 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Cycle Consistency Learning in Interactive Volume Segmentation
Mar 11, 2023Interactive volume segmentation can be approached via two decoupled modules: interaction-to-segmentation and segmentation propagation. Given a medical volume, a user first segments a slice (or several slices) via the interaction module and then propagates the segmentation(s) to the remaining slices. The user may repeat this process multiple times until a sufficiently high volume segmentation quality is achieved. However, due to the lack of human correction during propagation, segmentation errors are prone to accumulate in the intermediate slices and may lead to sub-optimal performance. To alleviate this issue, we propose a simple yet effective cycle consistency loss that regularizes an intermediate segmentation by referencing the accurate segmentation in the starting slice. To this end, we introduce a backward segmentation path that propagates the intermediate segmentation back to the starting slice using the same propagation network. With cycle consistency training, the propagation network is better regularized than in standard forward-only training approaches. Evaluation results on challenging benchmarks such as AbdomenCT-1k and OAI-ZIB demonstrate the effectiveness of our method. To the best of our knowledge, we are the first to explore cycle consistency learning in interactive volume segmentation.
Progressive Multi-view Human Mesh Recovery with Self-Supervision
Dec 10, 2022



To date, little attention has been given to multi-view 3D human mesh estimation, despite real-life applicability (e.g., motion capture, sport analysis) and robustness to single-view ambiguities. Existing solutions typically suffer from poor generalization performance to new settings, largely due to the limited diversity of image-mesh pairs in multi-view training data. To address this shortcoming, people have explored the use of synthetic images. But besides the usual impact of visual gap between rendered and target data, synthetic-data-driven multi-view estimators also suffer from