 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoBiE: Efficient Inference of Mixture of Binary Experts under Post-Training Quantization
Apr 08, 2026Mixture-of-Experts (MoE) based large language models (LLMs) offer strong performance but suffer from high memory and computation costs. Weight binarization provides extreme efficiency, yet existing binary methods designed for dense LLMs struggle with MoE-specific issues, including cross-expert redundancy, task-agnostic importance estimation, and quantization-induced routing shifts. To this end, we propose MoBiE, the first binarization framework tailored for MoE-based LLMs. MoBiE is built on three core innovations: 1. using joint SVD decomposition to reduce cross-expert redundancy; 2. integrating global loss gradients into local Hessian metrics to enhance weight importance estimation; 3. introducing an error constraint guided by the input null space to mitigate routing distortion. Notably, MoBiE achieves these optimizations while incurring no additional storage overhead, striking a balance between efficiency and model performance. Extensive experiments demonstrate that MoBiE consistently outperforms state-of-the-art binary methods across multiple MoE-based LLMs and benchmarks. For example, on Qwen3-30B-A3B, MoBiE reduces perplexity by 52.2$\%$, improves average zero-shot performance by 43.4$\%$, achieves over 2 $\times$ inference speedup, and further shortens quantization time. The code is available at https://github.com/Kishon-zzx/MoBiE.
SpecQuant: Spectral Decomposition and Adaptive Truncation for Ultra-Low-Bit LLMs Quantization
Nov 11, 2025



The emergence of accurate open large language models (LLMs) has sparked a push for advanced quantization techniques to enable efficient deployment on end-user devices. In this paper, we revisit the challenge of extreme LLM compression -- targeting ultra-low-bit quantization for both activations and weights -- from a Fourier frequency domain perspective. We propose SpecQuant, a two-stage framework that tackles activation outliers and cross-channel variance. In the first stage, activation outliers are smoothed and transferred into the weight matrix to simplify downstream quantization. In the second stage, we apply channel-wise low-frequency Fourier truncation to suppress high-frequency components while preserving essential signal energy, improving quantization robustness. Our method builds on the principle that most of the weight energy is concentrated in low-frequency components, which can be retained with minimal impact on model accuracy. To enable runtime adaptability, we introduce a lightweight truncation module during inference that adjusts truncation thresholds based on channel characteristics. On LLaMA-3 8B, SpecQuant achieves 4-bit quantization for both weights and activations, narrowing the zero-shot accuracy gap to only 1.5% compared to full precision, while delivering 2 times faster inference and 3times lower memory usage.
QUARK: Quantization-Enabled Circuit Sharing for Transformer Acceleration by Exploiting Common Patterns in Nonlinear Operations
Nov 10, 2025Transformer-based models have revolutionized computer vision (CV) and natural language processing (NLP) by achieving state-of-the-art performance across a range of benchmarks. However, nonlinear operations in models significantly contribute to inference latency, presenting unique challenges for efficient hardware acceleration. To this end, we propose QUARK, a quantization-enabled FPGA acceleration framework that leverages common patterns in nonlinear operations to enable efficient circuit sharing, thereby reducing hardware resource requirements. QUARK targets all nonlinear operations within Transformer-based models, achieving high-performance approximation through a novel circuit-sharing design tailored to accelerate these operations. Our evaluation demonstrates that QUARK significantly reduces the computational overhead of nonlinear operators in mainstream Transformer architectures, achieving up to a 1.96 times end-to-end speedup over GPU implementations. Moreover, QUARK lowers the hardware overhead of nonlinear modules by more than 50% compared to prior approaches, all while maintaining high model accuracy -- and even substantially boosting accuracy under ultra-low-bit quantization.
