 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTFM-Retouche: A Lightweight Input-Space Adapter for Tabular Foundation Models
May 07, 2026Tabular foundation models (TFMs), such as TabPFN-2.6, TabICLv2, ConTextTab, Mitra, LimiX, and TabDPT, achieve strong zero-shot performance through in-context learning, but their inductive biases remain fixed at inference time. Adapting a pretrained TFM to a specific dataset or task typically requires either full fine-tuning, which is computationally expensive, or parameter-efficient tuning methods (PEFT) such as LoRA, which must be tailored to the internal architecture of each TFM. Furthermore, the evidence on whether weight-space fine-tuning improves accuracy or calibration is mixed \citep{tanna_exploring_2026,rubachev_finetuning_2025}. We introduce TFM-Retouche, a lightweight input-space residual adapter that is architecture-agnostic by design with respect to the frozen TFM backbone. TFM-Retouche learns a small residual correction in the input space to align the input data with the inductive biases of the pretrained model. The adapter is trained end-to-end through the frozen TFM, with a post-training identity guard that falls back to the unmodified TFM whenever adaptation does not help on held-out validation. On TabArena-Lite (51 datasets spanning binary classification, multiclass classification, and regression), TabICLv2-Retouche -- the framework instantiated on TabICLv2 -- is the top-ranked method on the leaderboard with light per-task tuning and ensembling, lifting aggregate Elo by +56 over the frozen TabICLv2 base and sitting on the Pareto front of predictive quality versus both training and inference time.
Boltzmann-based Exploration for Robust Decentralized Multi-Agent Planning
Mar 02, 2026Decentralized Monte Carlo Tree Search (Dec-MCTS) is widely used for cooperative multi-agent planning but struggles in sparse or skewed reward environments. We introduce Coordinated Boltzmann MCTS (CB-MCTS), which replaces deterministic UCT with a stochastic Boltzmann policy and a decaying entropy bonus for sustained yet focused exploration. While Boltzmann exploration has been studied in single-agent MCTS, applying it in multi-agent systems poses unique challenges. CB-MCTS is the first to address this. We analyze CB-MCTS in the simple-regret setting and show in simulations that it outperforms Dec-MCTS in deceptive scenarios and remains competitive on standard benchmarks, providing a robust solution for multi-agent planning.
Magazine Supply Optimization: a Case-study
Aug 16, 2024



Supply optimization is a complex and challenging task in the magazine retail industry because of the fixed inventory assumption, irregular sales patterns, and varying product and point-of-sale characteristics. We introduce AthenIA, an industrialized magazine supply optimization solution that plans the supply for over 20,000 points of sale in France. We modularize the supply planning process into a four-step pipeline: demand sensing, optimization, business rules, and operating. The core of the solution is a novel group conformalized quantile regression method that integrates domain expert insights, coupled with a supply optimization technique that balances the costs of out-of-stock against the costs of over-supply. AthenIA has proven to be a valuable tool for magazine publishers, particularly in the context of evolving economic and ecological challenges.
How Homogenizing the Channel-wise Magnitude Can Enhance EEG Classification Model?
Jul 19, 2024A significant challenge in the electroencephalogram EEG lies in the fact that current data representations involve multiple electrode signals, resulting in data redundancy and dominant lead information. However extensive research conducted on EEG classification focuses on designing model architectures without tackling the underlying issues. Otherwise, there has been a notable gap in addressing data preprocessing for EEG, leading to considerable computational overhead in Deep Learning (DL) processes. In light of these issues, we propose a simple yet effective approach for EEG data pre-processing. Our method first transforms the EEG data into an encoded image by an Inverted Channel-wise Magnitude Homogenization (ICWMH) to mitigate inter-channel biases. Next, we apply the edge detection technique on the EEG-encoded image combined with skip connection to emphasize the most significant transitions in the data while preserving structural and invariant information. By doing so, we can improve the EEG learning process efficiently without using a huge DL network. Our experimental evaluations reveal that we can significantly improve (i.e., from 2% to 5%) over current baselines.
Revisiting the Disequilibrium Issues in Tackling Heart Disease Classification Tasks
Jul 19, 2024



In the field of heart disease classification, two primary obstacles arise. Firstly, existing Electrocardiogram (ECG) datasets consistently demonstrate imbalances and biases across various modalities. Secondly, these time-series data consist of diverse lead signals, causing Convolutional Neural Networks (CNNs) to become overfitting to the one with higher power, hence diminishing the performance of the Deep Learning (DL) process. In addition, when facing an imbalanced dataset, performance from such high-dimensional data may be susceptible to overfitting. Current efforts predominantly focus on enhancing DL models by designing novel architectures, despite these evident challenges, seemingly overlooking the core issues, therefore hindering advancements in heart disease classification. To address these obstacles, our proposed approach introduces two straightforward and direct methods to enhance the classification tasks. To address the high dimensionality issue, we employ a Channel-wise Magnitude Equalizer (CME) on signal-encoded images. This approach reduces redundancy in the feature data range, highlighting changes in the dataset. Simultaneously, to counteract data imbalance, we propose the Inverted Weight Logarithmic Loss (IWL) to alleviate imbalances among the data. When applying IWL loss, the accuracy of state-of-the-art models (SOTA) increases up to 5% in the CPSC2018 dataset. CME in combination with IWL also surpasses the classification results of other baseline models from 5% to 10%.
United We Stand: Decentralized Multi-Agent Planning With Attrition
Jul 11, 2024