overfitting to the camera viewpoint distribution sampled during training which usually differs from real-world distributions. Tackling both challenges, we propose a novel simulation-based training pipeline for multi-view human mesh recovery, which (a) relies on intermediate 2D representations which are more robust to synthetic-to-real domain gap; (b) leverages learnable calibration and triangulation to adapt to more diversified camera setups; and (c) progressively aggregates multi-view information in a canonical 3D space to remove ambiguities in 2D representations. Through extensive benchmarking, we demonstrate the superiority of the proposed solution especially for unseen in-the-wild scenarios.
Forecasting Human Trajectory from Scene History
Oct 17, 2022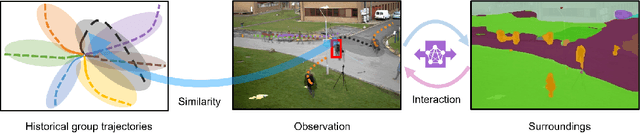
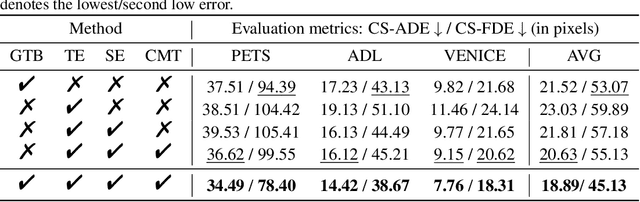
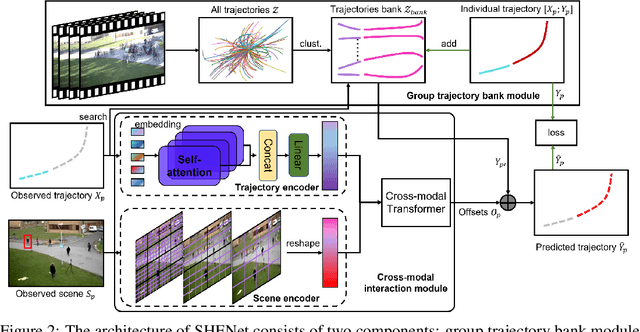
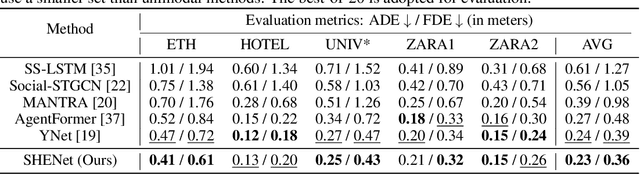
Predicting the future trajectory of a person remains a challenging problem, due to randomness and subjectivity of human movement. However, the moving patterns of human in a constrained scenario typically conform to a limited number of regularities to a certain extent, because of the scenario restrictions and person-person or person-object interactivity. Thus, an individual person in this scenario should follow one of the regularities as well. In other words, a person's subsequent trajectory has likely been traveled by others. Based on this hypothesis, we propose to forecast a person's future trajectory by learning from the implicit scene regularities. We call the regularities, inherently derived from the past dynamics of the people and the environment in the scene, scene history. We categorize scene history information into two types: historical group trajectory and individual-surroundings interaction. To exploit these two types of information for trajectory prediction, we propose a novel framework Scene History Excavating Network (SHENet), where the scene history is leveraged in a simple yet effective approach. In particular, we design two components: the group trajectory bank