varying annotation granularity (strong/weak temporal resolution, soft/hard labels), to obtain a robust SED system that can generalize across different scenarios. Crucially, annotation across available training datasets can be inconsistent and hence sound labels of one dataset may be present but not annotated in the other one and vice-versa. As such, systems will have to cope with potentially missing target labels during training. Moreover, as an additional novelty, systems will also be evaluated on labels with different granularity in order to assess their robustness for different applications. To lower the entry barrier for participants, we developed an updated baseline system with several caveats to address these aforementioned problems. Results with our baseline system indicate that this research direction is promising and is possible to obtain a stronger SED system by using diverse domain training data with missing labels compared to training a SED system for each domain separately.
Multimodal sensor fusion for real-time location-dependent defect detection in laser-directed energy deposition
May 23, 2023Real-time defect detection is crucial in laser-directed energy deposition (L-DED) additive manufacturing (AM). Traditional in-situ monitoring approach utilizes a single sensor (i.e., acoustic, visual, or thermal sensor) to capture the complex process dynamic behaviors, which is insufficient for defect detection with high accuracy and robustness. This paper proposes a novel multimodal sensor fusion method for real-time location-dependent defect detection in the robotic L-DED process. The multimodal fusion sources include a microphone sensor capturing the laser-material interaction sound and a visible spectrum CCD camera capturing the coaxial melt pool images. A hybrid convolutional neural network (CNN) is proposed to fuse acoustic and visual data. The key novelty in this study is that the traditional manual feature extraction procedures are no longer required, and the raw melt pool images and acoustic signals are fused directly by the hybrid CNN model, which achieved the highest defect prediction accuracy (98.5 %) without the thermal sensing modality. Moreover, unlike previous region-based quality prediction, the proposed hybrid CNN can detect the onset of defect occurrences. The defect prediction outcomes are synchronized and registered with in-situ acquired robot tool-center-point (TCP) data, which enables localized defect identification. The proposed multimodal sensor fusion method offers a robust solution for in-situ defect detection.
Multisensor fusion-based digital twin in additive manufacturing for in-situ quality monitoring and defect correction
Apr 12, 2023Early detection and correction of defects are critical in additive manufacturing (AM) to avoid build failures. In this paper, we present a multisensor fusion-based digital twin for in-situ quality monitoring and defect correction in a robotic laser direct energy deposition process. Multisensor fusion sources consist of an acoustic sensor, an infrared thermal camera, a coaxial vision camera, and a laser line scanner. The key novelty and contribution of this work are to develop a spatiotemporal data fusion method that synchronizes and registers the multisensor features within the part's 3D volume. The fused dataset can be used to predict location-specific quality using machine learning. On-the-fly identification of regions requiring material addition or removal is feasible. Robot toolpath and auto-tuned process parameters are generated for defecting correction. In contrast to traditional single-sensor-based monitoring, multisensor fusion allows for a more in-depth understanding of underlying process physics, such as pore formation and laser-material interactions. The proposed methods pave the way for self-adaptation AM with higher efficiency, less waste, and cleaner production.
Description and analysis of novelties introduced in DCASE Task 4 2022 on the baseline system
Oct 14, 2022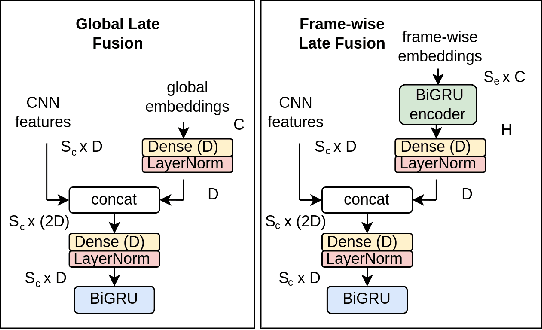
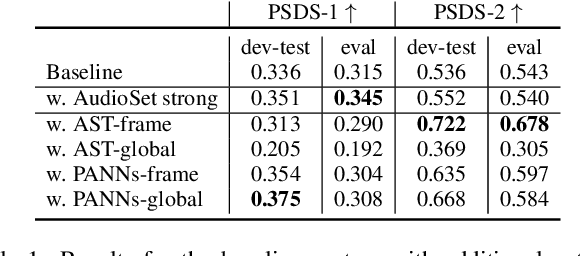
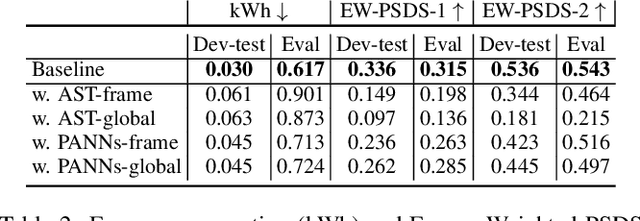
The aim of the Detection and Classification of Acoustic Scenes and Events Challenge Task 4 is to evaluate systems for the detection of sound events in domestic environments using an heterogeneous dataset. The systems need to be able to correctly detect the sound events present in a recorded audio clip, as well as localize the events in time. This year's task is a follow-up of DCASE 2021 Task 4, with some important novelties. The goal of this paper is to describe and motivate these new additions, and report an analysis of their impact on the baseline system. We introduced three main novelties: the use of external datasets, including recently released strongly annotated clips from Audioset, the possibility of leveraging pre-trained models, and a new energy consumption metric to raise awareness about the ecological impact of training sound events detectors. The results on the baseline system show that leveraging open-source pretrained on AudioSet improves the results significantly in terms of event classification but not in terms of event segmentation.
