 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSF-4D: A Progressive Sampling Framework for View Consistent 4D Editing
Mar 14, 2025Instruction-guided generative models, especially those using text-to-image (T2I) and text-to-video (T2V) diffusion frameworks, have advanced the field of content editing in recent years. To extend these capabilities to 4D scene, we introduce a progressive sampling framework for 4D editing (PSF-4D) that ensures temporal and multi-view consistency by intuitively controlling the noise initialization during forward diffusion. For temporal coherence, we design a correlated Gaussian noise structure that links frames over time, allowing each frame to depend meaningfully on prior frames. Additionally, to ensure spatial consistency across views, we implement a cross-view noise model, which uses shared and independent noise components to balance commonalities and distinct details among different views. To further enhance spatial coherence, PSF-4D incorporates view-consistent iterative refinement, embedding view-aware information into the denoising process to ensure aligned edits across frames and views. Our approach enables high-quality 4D editing without relying on external models, addressing key challenges in previous methods. Through extensive evaluation on multiple benchmarks and multiple editing aspects (e.g., style transfer, multi-attribute editing, object removal, local editing, etc.), we show the effectiveness of our proposed method. Experimental results demonstrate that our proposed method outperforms state-of-the-art 4D editing methods in diverse benchmarks.
NASM: Neural Anisotropic Surface Meshing
Oct 30, 2024This paper introduces a new learning-based method, NASM, for anisotropic surface meshing. Our key idea is to propose a graph neural network to embed an input mesh into a high-dimensional (high-d) Euclidean embedding space to preserve curvature-based anisotropic metric by using a dot product loss between high-d edge vectors. This can dramatically reduce the computational time and increase the scalability. Then, we propose a novel feature-sensitive remeshing on the generated high-d embedding to automatically capture sharp geometric features. We define a high-d normal metric, and then derive an automatic differentiation on a high-d centroidal Voronoi tessellation (CVT) optimization with the normal metric to simultaneously preserve geometric features and curvature anisotropy that exhibit in the original 3D shapes. To our knowledge, this is the first time that a deep learning framework and a large dataset are proposed to construct a high-d Euclidean embedding space for 3D anisotropic surface meshing. Experimental results are evaluated and compared with the state-of-the-art in anisotropic surface meshing on a large number of surface models from Thingi10K dataset as well as tested on extensive unseen 3D shapes from Multi-Garment Network dataset and FAUST human dataset.
CWF: Consolidating Weak Features in High-quality Mesh Simplification
Apr 24, 2024



In mesh simplification, common requirements like accuracy, triangle quality, and feature alignment are often considered as a trade-off. Existing algorithms concentrate on just one or a few specific aspects of these requirements. For example, the well-known Quadric Error Metrics (QEM) approach prioritizes accuracy and can preserve strong feature lines/points as well but falls short in ensuring high triangle quality and may degrade weak features that are not as distinctive as strong ones. In this paper, we propose a smooth functional that simultaneously considers all of these requirements. The functional comprises a normal anisotropy term and a Centroidal Voronoi Tessellation (CVT) energy term, with the variables being a set of movable points lying on the surface. The former inherits the spirit of QEM but operates in a continuous setting, while the latter encourages even point distribution, allowing various surface metrics. We further introduce a decaying weight to automatically balance the two terms. We selected 100 CAD models from the ABC dataset, along with 21 organic models, to compare the existing mesh simplification algorithms with ours. Experimental results reveal an important observation: the introduction of a decaying weight effectively reduces the conflict between the two terms and enables the alignment of weak features. This distinctive feature sets our approach apart from most existing mesh simplification methods and demonstrates significant potential in shape understanding.
