 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Can VLMs Go for Visual Bug Detection? Studying 19,738 Keyframes from 41 Hours of Gameplay Videos
Mar 24, 2026Video-based quality assurance (QA) for long-form gameplay video is labor-intensive and error-prone, yet valuable for assessing game stability and visual correctness over extended play sessions. Vision language models (VLMs) promise general-purpose visual reasoning capabilities and thus appear attractive for detecting visual bugs directly from video frames. Recent benchmarks suggest that VLMs can achieve promising results in detecting visual glitches on curated datasets. Building on these findings, we conduct a real-world study using industrial QA gameplay videos to evaluate how well VLMs perform in practical scenarios. Our study samples keyframes from long gameplay videos and asks a VLM whether each keyframe contains a bug. Starting from a single-prompt baseline, the model achieves a precision of 0.50 and an accuracy of 0.72. We then examine two common enhancement strategies used to improve VLM performance without fine-tuning: (1) a secondary judge model that re-evaluates VLM outputs, and (2) metadata-augmented prompting through the retrieval of prior bug reports. Across \textbf{100 videos} totaling \textbf{41 hours} and \textbf{19,738 keyframes}, these strategies provide only marginal improvements over the simple baseline, while introducing additional computational cost and output variance. Our findings indicate that off-the-shelf VLMs are already capable of detecting a certain range of visual bugs in QA gameplay videos, but further progress likely requires hybrid approaches that better separate textual and visual anomaly detection.
D-GVIO: A Buffer-Driven and Efficient Decentralized GNSS-Visual-Inertial State Estimator for Multi-Agent Systems
Mar 03, 2026Cooperative localization is essential for swarm applications like collaborative exploration and search-and-rescue missions. However, maintaining real-time capability, robustness, and computational efficiency on resource-constrained platforms presents significant challenges. To address these challenges, we propose D-GVIO, a buffer-driven and fully decentralized GNSS-Visual-Inertial Odometry (GVIO) framework that leverages a novel buffering strategy to support efficient and robust distributed state estimation. The proposed framework is characterized by four core mechanisms. Firstly, through covariance segmentation, covariance intersection and buffering strategy, we modularize propagation and update steps in distributed state estimation, significantly reducing computational and communication burdens. Secondly, the left-invariant extended Kalman filter (L-IEKF) is adopted for information fusion, which exhibits superior state estimation performance over the traditional extended Kalman filter (EKF) since its state transition matrix is independent of the system state. Thirdly, a buffer-based re-propagation strategy is employed to handle delayed measurements efficiently and accurately by leveraging the L-IEKF, eliminating the need for costly re-computation. Finally, an adaptive buffer-driven outlier detection method is proposed to dynamically cull GNSS outliers, enhancing robustness in GNSS-challenged environments.
PhysicsMind: Sim and Real Mechanics Benchmarking for Physical Reasoning and Prediction in Foundational VLMs and World Models
Jan 22, 2026Modern foundational Multimodal Large Language Models (MLLMs) and video world models have advanced significantly in mathematical, common-sense, and visual reasoning, but their grasp of the underlying physics remains underexplored. Existing benchmarks attempting to measure this matter rely on synthetic, Visual Question Answer templates or focus on perceptual video quality that is tangential to measuring how well the video abides by physical laws. To address this fragmentation, we introduce PhysicsMind, a unified benchmark with both real and simulation environments that evaluates law-consistent reasoning and generation over three canonical principles: Center of Mass, Lever Equilibrium, and Newton's First Law. PhysicsMind comprises two main tasks: i) VQA tasks, testing whether models can reason and determine physical quantities and values from images or short videos, and ii) Video Generation(VG) tasks, evaluating if predicted motion trajectories obey the same center-of-mass, torque, and inertial constraints as the ground truth. A broad range of recent models and video generation models is evaluated on PhysicsMind and found to rely on appearance heuristics while often violating basic mechanics. These gaps indicate that current scaling and training are still insufficient for robust physical understanding, underscoring PhysicsMind as a focused testbed for physics-aware multimodal models. Our data will be released upon acceptance.
MARec: Metadata Alignment for cold-start Recommendation
Apr 20, 2024



