 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregating Nested Transformers
May 26, 2021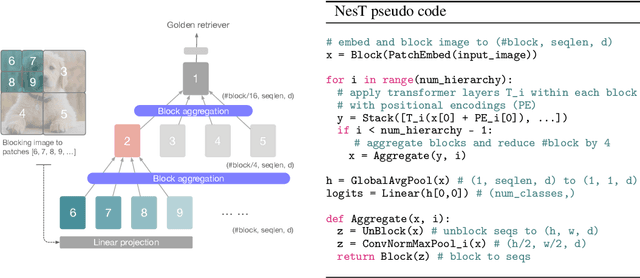
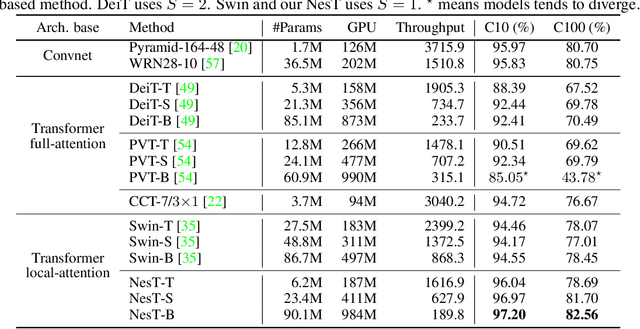
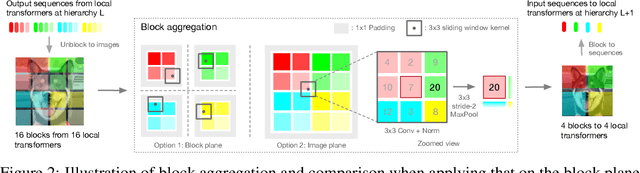
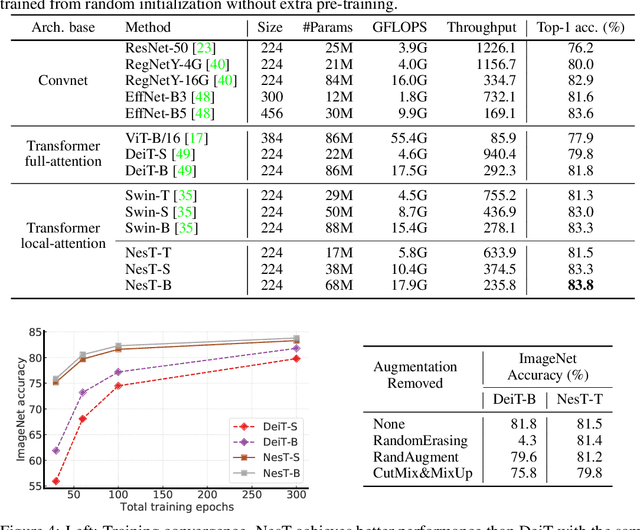
Although hierarchical structures are popular in recent vision transformers, they require sophisticated designs and massive datasets to work well. In this work, we explore the idea of nesting basic local transformers on non-overlapping image blocks and aggregating them in a hierarchical manner. We find that the block aggregation function plays a critical role in enabling cross-block non-local information communication. This observation leads us to design a simplified architecture with minor code changes upon the original vision transformer and obtains improved performance compared to existing methods. Our empirical results show that the proposed method NesT converges faster and requires much less training data to achieve good generalization. For example, a NesT with 68M parameters trained on ImageNet for 100/300 epochs achieves $82.3\%/83.8\%$ accuracy evaluated on $224\times 224$ image size, outperforming previous methods with up to $57\%$ parameter reduction. Training a NesT with 6M parameters from scratch on CIFAR10 achieves $96\%$ accuracy using a single GPU, setting a new state of the art for vision transformers. Beyond image classification, we extend the key idea to image generation and show NesT leads to a strong decoder that is 8$\times$ faster than previous transformer based generators. Furthermore, we also propose a novel method for visually interpreting the learned model.