module to extract representative group trajectories as the candidate for future path, and the cross-modal interaction module to model the interaction between individual past trajectory and its surroundings for trajectory refinement. In addition, to mitigate the uncertainty in ground-truth trajectory, caused by the aforementioned randomness and subjectivity of human movement, we propose to include smoothness into the training process and evaluation metrics. We conduct extensive evaluations to validate the efficacy of our proposed framework on ETH, UCY, as well as a new, challenging benchmark dataset PAV, demonstrating superior performance compared to state-of-the-art methods.
Federated Learning with Privacy-Preserving Ensemble Attention Distillation
Oct 16, 2022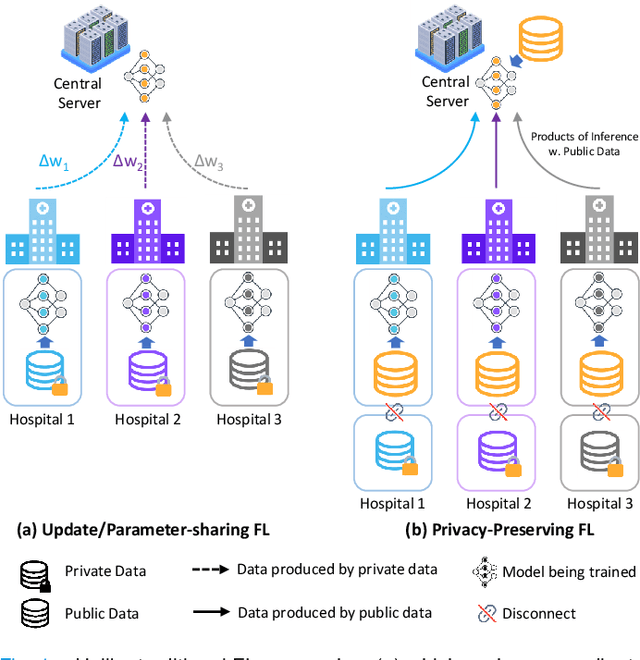
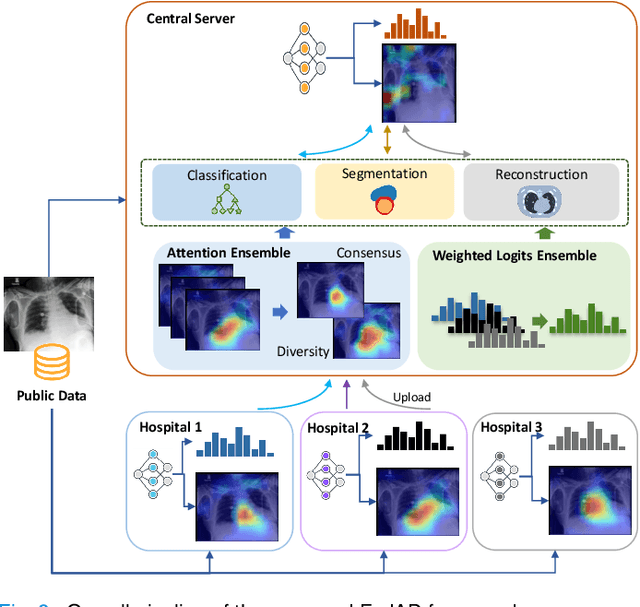
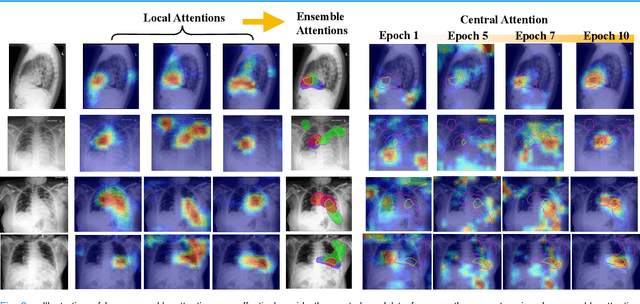
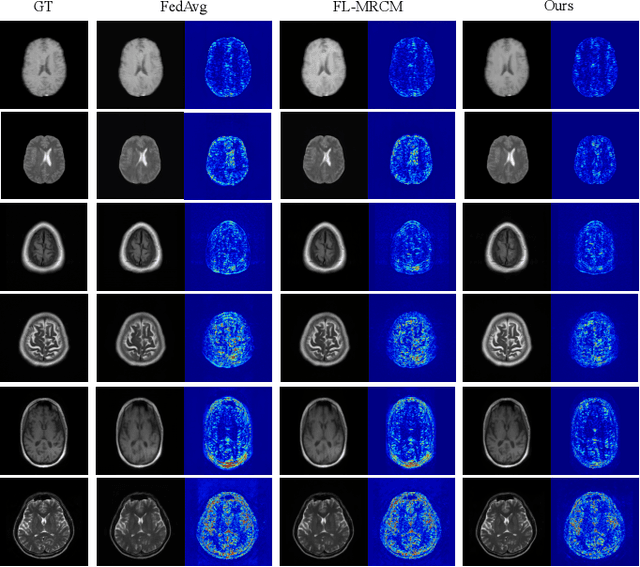
Federated Learning (FL) is a machine learning paradigm where many local nodes collaboratively train a central model while keeping the training data decentralized. This is particularly relevant for clinical applications since patient data are usually not allowed to be transferred out of medical facilities, leading to the need for FL. Existing FL methods typically share model parameters or employ co-distillation to address the issue of unbalanced data distribution. However, they also require numerous rounds of synchronized communication and, more importantly, suffer from a privacy leakage risk. We propose a privacy-preserving FL framework leveraging unlabeled public data for one-way offline knowledge distillation in this work. The central model is learned from local knowledge via ensemble attention distillation. Our technique uses decentralized and heterogeneous local data like existing FL approaches, but more importantly, it significantly reduces the risk of privacy leakage. We demonstrate that our method achieves very competitive performance with more robust privacy preservation based on extensive experiments on image classification, segmentation, and reconstruction tasks.
