 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Identity-Aware Learning for Multi-Agent Value Decomposition
Nov 23, 2022



Value Decomposition (VD) aims to deduce the contributions of agents for decentralized policies in the presence of only global rewards, and has recently emerged as a powerful credit assignment paradigm for tackling cooperative Multi-Agent Reinforcement Learning (MARL) problems. One of the main challenges in VD is to promote diverse behaviors among agents, while existing methods directly encourage the diversity of learned agent networks with various strategies. However, we argue that these dedicated designs for agent networks are still limited by the indistinguishable VD network, leading to homogeneous agent behaviors and thus downgrading the cooperation capability. In this paper, we propose a novel Contrastive Identity-Aware learning (CIA) method, explicitly boosting the credit-level distinguishability of the VD network to break the bottleneck of multi-agent diversity. Specifically, our approach leverages contrastive learning to maximize the mutual information between the temporal credits and identity representations of different agents, encouraging the full expressiveness of credit assignment and further the emergence of individualities. The algorithm implementation of the proposed CIA module is simple yet effective that can be readily incorporated into various VD architectures. Experiments on the SMAC benchmarks and across different VD backbones demonstrate that the proposed method yields results superior to the state-of-the-art counterparts. Our code is available at https://github.com/liushunyu/CIA.
Federated Selective Aggregation for Knowledge Amalgamation
Jul 27, 2022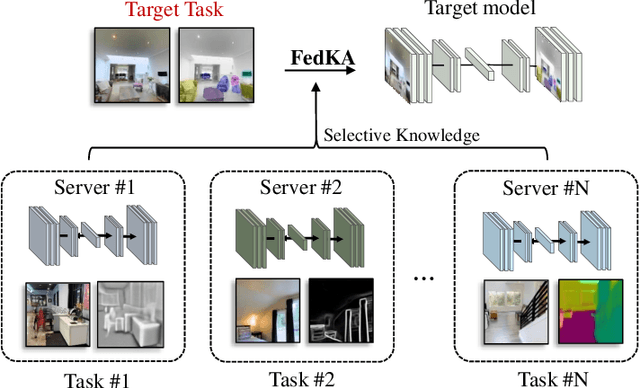
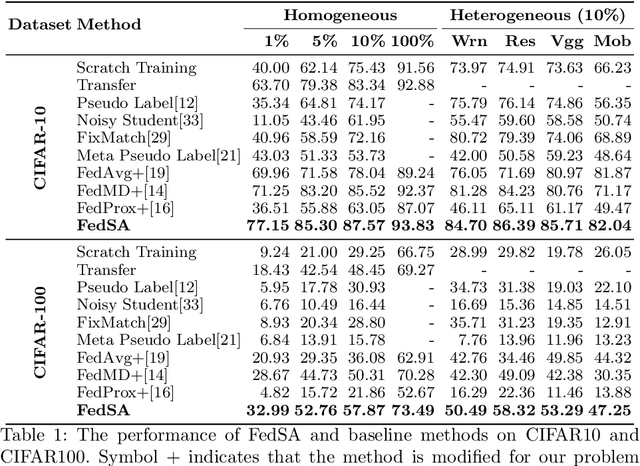
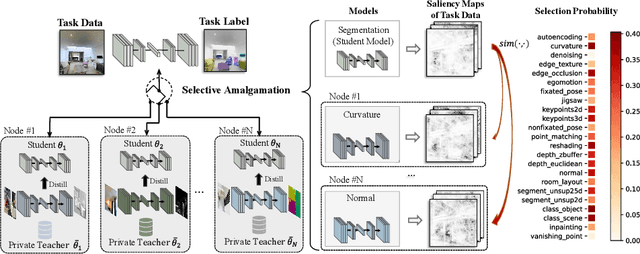
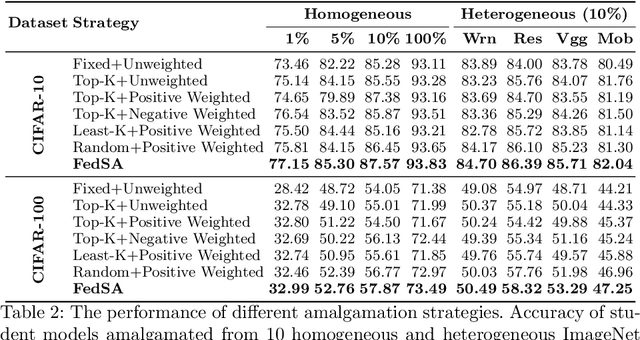
In this paper, we explore a new knowledge-amalgamation problem, termed Federated Selective Aggregation (FedSA). The goal of FedSA is to train a student model for a new task with the help of several decentralized teachers, whose pre-training tasks and data are different and agnostic. Our motivation for investigating such a problem setup stems from a recent dilemma of model sharing. Many researchers or institutes have spent enormous resources on training large and competent networks. Due to the privacy, security, or intellectual property issues, they are, however, not able to share their own pre-trained models, even if they wish to contribute to the community. The proposed FedSA offers a solution to this dilemma and makes it one step further since, again, the learned student may specialize in a new task different from all of the teachers. To this end, we proposed a dedicated strategy for handling FedSA. Specifically, our student-training process is driven by a novel saliency-based approach that adaptively selects teachers as the participants and integrates their representative capabilities into the student. To evaluate the effectiveness of FedSA, we conduct experiments on both single-task and multi-task settings. Experimental results demonstrate that FedSA effectively amalgamates knowledge from decentralized models and achieves competitive performance to centralized baselines.
