 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocRED: A Large-Scale Document-Level Relation Extraction Dataset
Paper and Code

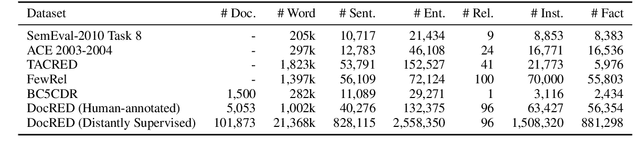

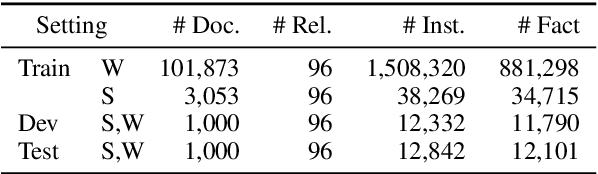
Multiple entities in a document generally exhibit complex inter-sentence relations, and cannot be well handled by existing relation extraction (RE) methods that typically focus on extracting intra-sentence relations for single entity pairs. In order to accelerate the research on document-level RE, we introduce DocRED, a new dataset constructed from Wikipedia and Wikidata with three features: (1) DocRED annotates both named entities and relations, and is the largest human-annotated dataset for document-level RE from plain text; (2) DocRED requires reading multiple sentences in a document to extract entities and infer their relations by synthesizing all information of the document; (3) along with the human-annotated data, we also offer large-scale distantly supervised data, which enables DocRED to be adopted for both supervised and weakly supervised scenarios. In order to verify the challenges of document-level RE, we implement recent state-of-the-art methods for RE and conduct a thorough evaluation of these methods on DocRED. Empirical results show that DocRED is challenging for existing RE methods, which indicates that document-level RE remains an open problem and requires further efforts. Based on the detailed analysis on the experiments, we discuss multiple promising directions for future research.