Learning from Weakly-labeled Web Videos via Exploring Sub-Concepts
Jan 11, 2021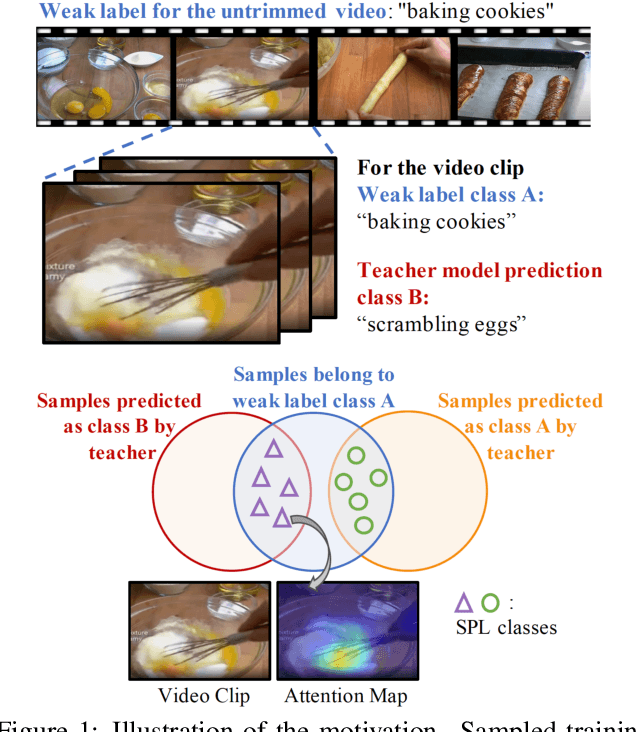
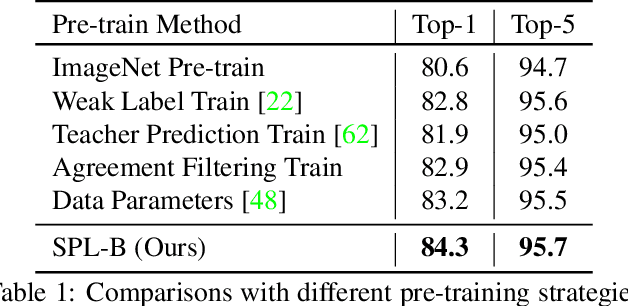
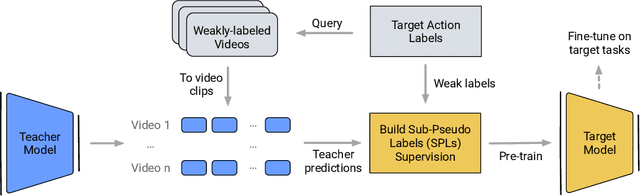
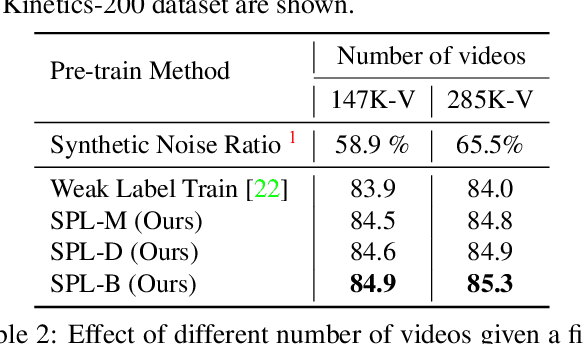
Learning visual knowledge from massive weakly-labeled web videos has attracted growing research interests thanks to the large corpus of easily accessible video data on the Internet. However, for video action recognition, the action of interest might only exist in arbitrary clips of untrimmed web videos, resulting in high label noises in the temporal space. To address this issue, we introduce a new method for pre-training video action recognition models using queried web videos. Instead of trying to filter out, we propose to convert the potential noises in these queried videos to useful supervision signals by defining the concept of Sub-Pseudo Label (SPL). Specifically, SPL spans out a new set of meaningful "middle ground" label space constructed by extrapolating the original weak labels during video querying and the prior knowledge distilled from a teacher model. Consequently, SPL provides enriched supervision for video models to learn better representations. SPL is fairly simple and orthogonal to popular teacher-student self-training frameworks without extra training cost. We validate the effectiveness of our method on four video action recognition datasets and a weakly-labeled image dataset to study the generalization ability. Experiments show that SPL outperforms several existing pre-training strategies using pseudo-labels and the learned representations lead to competitive results when fine-tuning on HMDB-51 and UCF-101 compared with recent pre-training methods.