PREF: Predictability Regularized Neural Motion Fields
Sep 21, 2022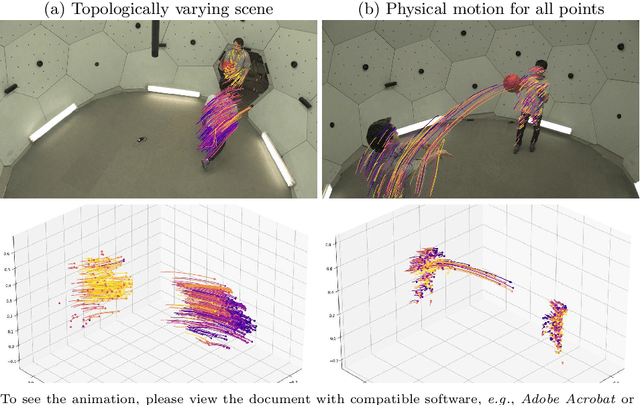
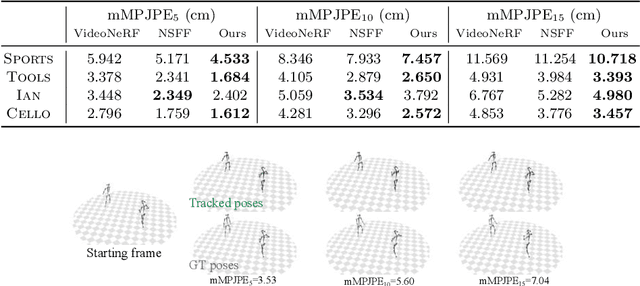
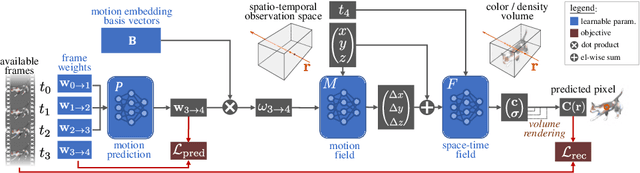
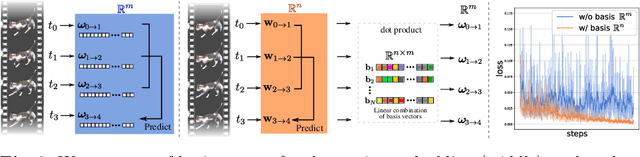
Knowing the 3D motions in a dynamic scene is essential to many vision applications. Recent progress is mainly focused on estimating the activity of some specific elements like humans. In this paper, we leverage a neural motion field for estimating the motion of all points in a multiview setting. Modeling the motion from a dynamic scene with multiview data is challenging due to the ambiguities in points of similar color and points with time-varying color. We propose to regularize the estimated motion to be predictable. If the motion from previous frames is known, then the motion in the near future should be predictable. Therefore, we introduce a predictability regularization by first conditioning the estimated motion on latent embeddings, then by adopting a predictor network to enforce predictability on the embeddings. The proposed framework PREF (Predictability REgularized Fields) achieves on par or better results than state-of-the-art neural motion field-based dynamic scene representation methods, while requiring no prior knowledge of the scene.
Preserving Privacy in Federated Learning with Ensemble Cross-Domain Knowledge Distillation
Sep 10, 2022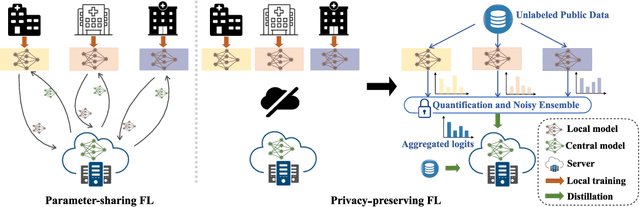
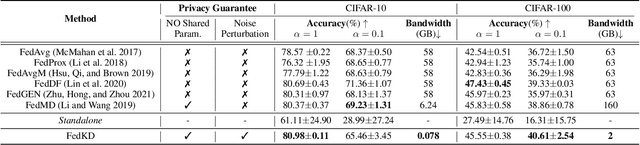
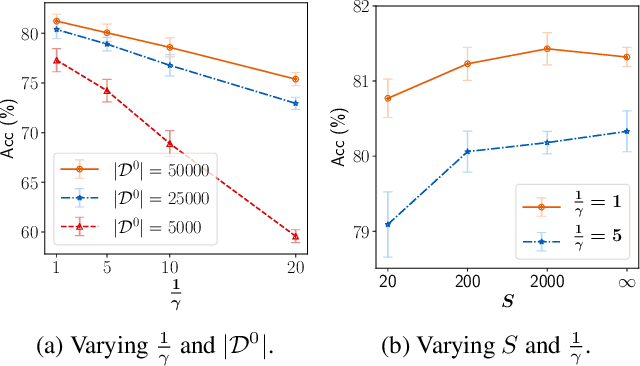
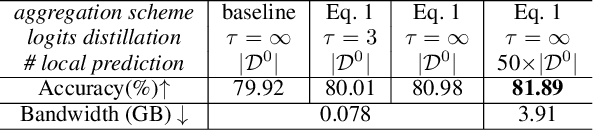