Mid-level Representation Enhancement and Graph Embedded Uncertainty Suppressing for Facial Expression Recognition
Jul 27, 2022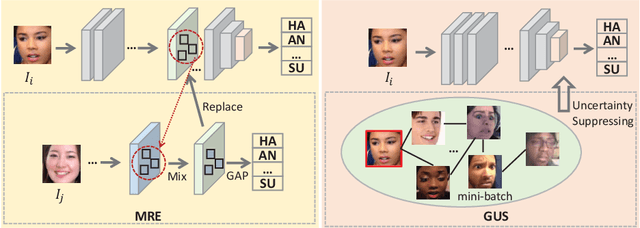
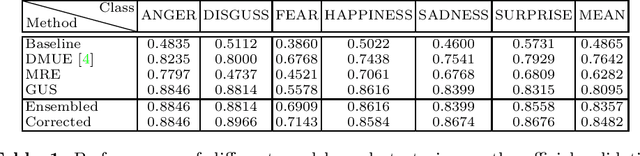
Facial expression is an essential factor in conveying human emotional states and intentions. Although remarkable advancement has been made in facial expression recognition (FER) task, challenges due to large variations of expression patterns and unavoidable data uncertainties still remain. In this paper, we propose mid-level representation enhancement (MRE) and graph embedded uncertainty suppressing (GUS) addressing these issues. On one hand, MRE is introduced to avoid expression representation learning being dominated by a limited number of highly discriminative patterns. On the other hand, GUS is introduced to suppress the feature ambiguity in the representation space. The proposed method not only has stronger generalization capability to handle different variations of expression patterns but also more robustness to capture expression representations. Experimental evaluation on Aff-Wild2 have verified the effectiveness of the proposed method.
Interaction Pattern Disentangling for Multi-Agent Reinforcement Learning
Jul 08, 2022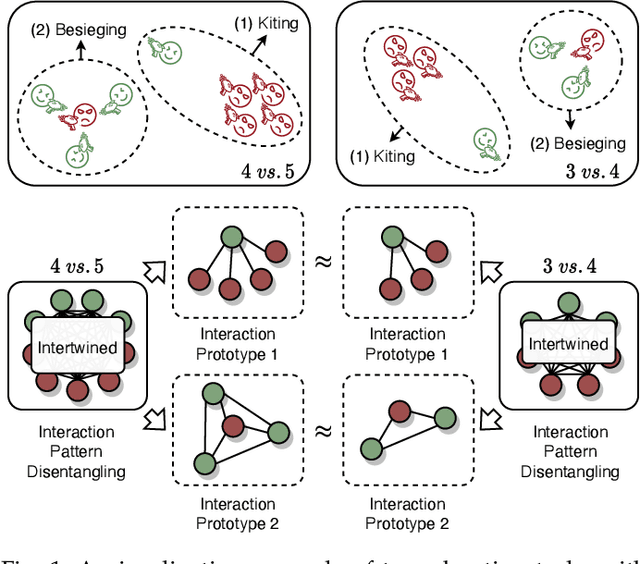
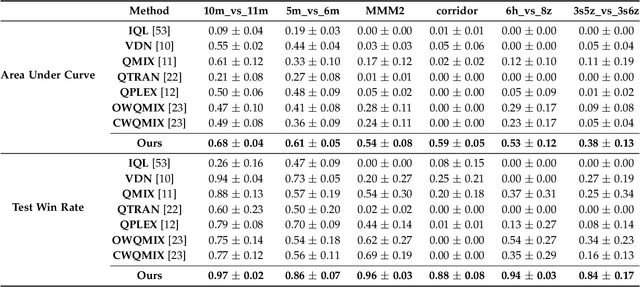
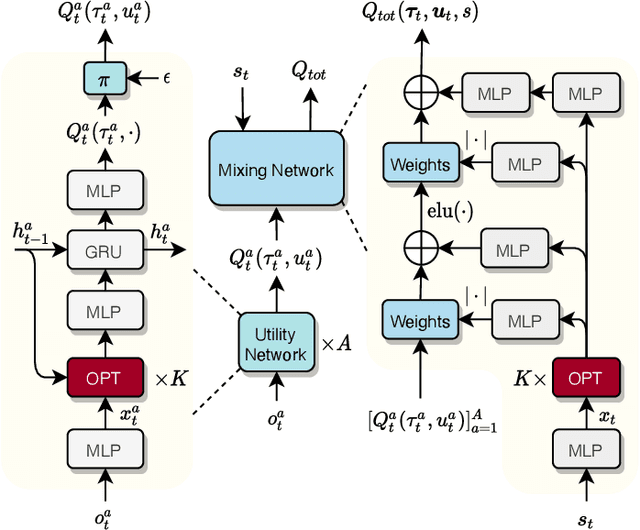
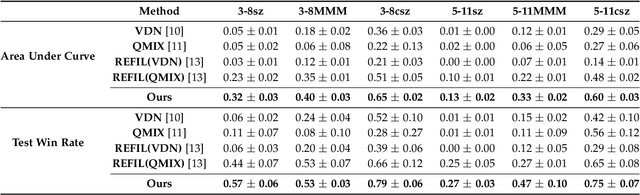
Deep cooperative multi-agent reinforcement learning has demonstrated its remarkable success over a wide spectrum of complex control tasks. However, recent advances in multi-agent learning mainly focus on value decomposition while leaving entity interactions still intertwined, which easily leads to over-fitting on noisy interactions between entities. In this work, we introduce a novel interactiOn Pattern disenTangling (OPT) method, to disentangle not only the joint value function into agent-wise value functions for decentralized execution, but also the entity interactions into interaction prototypes, each of which represents an underlying interaction pattern within a sub-group of the entities. OPT facilitates filtering the noisy interactions between irrelevant entities and thus significantly improves generalizability as well as interpretability. Specifically, OPT introduces a sparse disagreement mechanism to encourage sparsity and diversity among discovered interaction prototypes. Then the model selectively restructures these prototypes into a compact interaction pattern by an aggregator with learnable weights. To alleviate the training instability issue caused by partial observability, we propose to maximize the mutual information between the aggregation weights and the history behaviors of each agent. Experiments on both single-task and multi-task benchmarks demonstrate that the proposed method yields results superior to the state-of-the-art counterparts. Our code will be made publicly available.
