 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABIDE
Papers and Code
Fast and Geometrically Grounded Lorentz Neural Networks
Jan 29, 2026Hyperbolic space is quickly gaining traction as a promising geometry for hierarchical and robust representation learning. A core open challenge is the development of a mathematical formulation of hyperbolic neural networks that is both efficient and captures the key properties of hyperbolic space. The Lorentz model of hyperbolic space has been shown to enable both fast forward and backward propagation. However, we prove that, with the current formulation of Lorentz linear layers, the hyperbolic norms of the outputs scale logarithmically with the number of gradient descent steps, nullifying the key advantage of hyperbolic geometry. We propose a new Lorentz linear layer grounded in the well-known ``distance-to-hyperplane" formulation. We prove that our formulation results in the usual linear scaling of output hyperbolic norms with respect to the number of gradient descent steps. Our new formulation, together with further algorithmic efficiencies through Lorentzian activation functions and a new caching strategy results in neural networks fully abiding by hyperbolic geometry while simultaneously bridging the computation gap to Euclidean neural networks. Code available at: https://github.com/robertdvdk/hyperbolic-fully-connected.
PhysicsMind: Sim and Real Mechanics Benchmarking for Physical Reasoning and Prediction in Foundational VLMs and World Models
Jan 22, 2026Modern foundational Multimodal Large Language Models (MLLMs) and video world models have advanced significantly in mathematical, common-sense, and visual reasoning, but their grasp of the underlying physics remains underexplored. Existing benchmarks attempting to measure this matter rely on synthetic, Visual Question Answer templates or focus on perceptual video quality that is tangential to measuring how well the video abides by physical laws. To address this fragmentation, we introduce PhysicsMind, a unified benchmark with both real and simulation environments that evaluates law-consistent reasoning and generation over three canonical principles: Center of Mass, Lever Equilibrium, and Newton's First Law. PhysicsMind comprises two main tasks: i) VQA tasks, testing whether models can reason and determine physical quantities and values from images or short videos, and ii) Video Generation(VG) tasks, evaluating if predicted motion trajectories obey the same center-of-mass, torque, and inertial constraints as the ground truth. A broad range of recent models and video generation models is evaluated on PhysicsMind and found to rely on appearance heuristics while often violating basic mechanics. These gaps indicate that current scaling and training are still insufficient for robust physical understanding, underscoring PhysicsMind as a focused testbed for physics-aware multimodal models. Our data will be released upon acceptance.
ABFR-KAN: Kolmogorov-Arnold Networks for Functional Brain Analysis
Jan 01, 2026Functional connectivity (FC) analysis, a valuable tool for computer-aided brain disorder diagnosis, traditionally relies on atlas-based parcellation. However, issues relating to selection bias and a lack of regard for subject specificity can arise as a result of such parcellations. Addressing this, we propose ABFR-KAN, a transformer-based classification network that incorporates novel advanced brain function representation components with the power of Kolmogorov-Arnold Networks (KANs) to mitigate structural bias, improve anatomical conformity, and enhance the reliability of FC estimation. Extensive experiments on the ABIDE I dataset, including cross-site evaluation and ablation studies across varying model backbones and KAN configurations, demonstrate that ABFR-KAN consistently outperforms state-of-the-art baselines for autism spectrum distorder (ASD) classification. Our code is available at https://github.com/tbwa233/ABFR-KAN.