Federated Learning (FL) is a machine learning paradigm where local nodes collaboratively train a central model while the training data remains decentralized. Existing FL methods typically share model parameters or employ co-distillation to address the issue of unbalanced data distribution. However, they suffer from communication bottlenecks. More importantly, they risk privacy leakage. In this work, we develop a privacy preserving and communication efficient method in a FL framework with one-shot offline knowledge distillation using unlabeled, cross-domain public data. We propose a quantized and noisy ensemble of local predictions from completely trained local models for stronger privacy guarantees without sacrificing accuracy. Based on extensive experiments on image classification and text classification tasks, we show that our privacy-preserving method outperforms baseline FL algorithms with superior performance in both accuracy and communication efficiency.
Self-supervised Human Mesh Recovery with Cross-Representation Alignment
Sep 10, 2022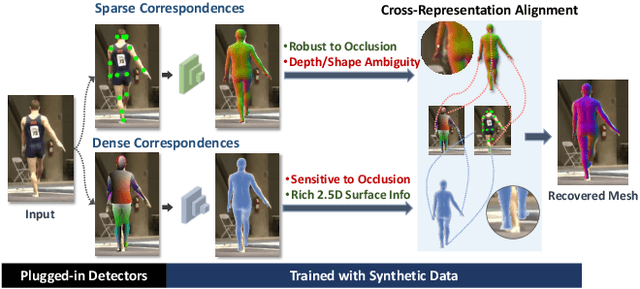
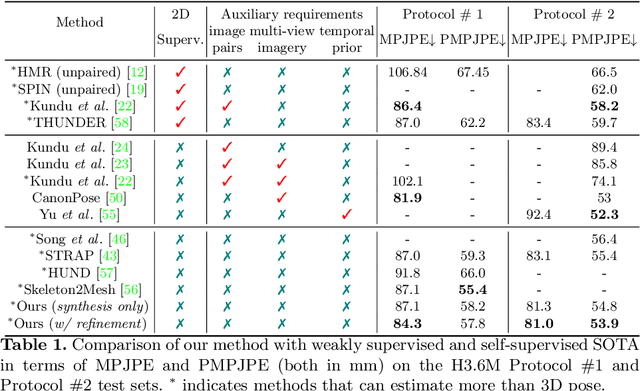
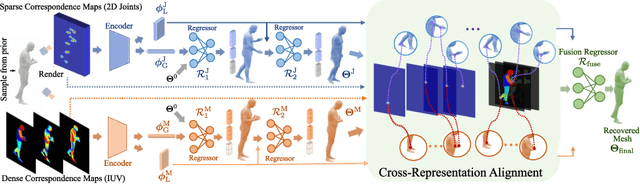
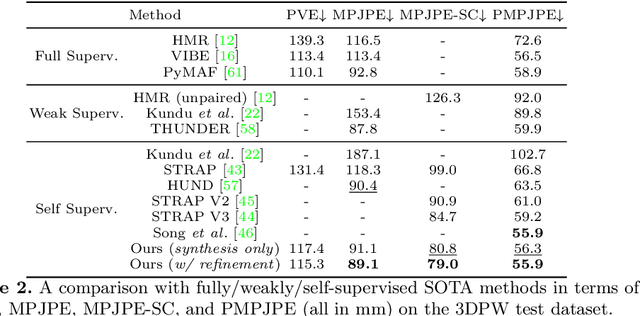
Fully supervised human mesh recovery methods are data-hungry and have poor generalizability due to the limited availability and diversity of 3D-annotated benchmark datasets. Recent progress in self-supervised human mesh recovery has been made using synthetic-data-driven training paradigms where the model is trained from synthetic paired 2D representation (e.g., 2D keypoints and segmentation masks) and 3D mesh. However, on synthetic dense correspondence maps (i.e., IUV) few have been explored since the domain gap between synthetic training data and real testing data is hard to address for 2D dense representation. To alleviate this domain