Ask-AC: An Initiative Advisor-in-the-Loop Actor-Critic Framework
Jul 05, 2022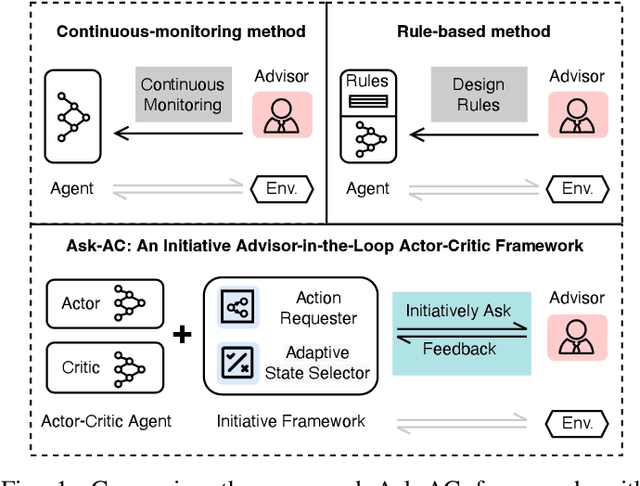
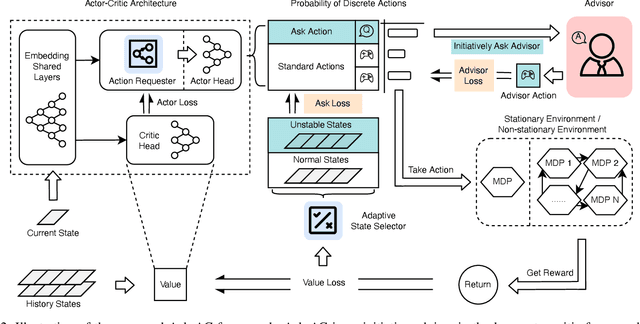
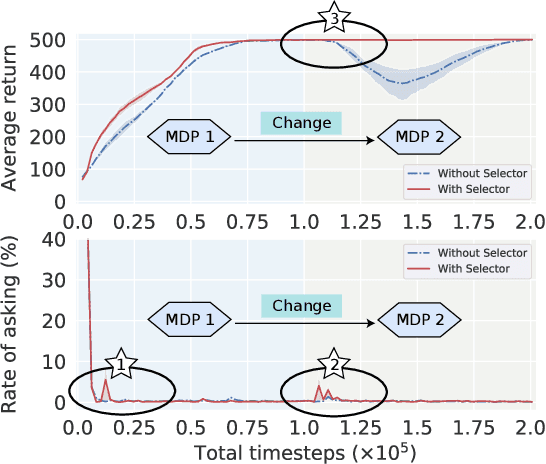
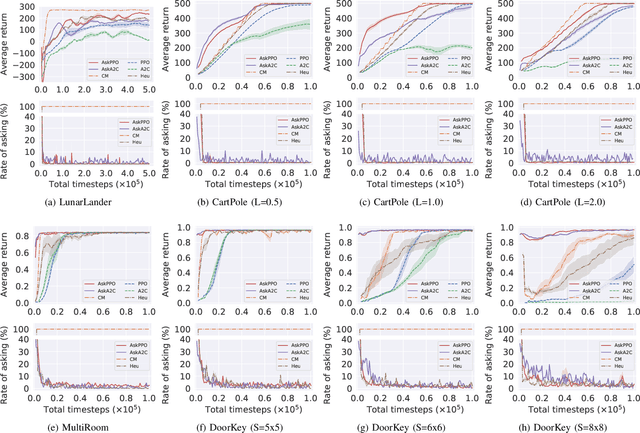
Despite the promising results achieved, state-of-the-art interactive reinforcement learning schemes rely on passively receiving supervision signals from advisor experts, in the form of either continuous monitoring or pre-defined rules, which inevitably result in a cumbersome and expensive learning process. In this paper, we introduce a novel initiative advisor-in-the-loop actor-critic framework, termed as Ask-AC, that replaces the unilateral advisor-guidance mechanism with a bidirectional learner-initiative one, and thereby enables a customized and efficacious message exchange between learner and advisor. At the heart of Ask-AC are two complementary components, namely action requester and adaptive state selector, that can be readily incorporated into various discrete actor-critic architectures. The former component allows the agent to initiatively seek advisor intervention in the presence of uncertain states, while the latter identifies the unstable states potentially missed by the former especially when environment changes, and then learns to promote the ask action on such states. Experimental results on both stationary and non-stationary environments and across different actor-critic backbones demonstrate that the proposed framework significantly improves the learning efficiency of the agent, and achieves the performances on par with those obtained by continuous advisor monitoring.