VC-Net: Deep Volume-Composition Networks for Segmentation and Visualization of Highly Sparse and Noisy Image Data
Sep 14, 2020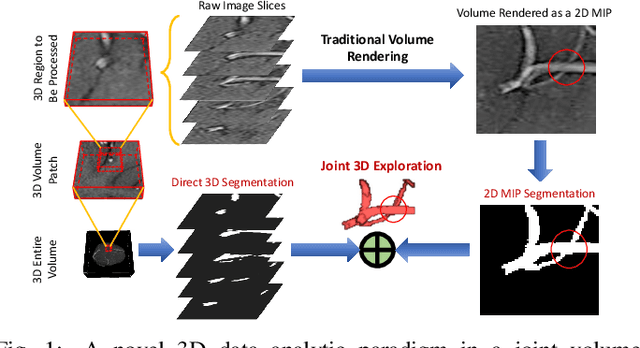
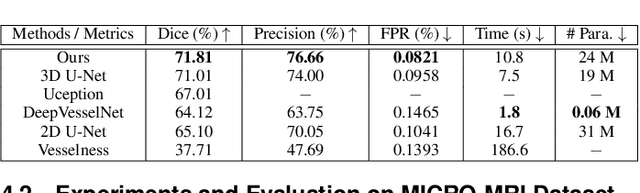


The motivation of our work is to present a new visualization-guided computing paradigm to combine direct 3D volume processing and volume rendered clues for effective 3D exploration such as extracting and visualizing microstructures in-vivo. However, it is still challenging to extract and visualize high fidelity 3D vessel structure due to its high sparseness, noisiness, and complex topology variations. In this paper, we present an end-to-end deep learning method, VC-Net, for robust extraction of 3D microvasculature through embedding the image composition, generated by maximum intensity projection (MIP), into 3D volume image learning to enhance the performance. The core novelty is to automatically leverage the volume visualization technique (MIP) to enhance the 3D data exploration at deep learning level. The MIP embedding features can enhance the local vessel signal and are adaptive to the geometric variability and scalability of vessels, which is crucial in microvascular tracking. A multi-stream convolutional neural network is proposed to learn the 3D volume and 2D MIP features respectively and then explore their inter-dependencies in a joint volume-composition embedding space by unprojecting the MIP features into 3D volume embedding space. The proposed framework can better capture small / micro vessels and improve vessel connectivity. To our knowledge, this is the first deep learning framework to construct a joint convolutional embedding space, where the computed vessel probabilities from volume rendering based 2D projection and 3D volume can be explored and integrated synergistically. Experimental results are compared with the traditional 3D vessel segmentation methods and the deep learning state-of-the-art on public and real patient (micro-)cerebrovascular image datasets. Our method demonstrates the potential in a powerful MR arteriogram and venogram diagnosis of vascular diseases.
Attention-based Deep Reinforcement Learning for Multi-view Environments
May 10, 2019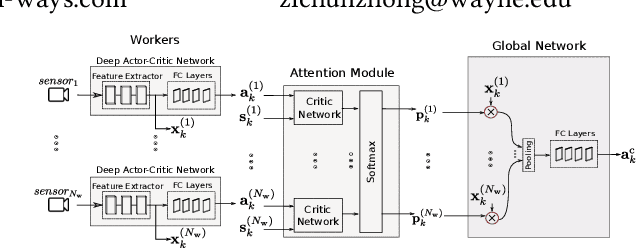
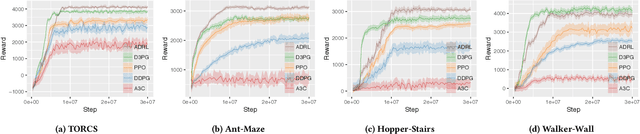
In reinforcement learning algorithms, it is a common practice to account for only a single view of the environment to make the desired decisions; however, utilizing multiple views of the environment can help to promote the learning of complicated policies. Since the views may frequently suffer from partial observability, their provided observation can have different levels of importance. In this paper, we present a novel attention-based deep reinforcement learning method in a multi-view environment in which each view can provide various representative information about the environment. Specifically, our method learns a policy to dynamically attend to views of the environment based on their importance in the decision-making process. We evaluate the performance of our method on TORCS racing car simulator and three other complex 3D environments with obstacles.