Discovering Optimal Robust Minimum Redundancy Arrays (RMRAs) through Exhaustive Search and Algebraic Formulation of a New Sub-Optimal RMRA
Dec 30, 2025Modern sparse arrays are maximally economic in that they retain just as many sensors required to provide a specific aperture while maintaining a hole-free difference coarray. As a result, these are susceptible to the failure of even a single sensor. Contrarily, two-fold redundant sparse arrays (TFRSAs) and robust minimum redundancy arrays (RMRAs) ensure robustness against single-sensor failures due to their inherent redundancy in their coarrays. At present, optimal RMRA configurations are known only for arrays with sensor counts N=6 to N=10. To this end, this paper proposes two objectives: (i) developing a systematic algorithm to discover optimal RMRAs for N>10, and (ii) obtaining a new family of near-/sub-optimal RMRA that can be completely specified using closed-form expressions (CFEs). We solve the combinatorial optimization problem of finding RMRAs using an exhaustive search technique implemented in MATLAB. Optimal RMRAs for N = 11 to 14 were successfully found and near/sub-optimal arrays for N = 15 to 20 were determined using the proposed technique. As a byproduct of the exhaustive search, a large catalogue of valid near- and sub-optimal RMRAs was also obtained. In the second stage, CFEs for a new TFRSA were obtained by applying pattern mining and algebraic generalizations to the arrays obtained through exhaustive search. The proposed family enjoys CFEs for sensor positions, available aperture, and achievable degrees of freedom (DOFs). The CFEs have been thoroughly validated using MATLAB and are found to be valid for $N\geq8$. Hence, it can be concluded that the novelty of this work is two-fold: extending the catalogue of known optimal RMRAs and formulating a sub-optimal RMRA that abides by CFEs.
Toward Trustworthy Agentic AI: A Multimodal Framework for Preventing Prompt Injection Attacks
Dec 29, 2025Powerful autonomous systems, which reason, plan, and converse using and between numerous tools and agents, are made possible by Large Language Models (LLMs), Vision-Language Models (VLMs), and new agentic AI systems, like LangChain and GraphChain. Nevertheless, this agentic environment increases the probability of the occurrence of multimodal prompt injection (PI) attacks, in which concealed or malicious instructions carried in text, pictures, metadata, or agent-to-agent messages may spread throughout the graph and lead to unintended behavior, a breach of policy, or corruption of state. In order to mitigate these risks, this paper suggests a Cross-Agent Multimodal Provenanc- Aware Defense Framework whereby all the prompts, either user-generated or produced by upstream agents, are sanitized and all the outputs generated by an LLM are verified independently before being sent to downstream nodes. This framework contains a Text sanitizer agent, visual sanitizer agent, and output validator agent all coordinated by a provenance ledger, which keeps metadata of modality, source, and trust level throughout the entire agent network. This architecture makes sure that agent-to-agent communication abides by clear trust frames such such that injected instructions are not propagated down LangChain or GraphChain-style-workflows. The experimental assessments show that multimodal injection detection accuracy is significantly enhanced, and the cross-agent trust leakage is minimized, as well as, agentic execution pathways become stable. The framework, which expands the concept of provenance tracking and validation to the multi-agent orchestration, enhances the establishment of secure, understandable and reliable agentic AI systems.
CTIGuardian: A Few-Shot Framework for Mitigating Privacy Leakage in Fine-Tuned LLMs
Dec 15, 2025Large Language Models (LLMs) are often fine-tuned to adapt their general-purpose knowledge to specific tasks and domains such as cyber threat intelligence (CTI). Fine-tuning is mostly done through proprietary datasets that may contain sensitive information. Owners expect their fine-tuned model to not inadvertently leak this information to potentially adversarial end users. Using CTI as a use case, we demonstrate that data-extraction attacks can recover sensitive information from fine-tuned models on CTI reports, underscoring the need for mitigation. Retraining the full model to eliminate this leakage is computationally expensive and impractical. We propose an alternative approach, which we call privacy alignment, inspired by safety alignment in LLMs. Just like safety alignment teaches the model to abide by safety constraints through a few examples, we enforce privacy alignment through few-shot supervision, integrating a privacy classifier and a privacy redactor, both handled by the same underlying LLM. We evaluate our system, called CTIGuardian, using GPT-4o mini and Mistral-7B Instruct models, benchmarking against Presidio, a named entity recognition (NER) baseline. Results show that CTIGuardian provides a better privacy-utility trade-off than NER based models. While we demonstrate its effectiveness on a CTI use case, the framework is generic enough to be applicable to other sensitive domains.
