 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacter Matters: Video Story Understanding with Character-Aware Relations
May 09, 2020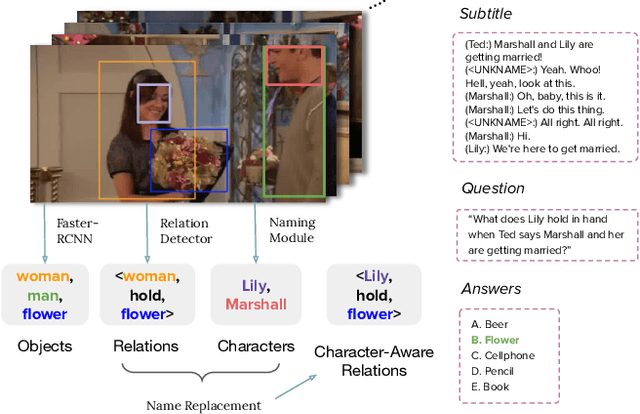
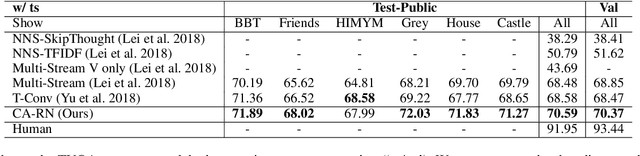
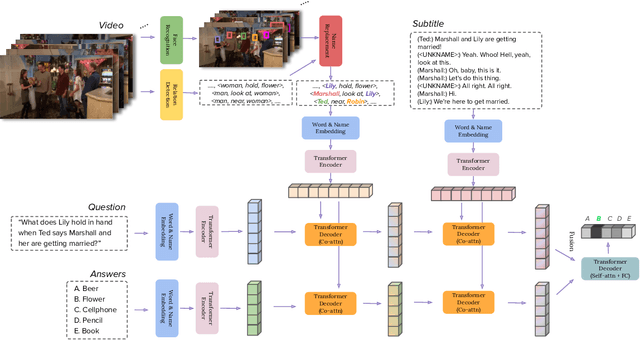
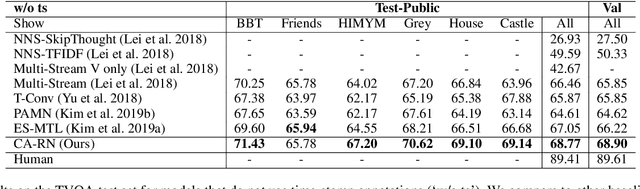
Different from short videos and GIFs, video stories contain clear plots and lists of principal characters. Without identifying the connection between appearing people and character names, a model is not able to obtain a genuine understanding of the plots. Video Story Question Answering (VSQA) offers an effective way to benchmark higher-level comprehension abilities of a model. However, current VSQA methods merely extract generic visual features from a scene. With such an approach, they remain prone to learning just superficial correlations. In order to attain a genuine understanding of who did what to whom, we propose a novel model that continuously refines character-aware relations. This model specifically considers the characters in a video story, as well as the relations connecting different characters and objects. Based on these signals, our framework enables weakly-supervised face naming through multi-instance co-occurrence matching and supports high-level reasoning utilizing Transformer structures. We train and test our model on the six diverse TV shows in the TVQA dataset, which is by far the largest and only publicly available dataset for VSQA. We validate our proposed approach over TVQA dataset through extensive ablation study.
ABSent: Cross-Lingual Sentence Representation Mapping with Bidirectional GANs
Jan 29, 2020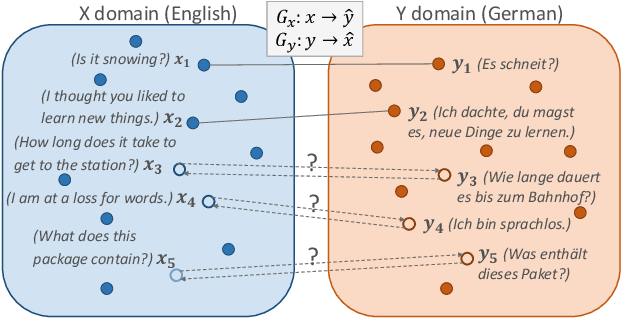
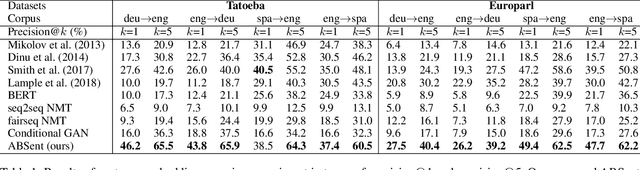
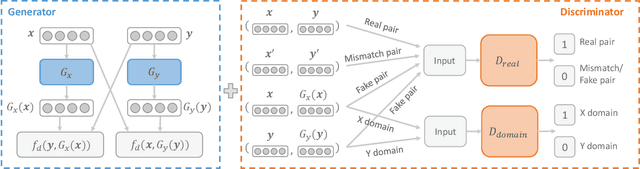
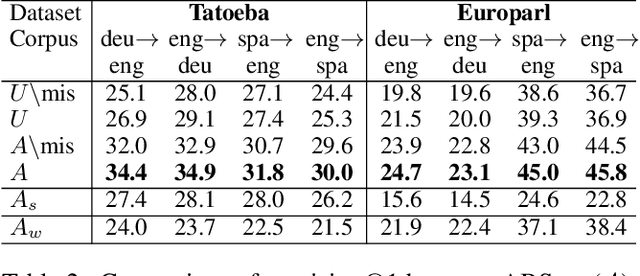
A number of cross-lingual transfer learning approaches based on neural networks have been proposed for the case when large amounts of parallel text are at our disposal. However, in many real-world settings, the size of parallel annotated training data is restricted. Additionally, prior cross-lingual mapping research has mainly focused on the word level. This raises the question of whether such techniques can also be applied to effortlessly obtain cross-lingually aligned sentence representations. To this end, we propose an Adversarial Bi-directional Sentence Embedding Mapping (ABSent) framework, which learns mappings of cross-lingual sentence representations from limited quantities of parallel data.