Distribution-Aware Graph Representation Learning for Transient Stability Assessment of Power System
May 12, 2022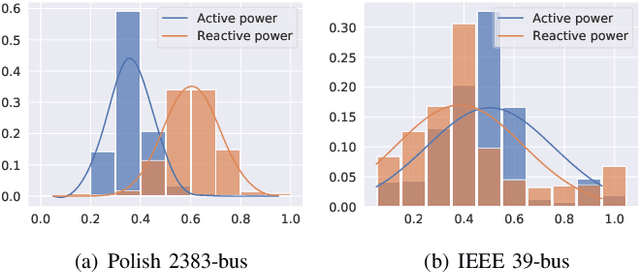
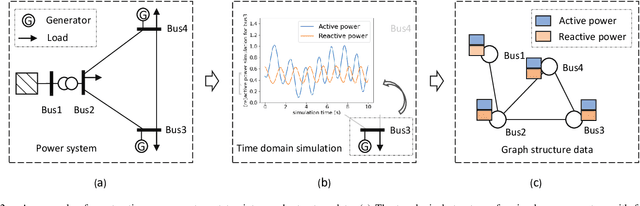
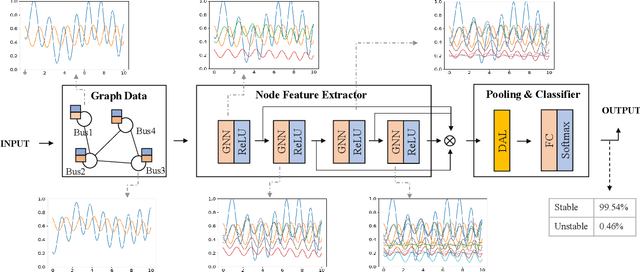
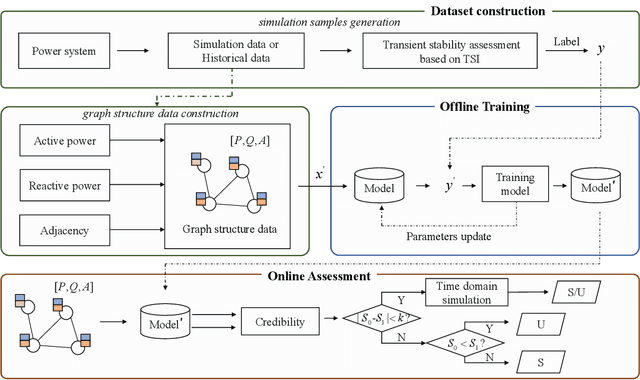
The real-time transient stability assessment (TSA) plays a critical role in the secure operation of the power system. Although the classic numerical integration method, \textit{i.e.} time-domain simulation (TDS), has been widely used in industry practice, it is inevitably trapped in a high computational complexity due to the high latitude sophistication of the power system. In this work, a data-driven power system estimation method is proposed to quickly predict the stability of the power system before TDS reaches the end of simulating time windows, which can reduce the average simulation time of stability assessment without loss of accuracy. As the topology of the power system is in the form of graph structure, graph neural network based representation learning is naturally suitable for learning the status of the power system. Motivated by observing the distribution information of crucial active power and reactive power on the power system's bus nodes, we thus propose a distribution-aware learning~(DAL) module to explore an informative graph representation vector for describing the status of a power system. Then, TSA is re-defined as a binary classification task, and the stability of the system is determined directly from the resulting graph representation without numerical integration. Finally, we apply our method to the online TSA task. The case studies on the IEEE 39-bus system and Polish 2383-bus system demonstrate the effectiveness of our proposed method.
Comparison Knowledge Translation for Generalizable Image Classification
May 07, 2022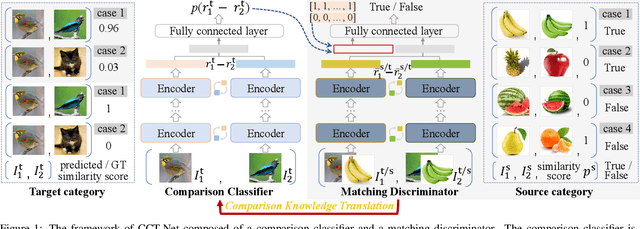
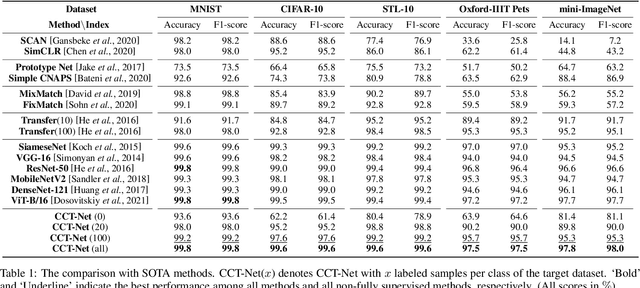
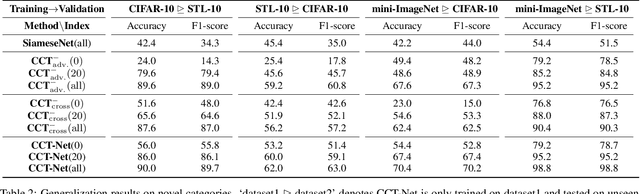
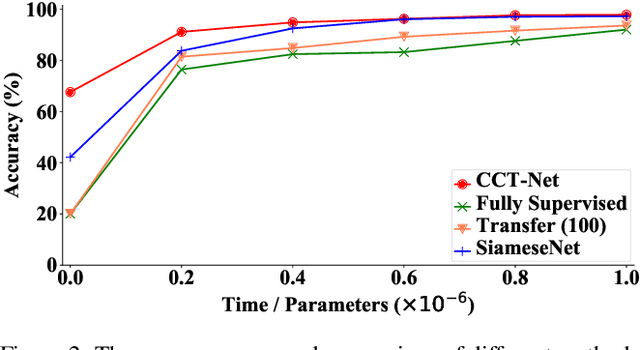