Ada-FCN: Adaptive Frequency-Coupled Network for fMRI-Based Brain Disorder Classification
Nov 16, 2025Resting-state fMRI has become a valuable tool for classifying brain disorders and constructing brain functional connectivity networks by tracking BOLD signals across brain regions. However, existing mod els largely neglect the multi-frequency nature of neuronal oscillations, treating BOLD signals as monolithic time series. This overlooks the cru cial fact that neurological disorders often manifest as disruptions within specific frequency bands, limiting diagnostic sensitivity and specificity. While some methods have attempted to incorporate frequency informa tion, they often rely on predefined frequency bands, which may not be optimal for capturing individual variability or disease-specific alterations. To address this, we propose a novel framework featuring Adaptive Cas cade Decomposition to learn task-relevant frequency sub-bands for each brain region and Frequency-Coupled Connectivity Learning to capture both intra- and nuanced cross-band interactions in a unified functional network. This unified network informs a novel message-passing mecha nism within our Unified-GCN, generating refined node representations for diagnostic prediction. Experimental results on the ADNI and ABIDE datasets demonstrate superior performance over existing methods. The code is available at https://github.com/XXYY20221234/Ada-FCN.
* MICCAI2025
Safe and Compliant Cross-Market Trade Execution via Constrained RL and Zero-Knowledge Audits
Oct 06, 2025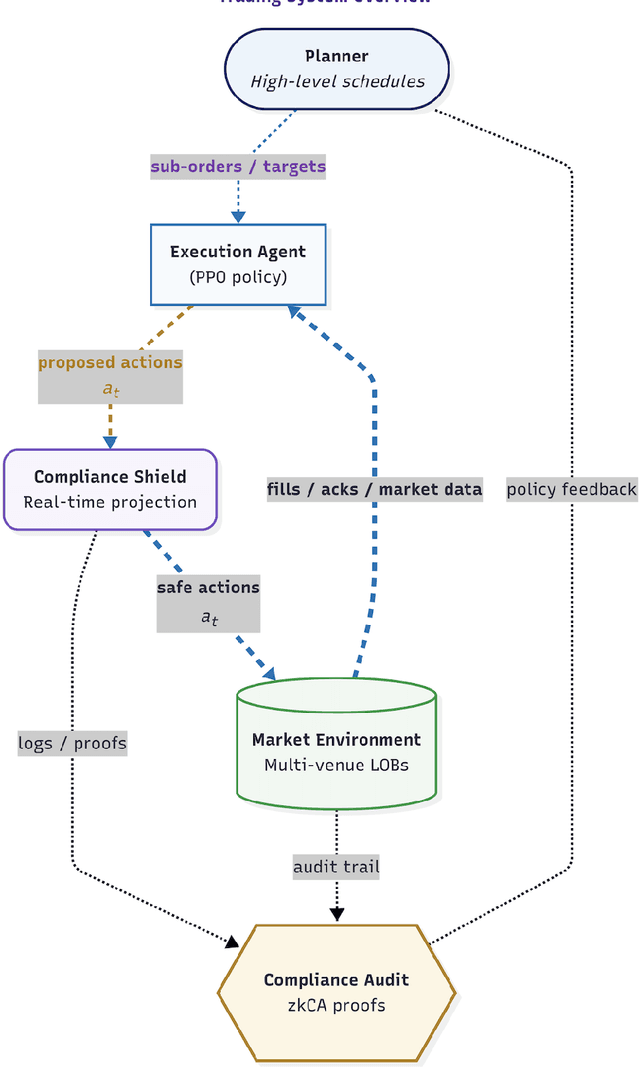
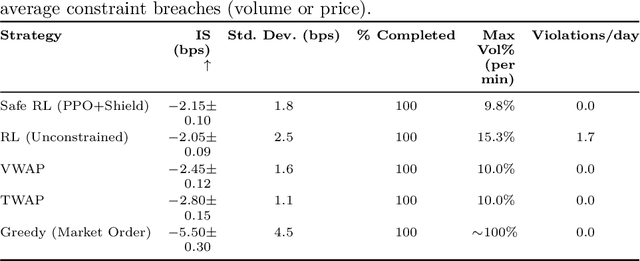
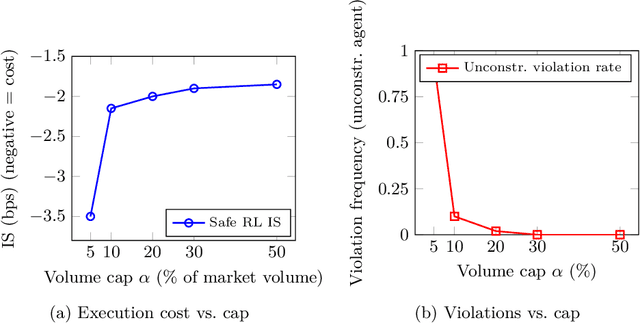
We present a cross-market algorithmic trading system that balances execution quality with rigorous compliance enforcement. The architecture comprises a high-level planner, a reinforcement learning execution agent, and an independent compliance agent. We formulate trade execution as a constrained Markov decision process with hard constraints on participation limits, price bands, and self-trading avoidance. The execution agent is trained with proximal policy optimization, while a runtime action-shield projects any unsafe action into a