 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMove2Hear: Active Audio-Visual Source Separation
May 15, 2021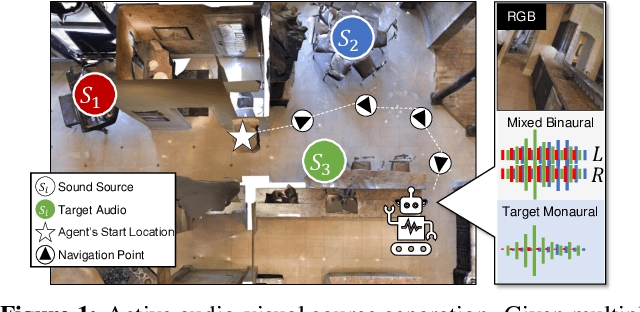
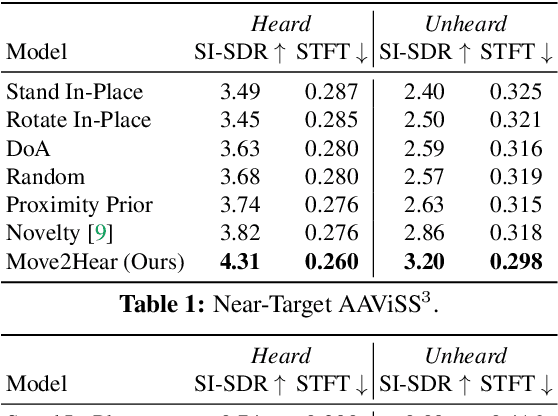
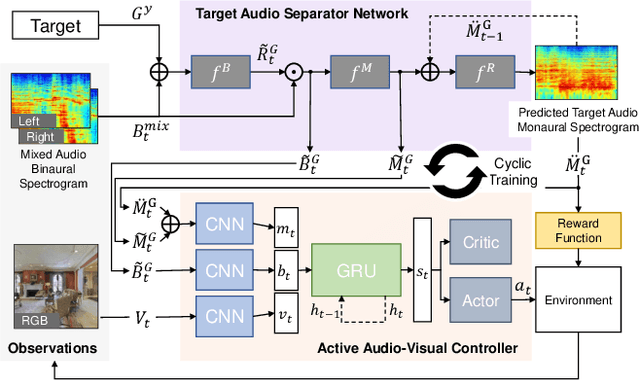
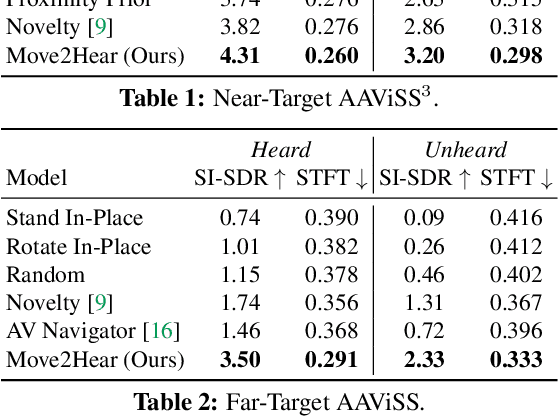
We introduce the active audio-visual source separation problem, where an agent must move intelligently in order to better isolate the sounds coming from an object of interest in its environment. The agent hears multiple audio sources simultaneously (e.g., a person speaking down the hall in a noisy household) and must use its eyes and ears to automatically separate out the sounds originating from the target object within a limited time budget. Towards this goal, we introduce a reinforcement learning approach that trains movement policies controlling the agent's camera and microphone placement over time, guided by the improvement in predicted audio separation quality. We demonstrate our approach in scenarios motivated by both augmented reality (system is already co-located with the target object) and mobile robotics (agent begins arbitrarily far from the target object). Using state-of-the-art realistic audio-visual simulations in 3D environments, we demonstrate our model's ability to find minimal movement sequences with maximal payoff for audio source separation. Project: http://vision.cs.utexas.edu/projects/move2hear.