PseudoSeg: Designing Pseudo Labels for Semantic Segmentation
Oct 19, 2020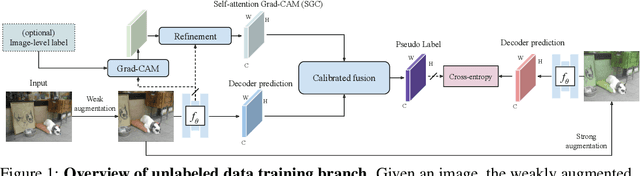
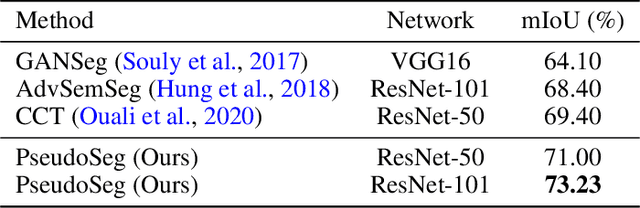

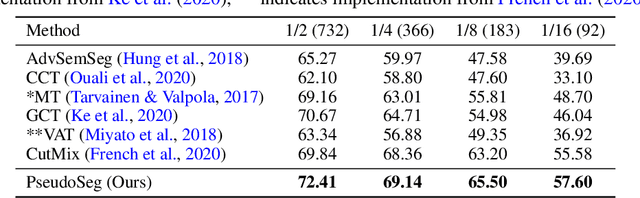
Recent advances in semi-supervised learning (SSL) demonstrate that a combination of consistency regularization and pseudo-labeling can effectively improve image classification accuracy in the low-data regime. Compared to classification, semantic segmentation tasks require much more intensive labeling costs. Thus, these tasks greatly benefit from data-efficient training methods. However, structured outputs in segmentation render particular difficulties (e.g., designing pseudo-labeling and augmentation) to apply existing SSL strategies. To address this problem, we present a simple and novel re-design of pseudo-labeling to generate well-calibrated structured pseudo labels for training with unlabeled or weakly-labeled data. Our proposed pseudo-labeling strategy is network structure agnostic to apply in a one-stage consistency training framework. We demonstrate the effectiveness of the proposed pseudo-labeling strategy in both low-data and high-data regimes. Extensive experiments have validated that pseudo labels generated from wisely fusing diverse sources and strong data augmentation are crucial to consistency training for segmentation. The source code is available at https://github.com/googleinterns/wss.
Image Augmentations for GAN Training
Jun 04, 2020
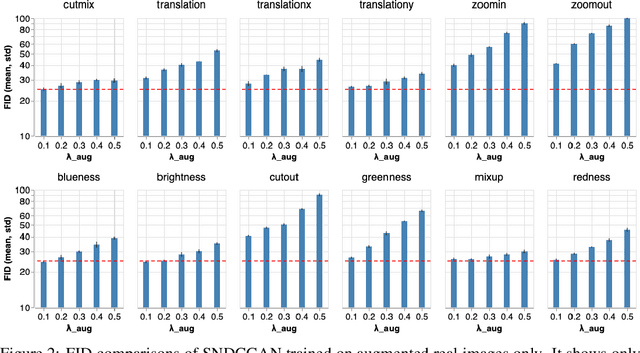
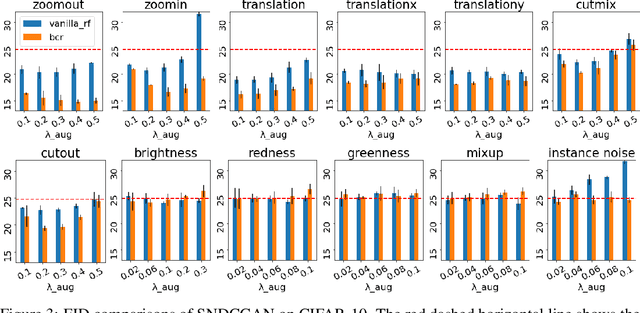
Data augmentations have been widely studied to improve the accuracy and robustness of classifiers. However, the potential of image augmentation in improving GAN models for image synthesis has not been thoroughly investigated in previous studies. In this work, we systematically study the effectiveness of various existing augmentation techniques for GAN training in a variety of settings. We provide insights and guidelines on how to augment images for both vanilla GANs and GANs with regularizations, improving the fidelity of the generated images substantially. Surprisingly, we find that vanilla GANs attain generation quality on par with recent state-of-the-art results if we use augmentations on both real and generated images. When this GAN training is combined with other augmentation-based regularization techniques, such as contrastive loss and consistency regularization, the augmentations further improve the quality of generated images. We provide new state-of-the-art results for conditional generation on CIFAR-10 with both consistency loss and contrastive loss as additional regularizations.