gap on IUV, we propose cross-representation alignment utilizing the complementary information from the robust but sparse representation (2D keypoints). Specifically, the alignment errors between initial mesh estimation and both 2D representations are forwarded into regressor and dynamically corrected in the following mesh regression. This adaptive cross-representation alignment explicitly learns from the deviations and captures complementary information: robustness from sparse representation and richness from dense representation. We conduct extensive experiments on multiple standard benchmark datasets and demonstrate competitive results, helping take a step towards reducing the annotation effort needed to produce state-of-the-art models in human mesh estimation.
PseudoClick: Interactive Image Segmentation with Click Imitation
Jul 12, 2022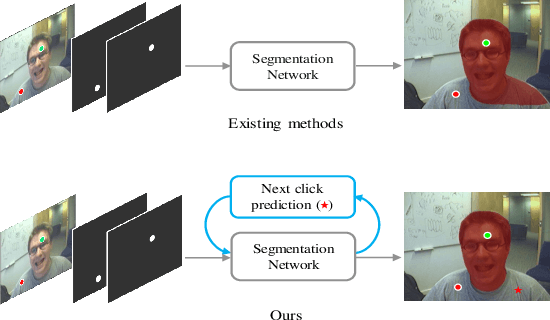
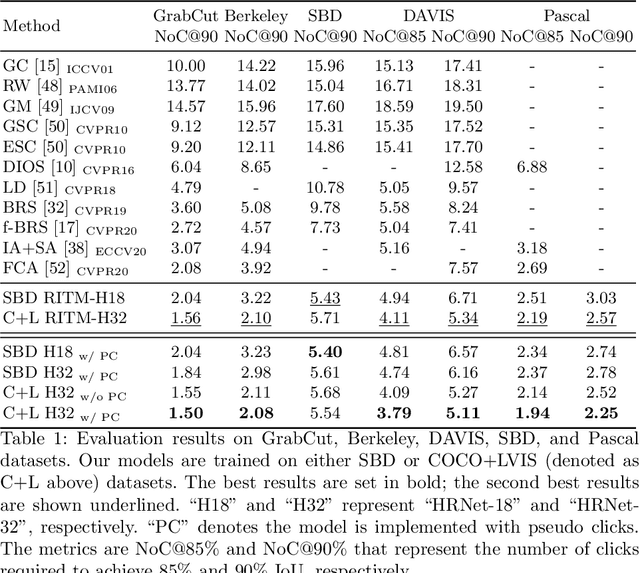
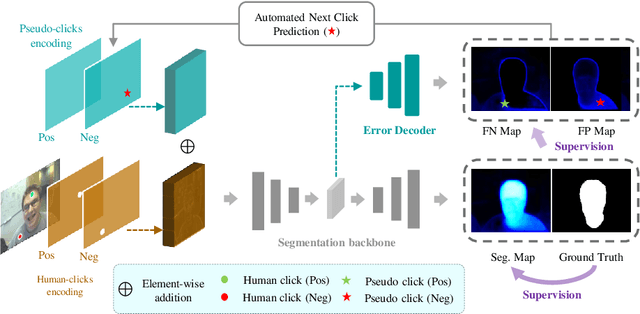

The goal of click-based interactive image segmentation is to obtain precise object segmentation masks with limited user interaction, i.e., by a minimal number of user clicks. Existing methods require users to provide all the clicks: by first inspecting the segmentation mask and then providing points on mislabeled regions, iteratively. We ask the question: can our model directly predict where to click, so as to further reduce the user interaction cost? To this end, we propose {\PseudoClick}, a generic framework that enables existing segmentation networks to propose candidate next clicks. These automatically generated clicks, termed pseudo clicks in this work, serve as an imitation of human clicks to refine the segmentation mask.