Environment Predictive Coding for Embodied Agents
Feb 03, 2021
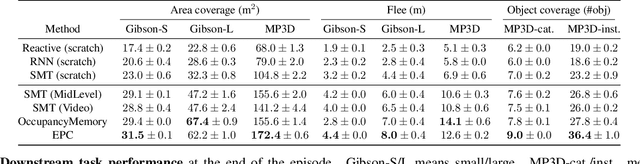
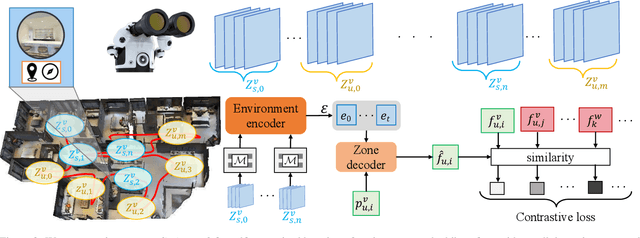

We introduce environment predictive coding, a self-supervised approach to learn environment-level representations for embodied agents. In contrast to prior work on self-supervised learning for images, we aim to jointly encode a series of images gathered by an agent as it moves about in 3D environments. We learn these representations via a zone prediction task, where we intelligently mask out portions of an agent's trajectory and predict them from the unmasked portions, conditioned on the agent's camera poses. By learning such representations on a collection of videos, we demonstrate successful transfer to multiple downstream navigation-oriented tasks. Our experiments on the photorealistic 3D environments of Gibson and Matterport3D show that our method outperforms the state-of-the-art on challenging tasks with only a limited budget of experience.
Semantic Audio-Visual Navigation
Dec 21, 2020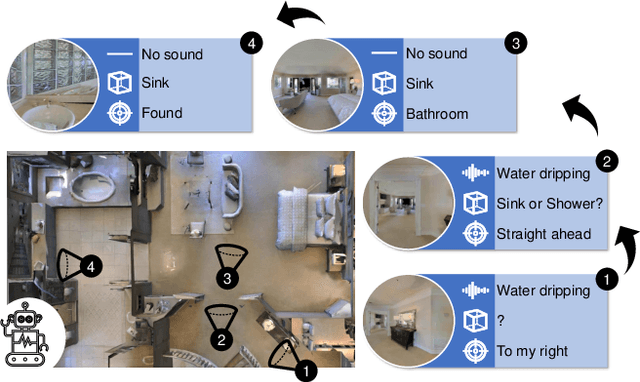
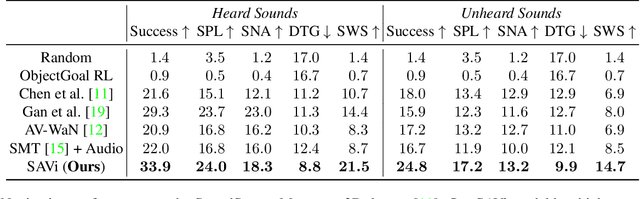
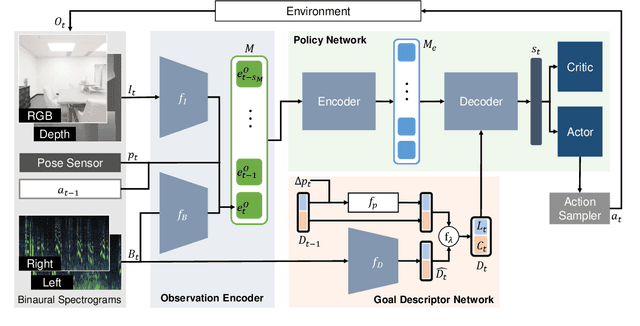
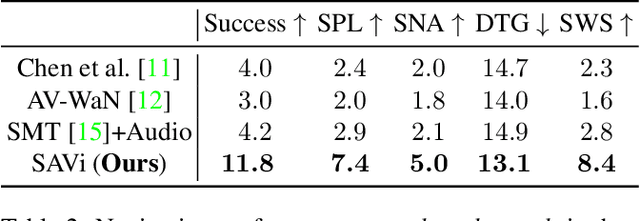
Recent work on audio-visual navigation assumes a constantly-sounding target and restricts the role of audio to signaling the target's spatial placement. We introduce semantic audio-visual navigation, where objects in the environment make sounds consistent with their semantic meanings (e.g., toilet flushing, door creaking) and acoustic envents are sporadic or short in duration. We propose a transformer-based model to tackle this new semantic AudioGoal task, incorporating an inferred goal descriptor that captures both spatial and semantic properties of the target. Our model's persistent multimodal memory enables it to reach the goal even long after the acoustic event stops. In support of the new task, we also expand the SoundSpaces audio simulation platform to provide semantically grounded object sounds for an array of objects in Matterport3D. Our method strongly outperforms existing audio-visual navigation methods by learning to associate semantic, acoustic, and visual cues.