Recurrent Neural Networks with Stochastic Layers for Acoustic Novelty Detection
Feb 13, 2019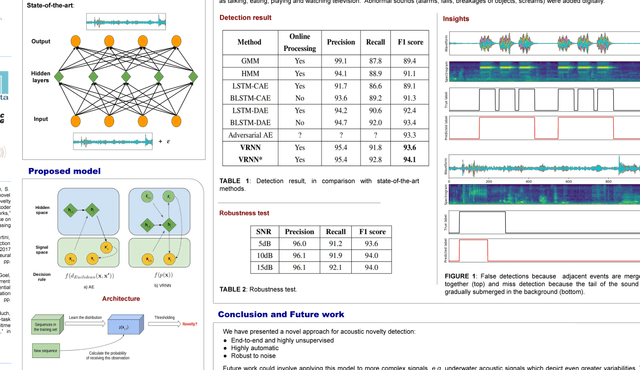
In this paper, we adapt Recurrent Neural Networks with Stochastic Layers, which are the state-of-the-art for generating text, music and speech, to the problem of acoustic novelty detection. By integrating uncertainty into the hidden states, this type of network is able to learn the distribution of complex sequences. Because the learned distribution can be calculated explicitly in terms of probability, we can evaluate how likely an observation is then detect low-probability events as novel. The model is robust, highly unsupervised, end-to-end and requires minimum preprocessing, feature engineering or hyperparameter tuning. An experiment on a benchmark dataset shows that our model outperforms the state-of-the-art acoustic novelty detectors.
Detecting bird sound in unknown acoustic background using crowdsourced training data
May 24, 2015
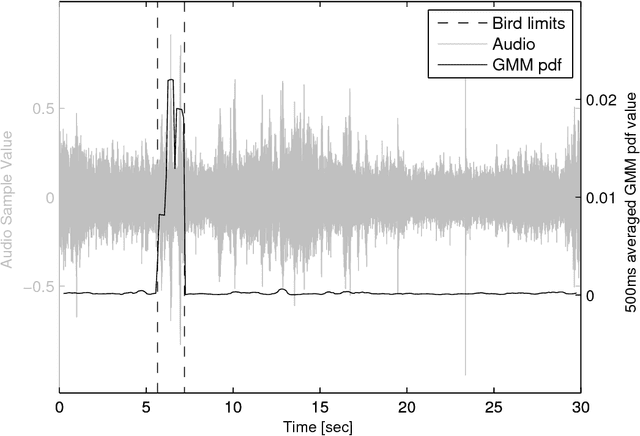
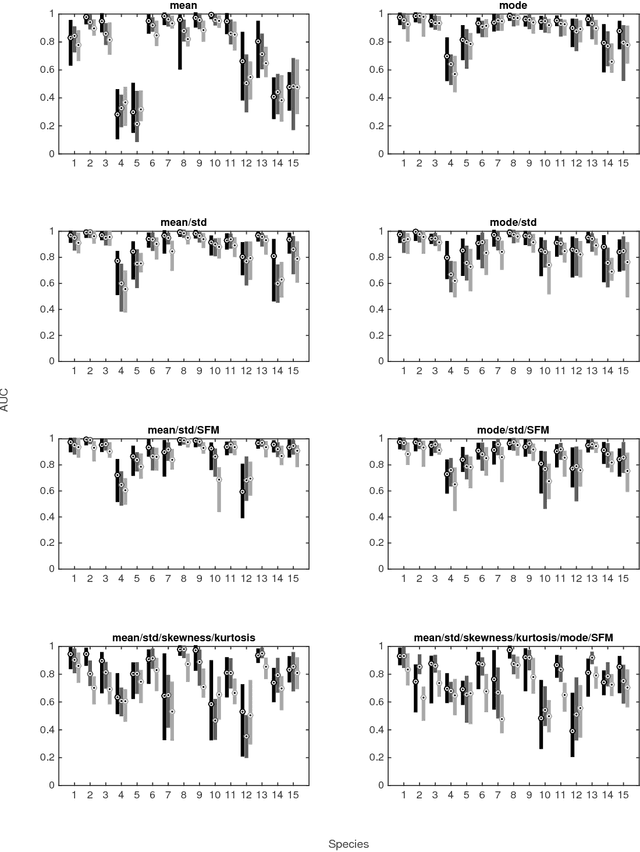
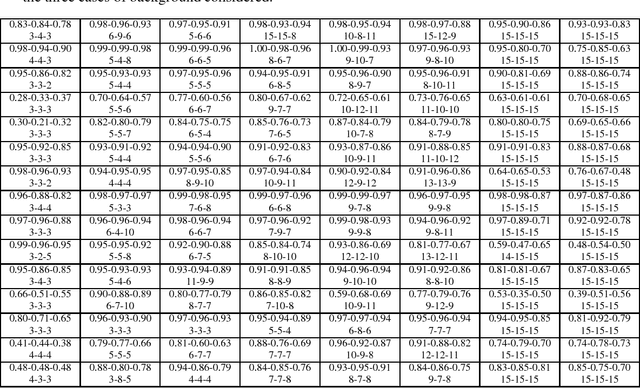
Biodiversity monitoring using audio recordings is achievable at a truly global scale via large-scale deployment of inexpensive, unattended recording stations or by large-scale crowdsourcing using recording and species recognition on mobile devices. The ability, however, to reliably identify vocalising animal species is limited by the fact that acoustic signatures of interest in such recordings are typically embedded in a diverse and complex acoustic background. To avoid the problems associated with modelling such backgrounds, we build generative models of bird sounds and use the concept of novelty detection to screen recordings to detect sections of data which are likely bird vocalisations. We present detection results against various acoustic environments and different signal-to-noise ratios. We discuss the issues related to selecting the cost function and setting detection thresholds in such algorithms. Our methods are designed to be scalable and automatically applicable to arbitrary selections of species depending on the specific geographic region and time period of deployment.