Learning Hierarchical Attention for Weakly-supervised Chest X-Ray Abnormality Localization and Diagnosis
Dec 23, 2021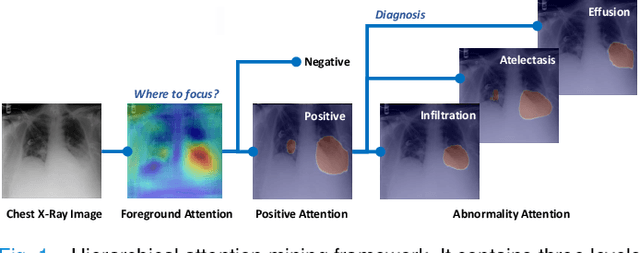
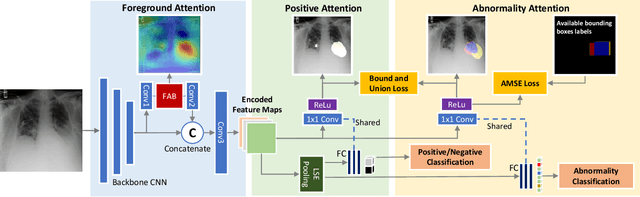
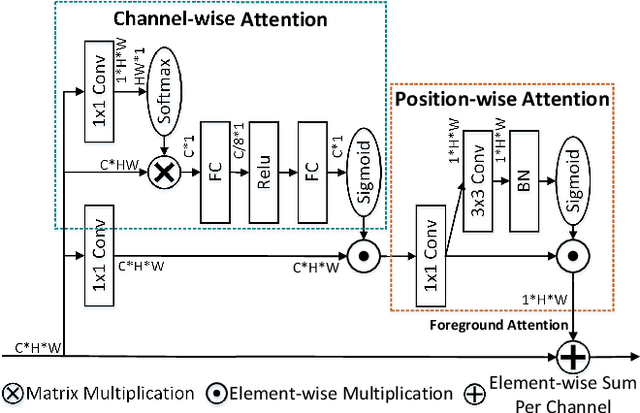
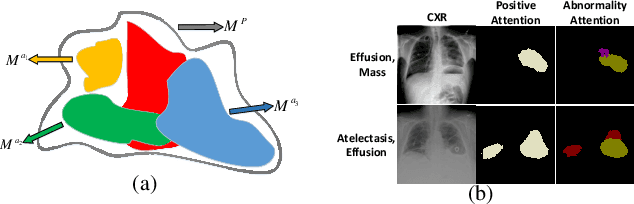
We consider the problem of abnormality localization for clinical applications. While deep learning has driven much recent progress in medical imaging, many clinical challenges are not fully addressed, limiting its broader usage. While recent methods report high diagnostic accuracies, physicians have concerns trusting these algorithm results for diagnostic decision-making purposes because of a general lack of algorithm decision reasoning and interpretability. One potential way to address this problem is to further train these models to localize abnormalities in addition to just classifying them. However, doing this accurately will require a large amount of disease localization annotations by clinical experts, a task that is prohibitively expensive to accomplish for most applications. In this work, we take a step towards addressing these issues by means of a new attention-driven weakly supervised algorithm comprising a hierarchical attention mining framework that unifies activation- and gradient-based visual attention in a holistic manner. Our key algorithmic innovations include the design of explicit ordinal attention constraints, enabling principled model training in a weakly-supervised fashion, while also facilitating the generation of visual-attention-driven model explanations by means of localization cues. On two large-scale chest X-ray datasets (NIH ChestX-ray14 and CheXpert), we demonstrate significant localization performance improvements over the current state of the art while also achieving competitive classification performance. Our code is available on https://github.com/oyxhust/HAM.