Deep learning has recently achieved remarkable performance in image classification tasks, which depends heavily on massive annotation. However, the classification mechanism of existing deep learning models seems to contrast to humans' recognition mechanism. With only a glance at an image of the object even unknown type, humans can quickly and precisely find other same category objects from massive images, which benefits from daily recognition of various objects. In this paper, we attempt to build a generalizable framework that emulates the humans' recognition mechanism in the image classification task, hoping to improve the classification performance on unseen categories with the support of annotations of other categories. Specifically, we investigate a new task termed Comparison Knowledge Translation (CKT). Given a set of fully labeled categories, CKT aims to translate the comparison knowledge learned from the labeled categories to a set of novel categories. To this end, we put forward a Comparison Classification Translation Network (CCT-Net), which comprises a comparison classifier and a matching discriminator. The comparison classifier is devised to classify whether two images belong to the same category or not, while the matching discriminator works together in an adversarial manner to ensure whether classified results match the truth. Exhaustive experiments show that CCT-Net achieves surprising generalization ability on unseen categories and SOTA performance on target categories.
CNN LEGO: Disassembling and Assembling Convolutional Neural Network
Mar 25, 2022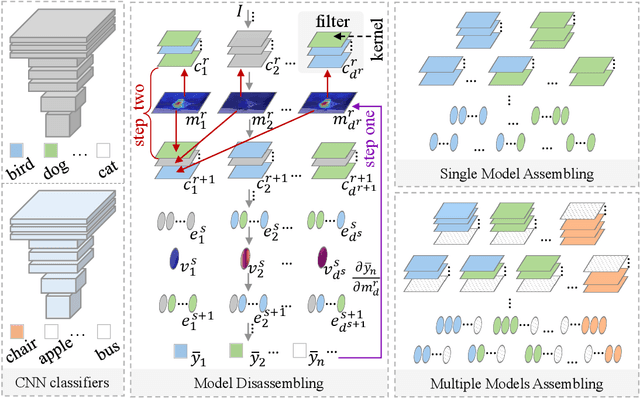
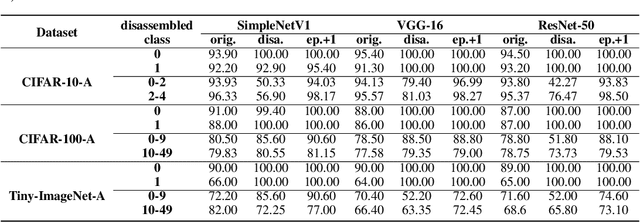
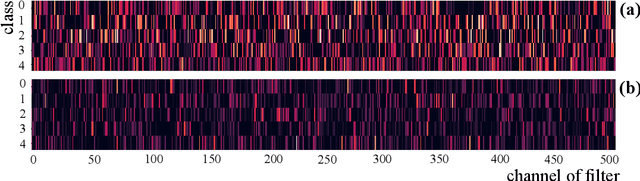
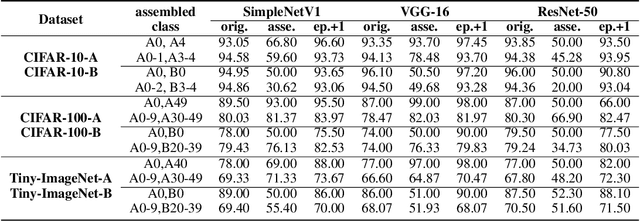
Convolutional Neural Network (CNN), which mimics human visual perception mechanism, has been successfully used in many computer vision areas. Some psychophysical studies show that the visual perception mechanism synchronously processes the form, color, movement, depth, etc., in the initial stage [7,20] and then integrates all information for final recognition [38]. What's more, the human visual system [20] contains different subdivisions or different tasks. Inspired by the above visual perception mechanism, we investigate a new task, termed as Model Disassembling and Assembling (MDA-Task), which can disassemble the deep models into independent parts and assemble those parts into a new deep model without