A Simple Semi-Supervised Learning Framework for Object Detection
May 10, 2020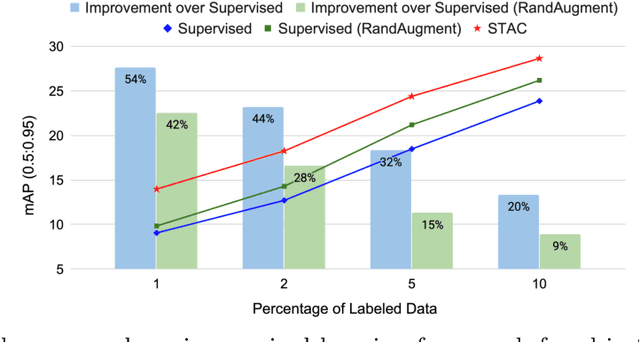
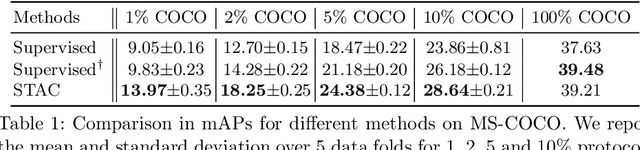
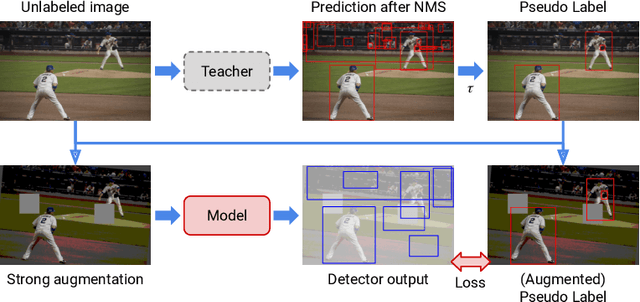
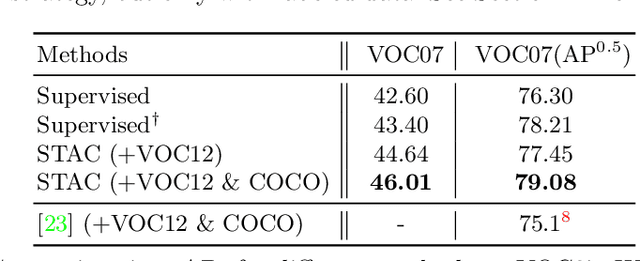
Semi-supervised learning (SSL) has promising potential for improving the predictive performance of machine learning models using unlabeled data. There has been remarkable progress, but the scope of demonstration in SSL has been limited to image classification tasks. In this paper, we propose STAC, a simple yet effective SSL framework for visual object detection along with a data augmentation strategy. STAC deploys highly confident pseudo labels of localized objects from an unlabeled image and updates the model by enforcing consistency via strong augmentations. We propose new experimental protocols to evaluate performance of semi-supervised object detection using MS-COCO and demonstrate the efficacy of STAC on both MS-COCO and VOC07. On VOC07, STAC improves the AP$^{0.5}$ from 76.30 to 79.08; on MS-COCO, STAC demonstrates 2x higher data efficiency by achieving 24.38 mAP using only 5% labeled data than supervised baseline that marks 23.86% using 10% labeled data. The code is available at \url{https://github.com/google-research/ssl_detection/}.