Spatio-Temporal Representation Factorization for Video-based Person Re-Identification
Aug 15, 2021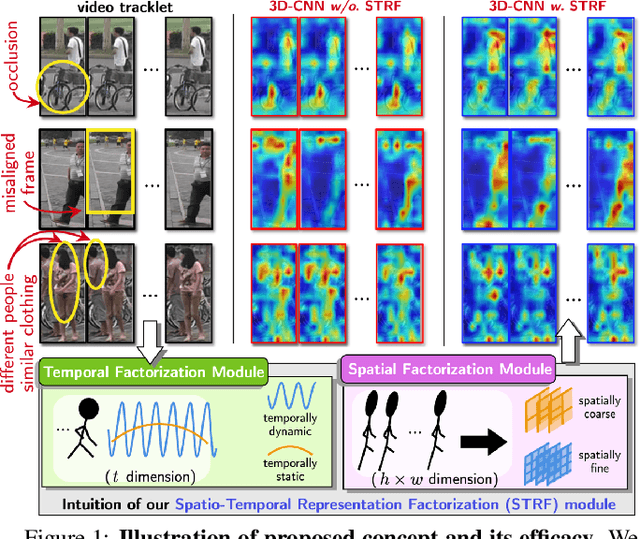
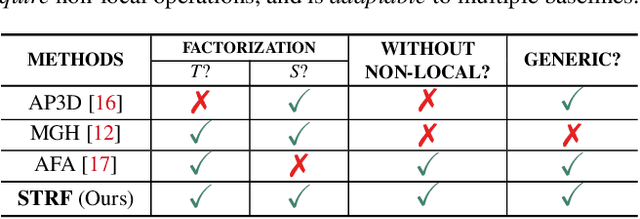

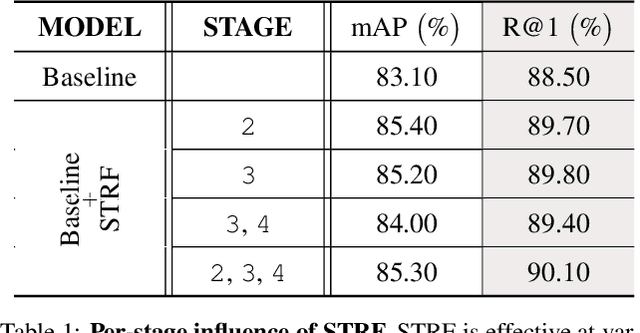
Despite much recent progress in video-based person re-identification (re-ID), the current state-of-the-art still suffers from common real-world challenges such as appearance similarity among various people, occlusions, and frame misalignment. To alleviate these problems, we propose Spatio-Temporal Representation Factorization (STRF), a flexible new computational unit that can be used in conjunction with most existing 3D convolutional neural network architectures for re-ID. The key innovations of STRF over prior work include explicit pathways for learning discriminative temporal and spatial features, with each component further factorized to capture complementary person-specific appearance and motion information. Specifically, temporal factorization comprises two branches, one each for static features (e.g., the color of clothes) that do not change much over time, and dynamic features (e.g., walking patterns) that change over time. Further, spatial factorization also comprises two branches to learn both global (coarse segments) as well as local (finer segments) appearance features, with the local features particularly useful in cases of occlusion or spatial misalignment. These two factorization operations taken together result in a modular architecture for our parameter-wise light STRF unit that can be plugged in between any two 3D convolutional layers, resulting in an end-to-end learning framework. We empirically show that STRF improves performance of various existing baseline architectures while demonstrating new state-of-the-art results using standard person re-ID evaluation protocols on three benchmarks.