feasible set. To support auditability without exposing proprietary signals, we add a zero-knowledge compliance audit layer that produces cryptographic proofs that all actions satisfied the constraints. We evaluate in a multi-venue, ABIDES-based simulator and compare against standard baselines (e.g., TWAP, VWAP). The learned policy reduces implementation shortfall and variance while exhibiting no observed constraint violations across stress scenarios including elevated latency, partial fills, compliance module toggling, and varying constraint limits. We report effects at the 95% confidence level using paired t-tests and examine tail risk via CVaR. We situate the work at the intersection of optimal execution, safe reinforcement learning, regulatory technology, and verifiable AI, and discuss ethical considerations, limitations (e.g., modeling assumptions and computational overhead), and paths to real-world deployment.
VarCoNet: A variability-aware self-supervised framework for functional connectome extraction from resting-state fMRI
Oct 02, 2025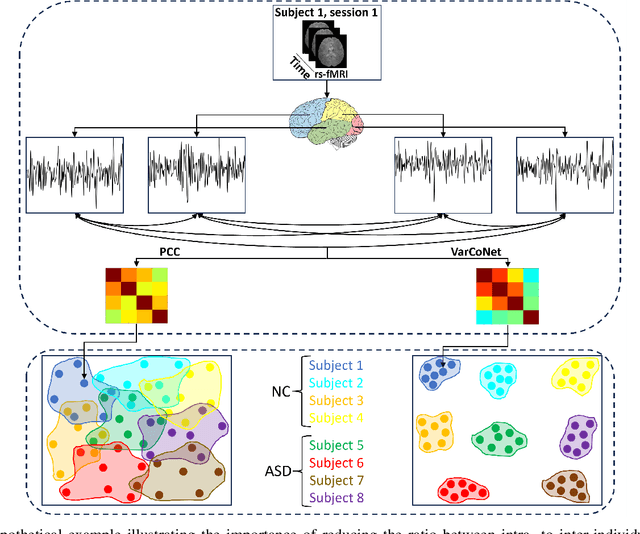
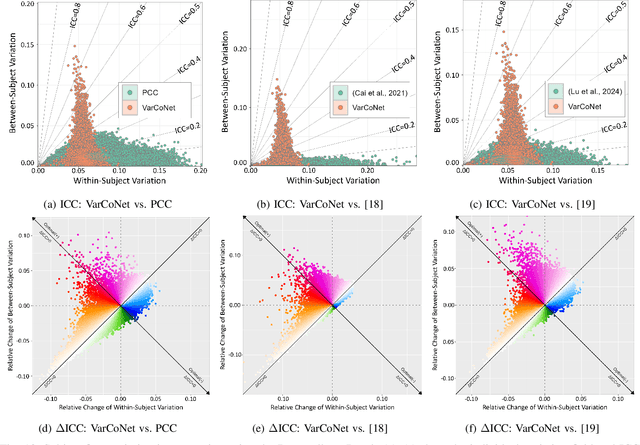
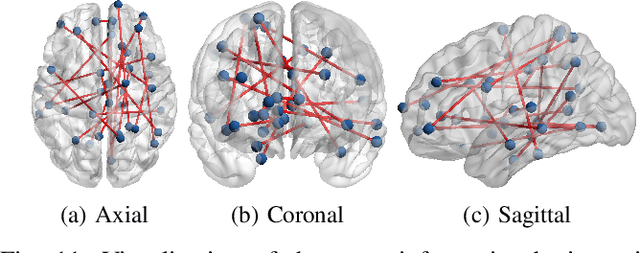
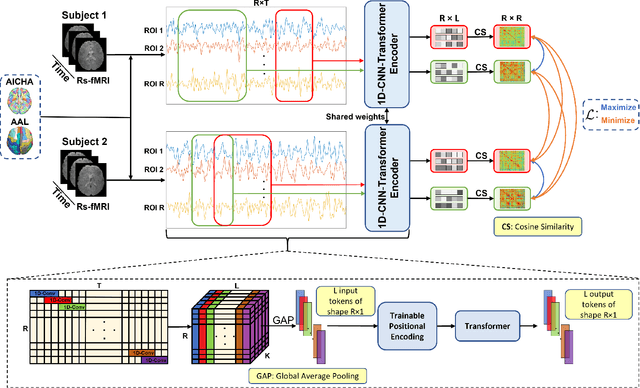
Accounting for inter-individual variability in brain function is key to precision medicine. Here, by considering functional inter-individual variability as meaningful data rather than noise, we introduce VarCoNet, an enhanced self-supervised framework for robust functional connectome (FC) extraction from resting-state fMRI (rs-fMRI) data. VarCoNet employs self-supervised contrastive learning to exploit inherent functional inter-individual variability, serving as a brain function encoder that generates FC embeddings readily applicable to downstream tasks even in the absence of labeled data. Contrastive learning is facilitated by a novel augmentation strategy based on segmenting rs-fMRI signals. At its core, VarCoNet integrates a 1D-CNN-Transformer encoder for advanced time-series processing, enhanced with a robust Bayesian hyperparameter optimization. Our VarCoNet framework is evaluated on two downstream tasks: (i) subject fingerprinting, using rs-fMRI data from the Human Connectome