performance cost like playing LEGO toys. To this end, we propose a feature route attribution technique (FRAT) for disassembling CNN classifiers in this paper. In FRAT, the positive derivatives of predicted class probability w.r.t. the feature maps are adopted to locate the critical features in each layer. Then, relevance analysis between the critical features and preceding/subsequent parameter layers is adopted to bridge the route between two adjacent parameter layers. In the assembling phase, class-wise components of each layer are assembled into a new deep model for a specific task. Extensive experiments demonstrate that the assembled CNN classifier can achieve close accuracy with the original classifier without any fine-tune, and excess original performance with one-epoch fine-tune. What's more, we also conduct massive experiments to verify the broad application of MDA-Task on model decision route visualization, model compression, knowledge distillation, transfer learning, incremental learning, and so on.
Root-aligned SMILES for Molecular Retrosynthesis Prediction
Mar 23, 2022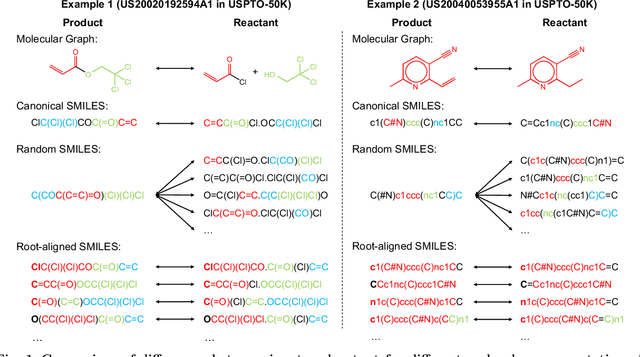
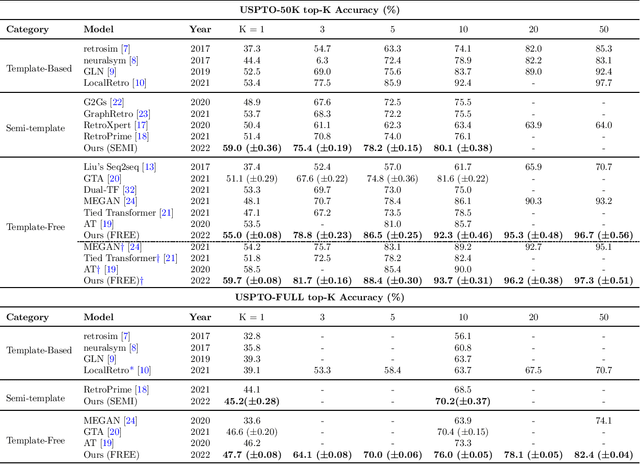
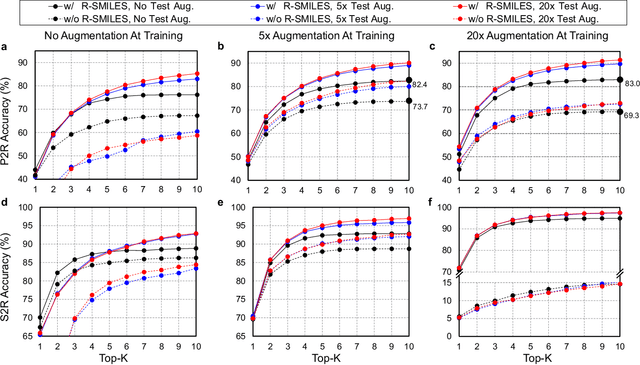
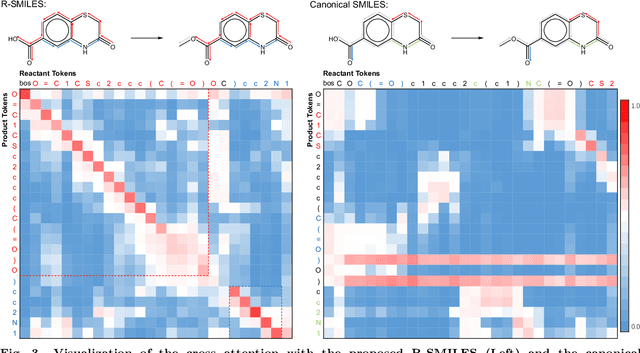
Retrosynthesis prediction is a fundamental problem in organic synthesis, where the task is to discover precursor molecules that can be used to synthesize a target molecule. A popular paradigm of existing computational retrosynthesis methods formulate retrosynthesis prediction as a sequence-to-sequence translation problem, where the typical SMILES representations are adopted for both reactants and products. However, the general-purpose SMILES neglects the characteristics of retrosynthesis that 1) the search space of the reactants is quite huge, and 2) the molecular graph topology is largely unaltered from products to reactants, resulting in the suboptimal performance of SMILES if straightforwardly applied. In this article, we propose the root-aligned SMILES~(R-SMILES), which specifies a tightly aligned one-to-one mapping between the product and the reactant SMILES, to narrow the string representation discrepancy for more efficient retrosynthesis. As the minimum edit