Reinforcement Knowledge Graph Reasoning for Explainable Recommendation
Jun 12, 2019
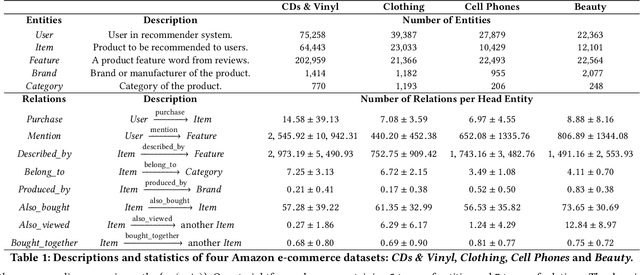
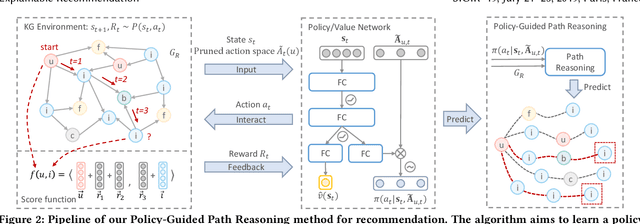
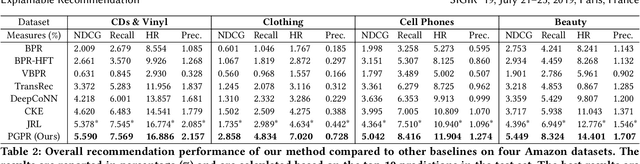
Recent advances in personalized recommendation have sparked great interest in the exploitation of rich structured information provided by knowledge graphs. Unlike most existing approaches that only focus on leveraging knowledge graphs for more accurate recommendation, we perform explicit reasoning with knowledge for decision making so that the recommendations are generated and supported by an interpretable causal inference procedure. To this end, we propose a method called Policy-Guided Path Reasoning (PGPR), which couples recommendation and interpretability by providing actual paths in a knowledge graph. Our contributions include four aspects. We first highlight the significance of incorporating knowledge graphs into recommendation to formally define and interpret the reasoning process. Second, we propose a reinforcement learning (RL) approach featuring an innovative soft reward strategy, user-conditional action pruning and a multi-hop scoring function. Third, we design a policy-guided graph search algorithm to efficiently and effectively sample reasoning paths for recommendation. Finally, we extensively evaluate our method on several large-scale real-world benchmark datasets, obtaining favorable results compared with state-of-the-art methods.
OOGAN: Disentangling GAN with One-Hot Sampling and Orthogonal Regularization
May 26, 2019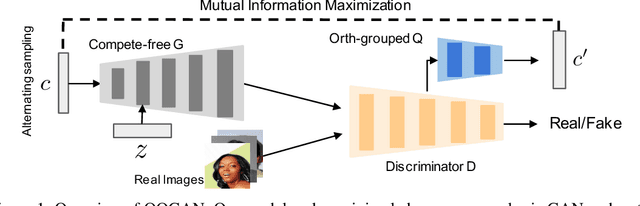


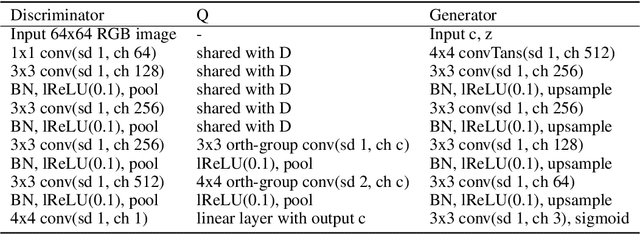
Exploring the potential of GANs for unsupervised disentanglement learning, this paper proposes a novel framework called OOGAN. While previous work mostly attempts to tackle disentanglement learning through VAE and seeks to minimize the Total Correlation (TC) objective with various sorts of approximation methods, we show that GANs have a natural advantage in disentangling with a straightforward latent variable sampling method. Furthermore, we provide a brand-new perspective on designing the structure of the generator and discriminator, demonstrating that a minor structural change and an orthogonal regularization on model weights entails improved disentanglement learning. Our experiments on several visual datasets confirm the effectiveness and superiority of this approach.