Decentralized planning is a key element of cooperative multi-agent systems for information gathering tasks. However, despite the high frequency of agent failures in realistic large deployment scenarios, current approaches perform poorly in the presence of failures, by not converging at all, and/or by making very inefficient use of resources (e.g. energy). In this work, we propose Attritable MCTS (A-MCTS), a decentralized MCTS algorithm capable of timely and efficient adaptation to changes in the set of active agents. It is based on the use of a global reward function for the estimation of each agent's local contribution, and regret matching for coordination. We evaluate its effectiveness in realistic data-harvesting problems under different scenarios. We show both theoretically and experimentally that A-MCTS enables efficient adaptation even under high failure rates. Results suggest that, in the presence of frequent failures, our solution improves substantially over the best existing approaches in terms of global utility and scalability.
PAT: Pixel-wise Adaptive Training for Long-tailed Segmentation
Apr 09, 2024



Beyond class frequency, we recognize the impact of class-wise relationships among various class-specific predictions and the imbalance in label masks on long-tailed segmentation learning. To address these challenges, we propose an innovative Pixel-wise Adaptive Training (PAT) technique tailored for long-tailed segmentation. PAT has two key features: 1) class-wise gradient magnitude homogenization, and 2) pixel-wise class-specific loss adaptation (PCLA). First, the class-wise gradient magnitude homogenization helps alleviate the imbalance among label masks by ensuring equal consideration of the class-wise impact on model updates. Second, PCLA tackles the detrimental impact of both rare classes within the long-tailed distribution and inaccurate predictions from previous training stages by encouraging learning classes with low prediction confidence and guarding against forgetting classes with high confidence. This combined approach fosters robust learning while preventing the model from forgetting previously learned knowledge. PAT exhibits significant performance improvements, surpassing the current state-of-the-art by 2.2% in the NyU dataset. Moreover, it enhances overall pixel-wise accuracy by 2.85% and intersection over union value by 2.07%, with a particularly notable declination of 0.39% in detecting rare classes compared to Balance Logits Variation, as demonstrated on the three popular datasets, i.e., OxfordPetIII, CityScape, and NYU.
Revisiting LARS for Large Batch Training Generalization of Neural Networks
Sep 25, 2023



