 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unified Multi-granularity Text Detection with Interactive Attention
May 30, 2024



Existing OCR engines or document image analysis systems typically rely on training separate models for text detection in varying scenarios and granularities, leading to significant computational complexity and resource demands. In this paper, we introduce "Detect Any Text" (DAT), an advanced paradigm that seamlessly unifies scene text detection, layout analysis, and document page detection into a cohesive, end-to-end model. This design enables DAT to efficiently manage text instances at different granularities, including *word*, *line*, *paragraph* and *page*. A pivotal innovation in DAT is the across-granularity interactive attention module, which significantly enhances the representation learning of text instances at varying granularities by correlating structural information across different text queries. As a result, it enables the model to achieve mutually beneficial detection performances across multiple text granularities. Additionally, a prompt-based segmentation module refines detection outcomes for texts of arbitrary curvature and complex layouts, thereby improving DAT's accuracy and expanding its real-world applicability. Experimental results demonstrate that DAT achieves state-of-the-art performances across a variety of text-related benchmarks, including multi-oriented/arbitrarily-shaped scene text detection, document layout analysis and page detection tasks.
ICDAR 2019 Competition on Large-scale Street View Text with Partial Labeling -- RRC-LSVT
Sep 17, 2019


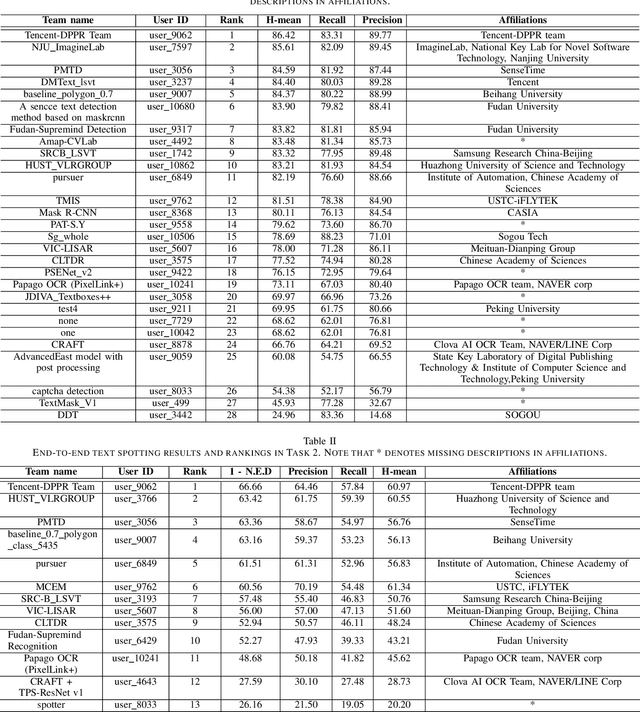
Robust text reading from street view images provides valuable information for various applications. Performance improvement of existing methods in such a challenging scenario heavily relies on the amount of fully annotated training data, which is costly and in-efficient to obtain. To scale up the amount of training data while keeping the labeling procedure cost-effective, this competition introduces a new challenge on Large-scale Street View Text with Partial Labeling (LSVT), providing 50, 000 and 400, 000 images in full and weak annotations, respectively. This competition aims to explore the abilities of state-of-the-art methods to detect and recognize text instances from large-scale street view images, closing the gap between research benchmarks and real applications. During the competition period, a total of 41 teams participated in the two proposed tasks with 132 valid submissions, i.e., text detection and end-to-end text spotting. This paper includes dataset descriptions, task definitions, evaluation protocols and results summaries of the ICDAR 2019-LSVT challenge.
ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT)
Sep 16, 2019



This paper reports the ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT) that consists of three major challenges: i) scene text detection, ii) scene text recognition, and iii) scene text spotting. A total of 78 submissions from 46 unique teams/individuals were received for this competition. The top performing score of each challenge is as follows: i) T1 - 82.65%, ii) T2.1 - 74.3%, iii) T2.2 - 85.32%, iv) T3.1 - 53.86%, and v) T3.2 - 54.91%. Apart from the results, this paper also details the ArT dataset, tasks description, evaluation metrics and participants methods. The dataset, the evaluation kit as well as the results are publicly available at https://rrc.cvc.uab.es/?ch=14