Improved Consistency Regularization for GANs
Feb 11, 2020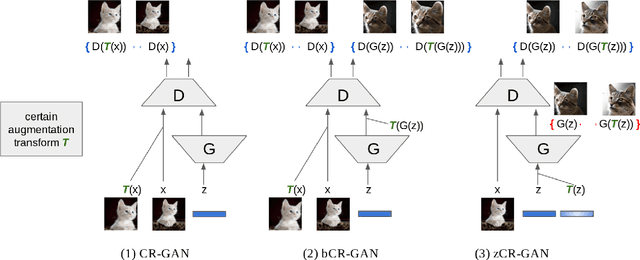
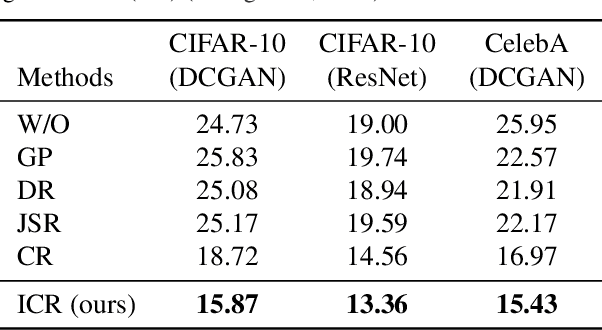


Recent work has increased the performance of Generative Adversarial Networks (GANs) by enforcing a consistency cost on the discriminator. We improve on this technique in several ways. We first show that consistency regularization can introduce artifacts into the GAN samples and explain how to fix this issue. We then propose several modifications to the consistency regularization procedure designed to improve its performance. We carry out extensive experiments quantifying the benefit of our improvements. For unconditional image synthesis on CIFAR-10 and CelebA, our modifications yield the best known FID scores on various GAN architectures. For conditional image synthesis on CIFAR-10, we improve the state-of-the-art FID score from 11.48 to 9.21. Finally, on ImageNet-2012, we apply our technique to the original BigGAN model and improve the FID from 6.66 to 5.38, which is the best score at that model size.
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
Jan 21, 2020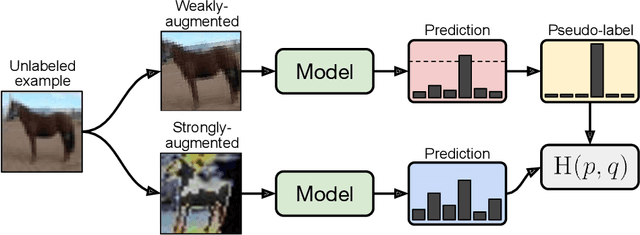
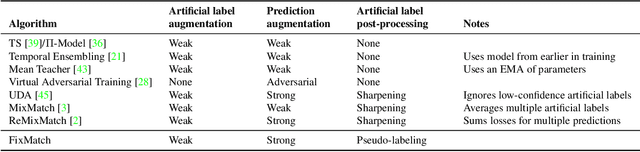
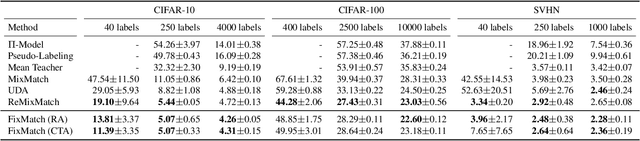

Semi-supervised learning (SSL) provides an effective means of leveraging unlabeled data to improve a model's performance. In this paper, we demonstrate the power of a simple combination of two common SSL methods: consistency regularization and pseudo-labeling. Our algorithm, FixMatch, first generates pseudo-labels using the model's predictions on weakly-augmented unlabeled images. For a given image, the pseudo-label is only retained if the model produces a high-confidence prediction. The model is then trained to predict the pseudo-label when fed a strongly-augmented version of the same image. Despite its simplicity, we show that FixMatch achieves state-of-the-art performance across a variety of standard semi-supervised learning benchmarks, including 94.93% accuracy on CIFAR-10 with 250 labels and 88.61% accuracy with 40 -- just 4 labels per class. Since FixMatch bears many similarities to existing SSL methods that achieve worse performance, we carry out an extensive ablation study to tease apart the experimental factors that are most important to FixMatch's success. We make our code available at https://github.com/google-research/fixmatch.