Project, and (ii) autism spectrum disorder (ASD) classification, using rs-fMRI data from the ABIDE I and ABIDE II datasets. Using different brain parcellations, our extensive testing against state-of-the-art methods, including 13 deep learning methods, demonstrates VarCoNet's superiority, robustness, interpretability, and generalizability. Overall, VarCoNet provides a versatile and robust framework for FC analysis in rs-fMRI.
Train-Once Plan-Anywhere Kinodynamic Motion Planning via Diffusion Trees
Aug 28, 2025Kinodynamic motion planning is concerned with computing collision-free trajectories while abiding by the robot's dynamic constraints. This critical problem is often tackled using sampling-based planners (SBPs) that explore the robot's high-dimensional state space by constructing a search tree via action propagations. Although SBPs can offer global guarantees on completeness and solution quality, their performance is often hindered by slow exploration due to uninformed action sampling. Learning-based approaches can yield significantly faster runtimes, yet they fail to generalize to out-of-distribution (OOD) scenarios and lack critical guarantees, e.g., safety, thus limiting their deployment on physical robots. We present Diffusion Tree (DiTree): a \emph{provably-generalizable} framework leveraging diffusion policies (DPs) as informed samplers to efficiently guide state-space search within SBPs. DiTree combines DP's ability to model complex distributions of expert trajectories, conditioned on local observations, with the completeness of SBPs to yield \emph{provably-safe} solutions within a few action propagation iterations for complex dynamical systems. We demonstrate DiTree's power with an implementation combining the popular RRT planner with a DP action sampler trained on a \emph{single environment}. In comprehensive evaluations on OOD scenarios, % DiTree has comparable runtimes to a standalone DP (3x faster than classical SBPs), while improving the average success rate over DP and SBPs. DiTree is on average 3x faster than classical SBPs, and outperforms all other approaches by achieving roughly 30\% higher success rate. Project webpage: https://sites.google.com/view/ditree.