A-CNN: Annularly Convolutional Neural Networks on Point Clouds
Apr 16, 2019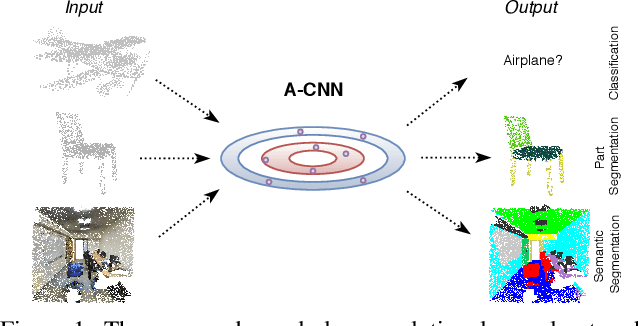
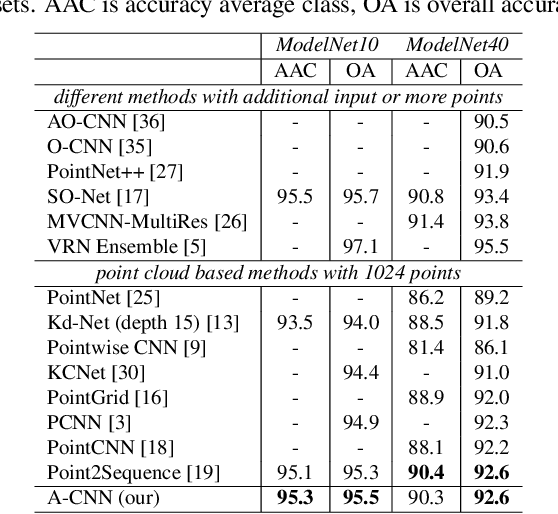
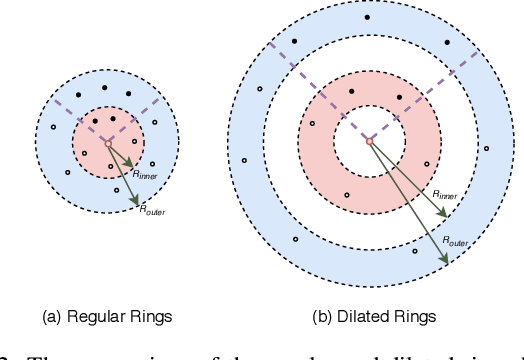
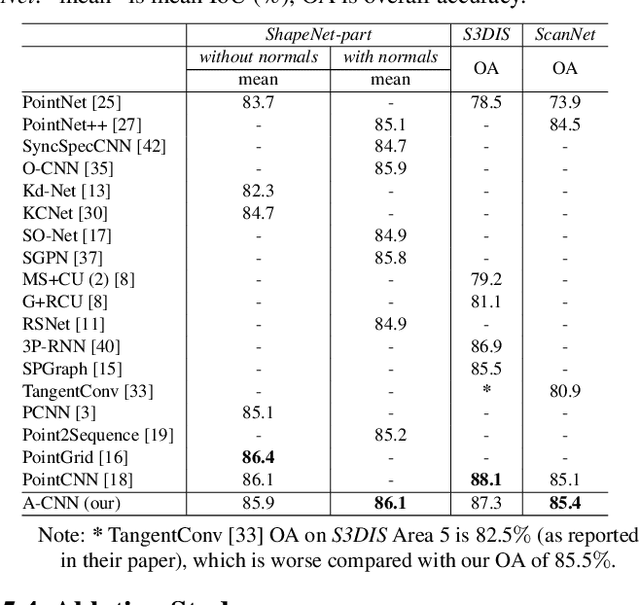
Analyzing the geometric and semantic properties of 3D point clouds through the deep networks is still challenging due to the irregularity and sparsity of samplings of their geometric structures. This paper presents a new method to define and compute convolution directly on 3D point clouds by the proposed annular convolution. This new convolution operator can better capture the local neighborhood geometry of each point by specifying the (regular and dilated) ring-shaped structures and directions in the computation. It can adapt to the geometric variability and scalability at the signal processing level. We apply it to the developed hierarchical neural networks for object classification, part segmentation, and semantic segmentation in large-scale scenes. The extensive experiments and comparisons demonstrate that our approach outperforms the state-of-the-art methods on a variety of standard benchmark datasets (e.g., ModelNet10, ModelNet40, ShapeNet-part, S3DIS, and ScanNet).