distance between the input and the output is significantly decreased with the proposed R-SMILES, the computational model is largely relieved from learning the complex syntax and dedicated to learning the chemical knowledge for retrosynthesis. We compare the proposed R-SMILES with various state-of-the-art baselines on different benchmarks and show that it significantly outperforms them all, demonstrating the superiority of the proposed method.
Knowledge Amalgamation for Object Detection with Transformers
Mar 07, 2022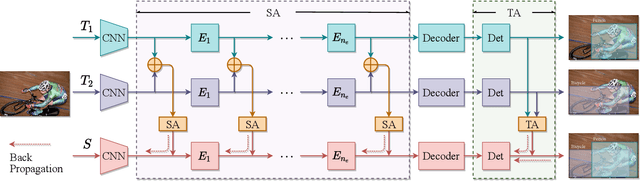
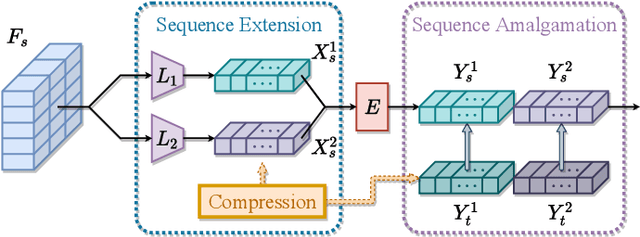

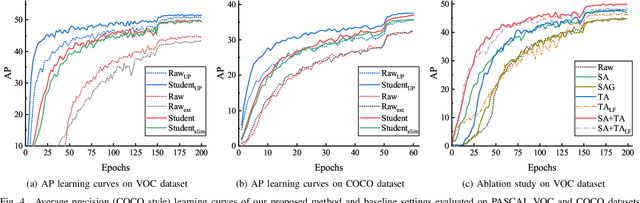
Knowledge amalgamation (KA) is a novel deep model reusing task aiming to transfer knowledge from several well-trained teachers to a multi-talented and compact student. Currently, most of these approaches are tailored for convolutional neural networks (CNNs). However, there is a tendency that transformers, with a completely different architecture, are starting to challenge the domination of CNNs in many computer vision tasks. Nevertheless, directly applying the previous KA methods to transformers leads to severe performance degradation. In this work, we explore a more effective KA scheme for transformer-based object detection models. Specifically, considering the architecture characteristics of transformers, we propose to dissolve the KA into two aspects: sequence-level amalgamation (SA) and task-level amalgamation (TA). In particular, a hint is generated within the sequence-level amalgamation by concatenating teacher sequences instead of redundantly aggregating them to a fixed-size one as previous KA works. Besides, the student learns heterogeneous detection tasks through soft targets with efficiency in the task-level amalgamation. Extensive experiments on PASCAL VOC and COCO have unfolded that the sequence-level amalgamation significantly boosts the performance of students, while the previous methods impair the students. Moreover, the transformer-based students excel in learning amalgamated knowledge, as they have mastered heterogeneous detection tasks rapidly and achieved superior or at least comparable performance to those of the teachers in their specializations.