Distance-Based Learning from Errors for Confidence Calibration
Dec 03, 2019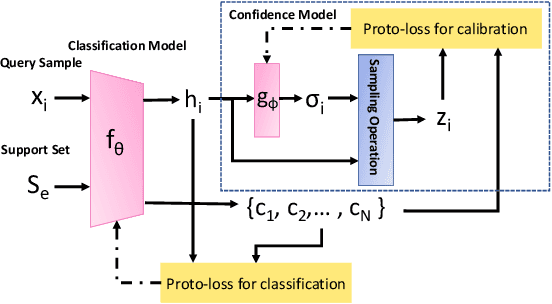
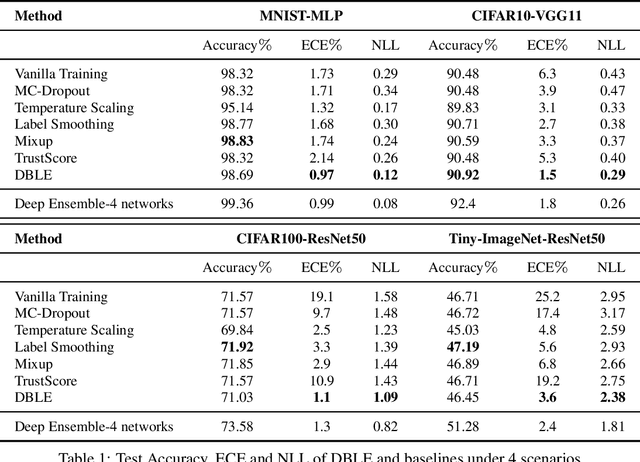
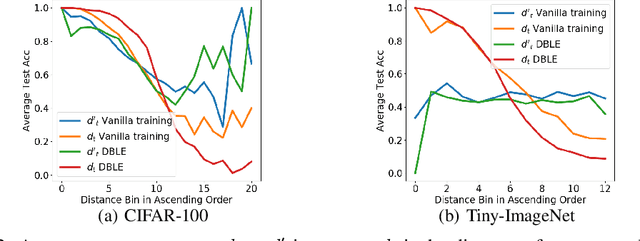

Deep neural networks (DNNs) are poorly-calibrated when trained in conventional ways. To improve confidence calibration of DNNs, we propose a novel training method, distance-based learning from errors (DBLE). DBLE bases its confidence estimation on distances in the representation space. We first adapt prototypical learning for training of a classification model for DBLE. It yields a representation space where the distance from a test sample to its ground-truth class center can calibrate the model performance. At inference, however, these distances are not available due to the lack of ground-truth labels. To circumvent this by approximately inferring the distance for every test sample, we propose to train a confidence model jointly with the classification model by merely learning from mis-classified training samples, which we show to be highly beneficial for effective learning. On multiple datasets and DNN architectures, we demonstrate that DBLE outperforms alternative single-modal confidence calibration approaches. DBLE also achieves comparable performance with computationally-expensive ensemble approaches with lower computational cost and lower number of parameters.