Feature functional theory - binding predictor (FFT-BP) for the blind prediction of binding free energies
Mar 31, 2017
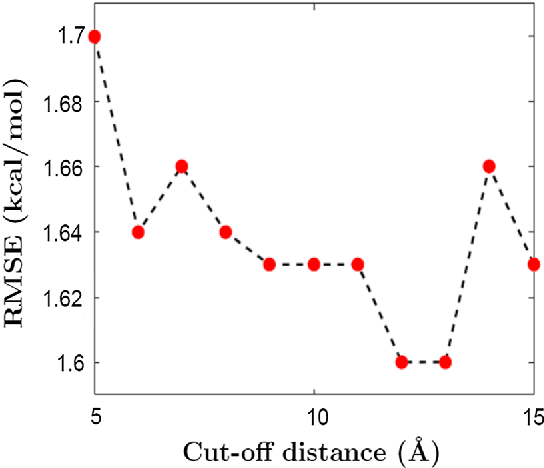
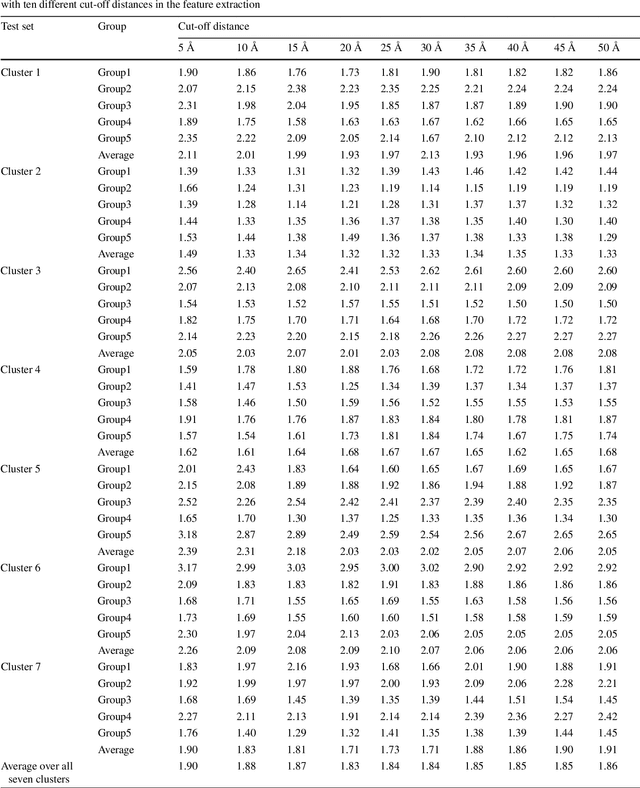
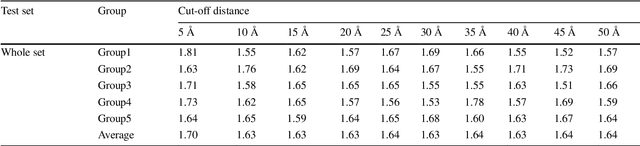
We present a feature functional theory - binding predictor (FFT-BP) for the protein-ligand binding affinity prediction. The underpinning assumptions of FFT-BP are as follows: i) representability: there exists a microscopic feature vector that can uniquely characterize and distinguish one protein-ligand complex from another; ii) feature-function relationship: the macroscopic features, including binding free energy, of a complex is a functional of microscopic feature vectors; and iii) similarity: molecules with similar microscopic features have similar macroscopic features, such as binding affinity. Physical models, such as implicit solvent models and quantum theory, are utilized to extract microscopic features, while machine learning algorithms are employed to rank the similarity among protein-ligand complexes. A large variety of numerical validations and tests confirms the accuracy and robustness of the proposed FFT-BP model. The root mean square errors (RMSEs) of FFT-BP blind predictions of a benchmark set of 100 complexes, the PDBBind v2007 core set of 195 complexes and the PDBBind v2015 core set of 195 complexes are 1.99, 2.02 and 1.92 kcal/mol, respectively. Their corresponding Pearson correlation coefficients are 0.75, 0.80, and 0.78, respectively.