LARS and LAMB have emerged as prominent techniques in Large Batch Learning (LBL), ensuring the stability of AI training. One of the primary challenges in LBL is convergence stability, where the AI agent usually gets trapped into the sharp minimizer. Addressing this challenge, a relatively recent technique, known as warm-up, has been employed. However, warm-up lacks a strong theoretical foundation, leaving the door open for further exploration of more efficacious algorithms. In light of this situation, we conduct empirical experiments to analyze the behaviors of the two most popular optimizers in the LARS family: LARS and LAMB, with and without a warm-up strategy. Our analyses give us a comprehension of the novel LARS, LAMB, and the necessity of a warm-up technique in LBL. Building upon these insights, we propose a novel algorithm called Time Varying LARS (TVLARS), which facilitates robust training in the initial phase without the need for warm-up. Experimental evaluation demonstrates that TVLARS achieves competitive results with LARS and LAMB when warm-up is utilized while surpassing their performance without the warm-up technique.
TrAISformer-A generative transformer for AIS trajectory prediction
Sep 08, 2021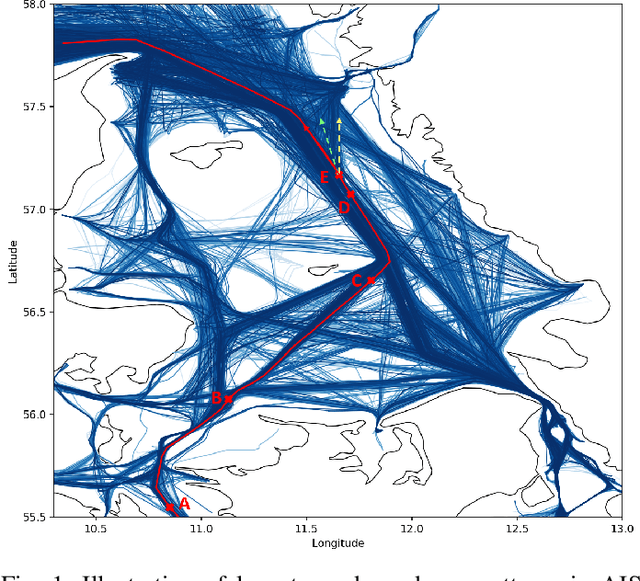
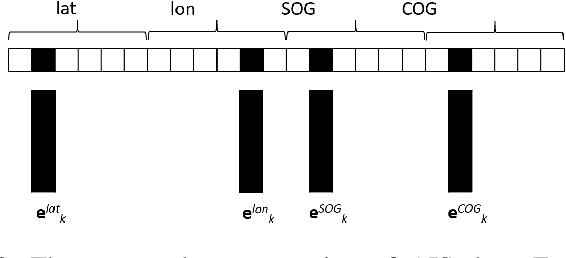
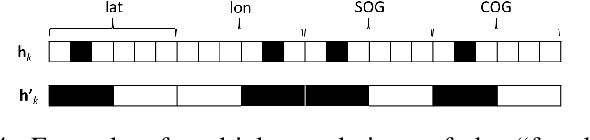
Modelling trajectory in general, and vessel trajectory in particular, is a difficult task because of the multimodal and complex nature of motion data. In this paper, we present TrAISformer-a novel deep learning architecture that can forecast vessel positions using AIS (Automatic Identification System) observations. We address the multimodality by introducing a discrete representation of AIS data and re-frame the prediction, which is originally a regression problem, as a classification problem. The model encodes complex movement patterns in AIS data in high-dimensional vectors, then applies a transformer to extract useful long-term correlations from sequences of those embeddings to sample future vessel positions. Experimental results on real, public AIS data demonstrate that TrAISformer significantly outperforms state-of-the-art methods.
Improving Bayesian Inference in Deep Neural Networks with Variational Structured Dropout
Feb 16, 2021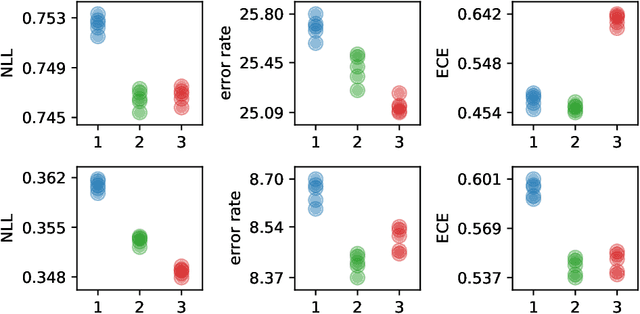
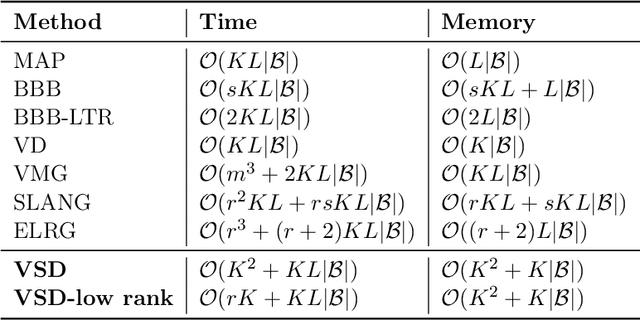
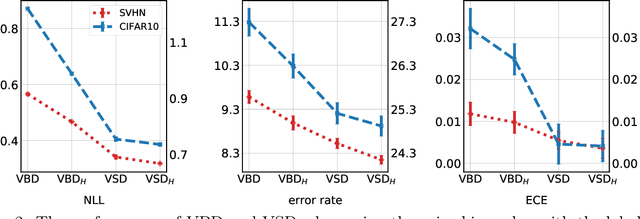
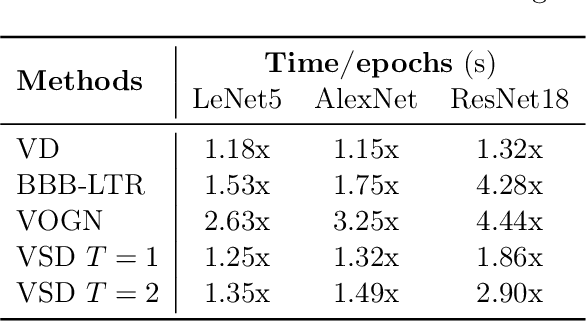
Approximate inference in deep Bayesian networks exhibits a dilemma of how to yield high fidelity posterior approximations while maintaining computational efficiency and scalability. We tackle this challenge by introducing a new variational structured approximation inspired by the interpretation of Dropout training as approximate inference in Bayesian probabilistic models. Concretely, we focus on restrictions of the factorized structure of Dropout posterior which is inflexible to capture rich correlations among weight parameters of the true posterior, and we then propose a novel method called Variational Structured Dropout (VSD) to overcome this limitation. VSD employs an orthogonal transformation to learn a structured representation on the variational Dropout noise and consequently induces statistical dependencies in the approximate posterior. We further gain expressive Bayesian modeling for VSD via proposing a hierarchical Dropout procedure that corresponds to the joint inference in a Bayesian network. Moreover, we can scale up VSD to modern deep convolutional networks in a direct way with a low computational cost. Finally, we conduct extensive experiments on standard benchmarks to demonstrate the effectiveness of VSD over state-of-the-art methods on both predictive accuracy and uncertainty estimation.