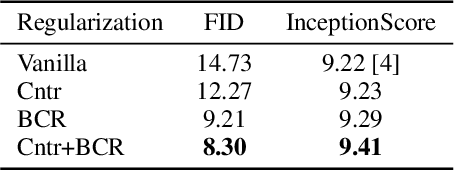
Consistency Regularization for Generative Adversarial Networks
Oct 26, 2019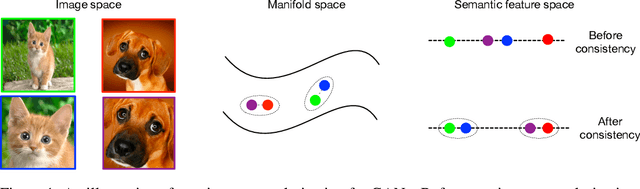

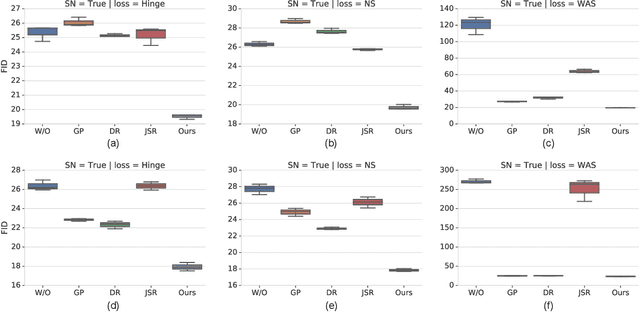

Generative Adversarial Networks (GANs) are known to be difficult to train, despite considerable research effort. Several regularization techniques for stabilizing training have been proposed, but they introduce non-trivial computational overheads and interact poorly with existing techniques like spectral normalization. In this work, we propose a simple, effective training stabilizer based on the notion of consistency regularization---a popular technique in the semi-supervised learning literature. In particular, we augment data passing into the GAN discriminator and penalize the sensitivity of the discriminator to these augmentations. We conduct a series of experiments to demonstrate that consistency regularization works effectively with spectral normalization and various GAN architectures, loss functions and optimizer settings. Our method achieves the best FID scores for unconditional image generation compared to other regularization methods on CIFAR-10 and CelebA. Moreover, Our consistency regularized GAN (CR-GAN) improves state-of-the-art FID scores for conditional generation from 14.73 to 11.67 on CIFAR-10 and from 8.73 to 6.66 on ImageNet-2012.
Consistency-Based Semi-Supervised Active Learning: Towards Minimizing Labeling Cost
Oct 16, 2019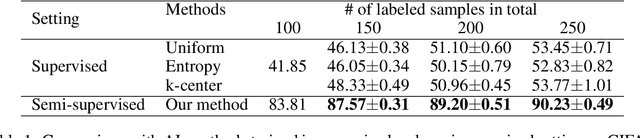
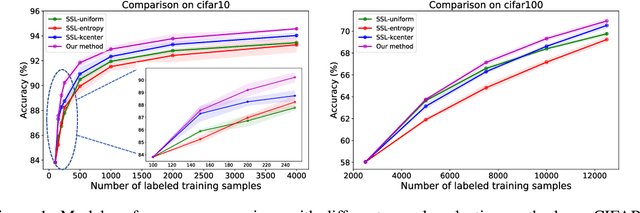
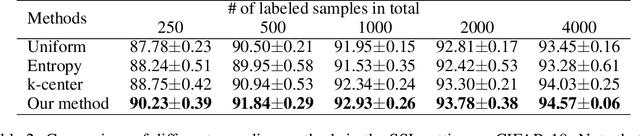
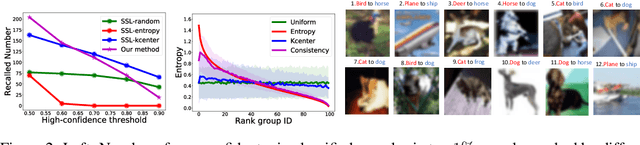
Active learning (AL) integrates data labeling and model training to minimize the labeling cost by prioritizing the selection of high value data that can best improve model performance. Readily-available unlabeled data are used for selection mechanisms, but are not used for model training in most conventional pool-based AL methods. To minimize the labeling cost, we unify unlabeled sample selection and model training based on two principles. First, we exploit both labeled and unlabeled data using semi-supervised learning (SSL) to distill information from unlabeled data that improves representation learning and sample selection. Second, we propose a simple yet effective selection metric that is coherent with the training objective such that the selected samples are effective at improving model performance. Experimental results demonstrate superior performance of our proposed principles for limited labeled data compared to alternative AL and SSL combinations. In addition, we study an important problem -- "When can we start AL?". We propose a measure that is empirically correlated with the AL target loss and can be used to assist in determining the proper start point.