For many recommender systems the primary data source is a historical record of user clicks. The associated click matrix which is often very sparse, however, as the number of users x products can be far larger than the number of clicks, and such sparsity is accentuated in cold-start settings. The sparsity of the click matrix is the reason matrix factorization and autoencoders techniques remain highly competitive across collaborative filtering datasets. In this work, we propose a simple approach to address cold-start recommendations by leveraging content metadata, Metadata Alignment for cold-start Recommendation. we show that this approach can readily augment existing matrix factorization and autoencoder approaches, enabling a smooth transition to top performing algorithms in warmer set-ups. Our experimental results indicate three separate contributions: first, we show that our proposed framework largely beats SOTA results on 4 cold-start datasets with different sparsity and scale characteristics, with gains ranging from +8.4% to +53.8% on reported ranking metrics; second, we provide an ablation study on the utility of semantic features, and proves the additional gain obtained by leveraging such features ranges between +46.8% and +105.5%; and third, our approach is by construction highly competitive in warm set-ups, and we propose a closed-form solution outperformed by SOTA results by only 0.8% on average.
D-Flow: A Real Time Spatial Temporal Model for Target Area Segmentation
Nov 08, 2021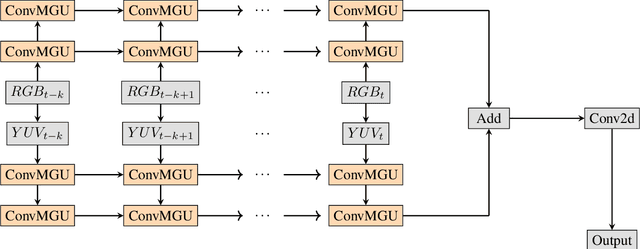
Semantic segmentation has attracted a large amount of attention in recent years. In robotics, segmentation can be used to identify a region of interest, or \emph{target area}. For example, in the RoboCup Standard Platform League (SPL), segmentation separates the soccer field from the background and from players on the field. For satellite or vehicle applications, it is often necessary to find certain regions such as roads, bodies of water or kinds of terrain. In this paper, we propose a novel approach to real-time target area segmentation based on a newly designed spatial temporal network. The method operates under domain constraints defined by both the robot's hardware and its operating environment . The proposed network is able to run in real-time, working within the constraints of limited run time and computing power. This work is compared against other real time segmentation methods on a dataset generated by a Nao V6 humanoid robot simulating the RoboCup SPL competition. In this case, the target area is defined as the artificial grass field. The method is also tested on a maritime dataset collected by a moving vessel, where the aim is to separate the ocean region from the rest of the image. This dataset demonstrates that the proposed model can generalise to a variety of vision problems.
The rUNSWift SPL Field Segmentation Dataset
Aug 29, 2021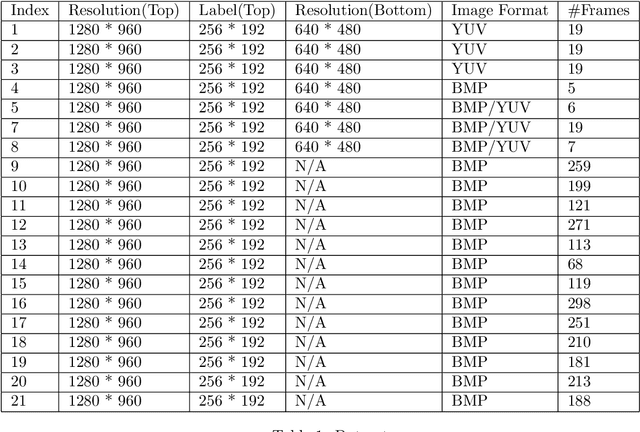

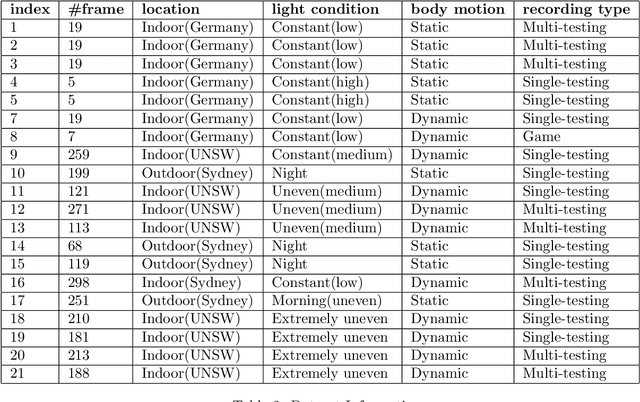

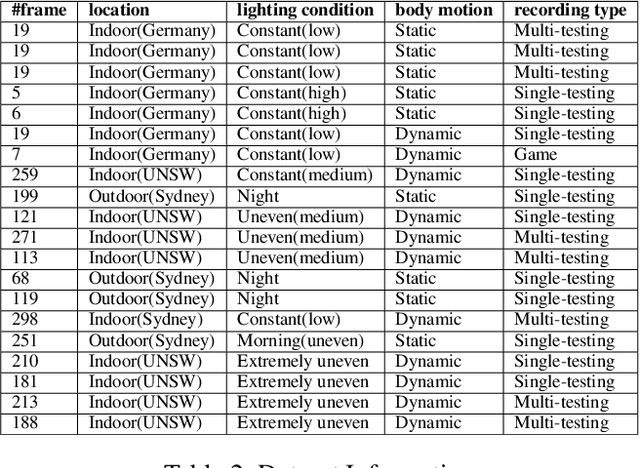
In RoboCup SPL, soccer field segmentation has been widely recognised as one of the most critical robot vision problems. Key challenges include dynamic light condition, different calibration status for individual robot, various camera prospective and more. In this paper, we propose a dataset that contains 20 videos recorded with Nao V5/V6 humanroid robots by team rUNSWift under different circumstances. Each of the videos contains several consecutive high resolution frames and the corresponding labels for field. We propose this dataset to provide training data for the league to overcome field segmentation problem. The dataset will be available online for download. Details of annotation and example of usage will be explained in later sections.