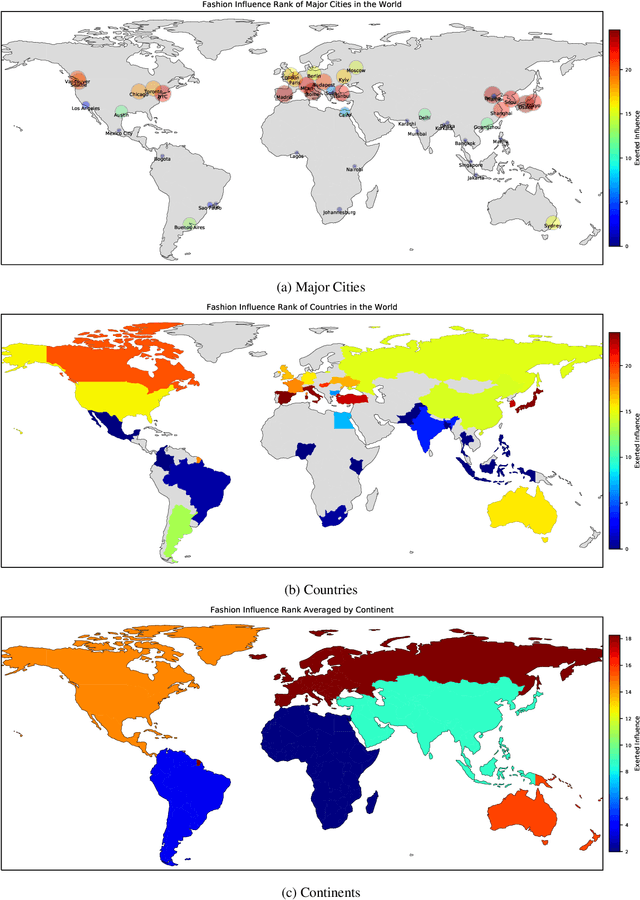
Modeling Fashion Influence from Photos
Nov 17, 2020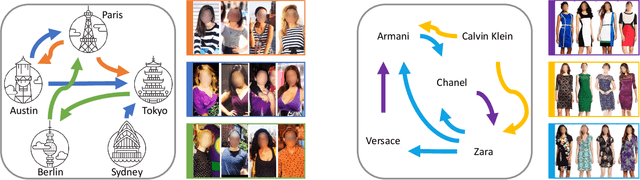
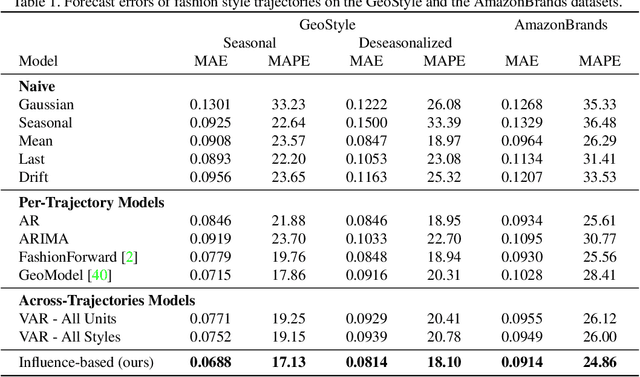

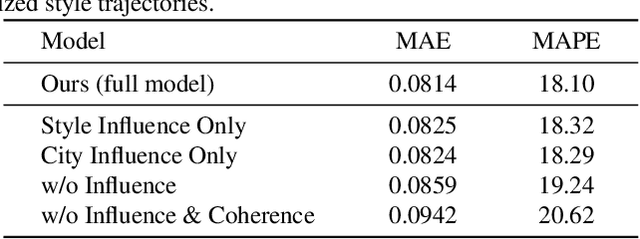
The evolution of clothing styles and their migration across the world is intriguing, yet difficult to describe quantitatively. We propose to discover and quantify fashion influences from catalog and social media photos. We explore fashion influence along two channels: geolocation and fashion brands. We introduce an approach that detects which of these entities influence which other entities in terms of propagating their styles. We then leverage the discovered influence patterns to inform a novel forecasting model that predicts the future popularity of any given style within any given city or brand. To demonstrate our idea, we leverage public large-scale datasets of 7.7M Instagram photos from 44 major world cities (where styles are worn with variable frequency) as well as 41K Amazon product photos (where styles are purchased with variable frequency). Our model learns directly from the image data how styles move between locations and how certain brands affect each other's designs in a predictable way. The discovered influence relationships reveal how both cities and brands exert and receive fashion influence for an array of visual styles inferred from the images. Furthermore, the proposed forecasting model achieves state-of-the-art results for challenging style forecasting tasks. Our results indicate the advantage of grounding visual style evolution both spatially and temporally, and for the first time, they quantify the propagation of inter-brand and inter-city influences.
Occupancy Anticipation for Efficient Exploration and Navigation
Aug 25, 2020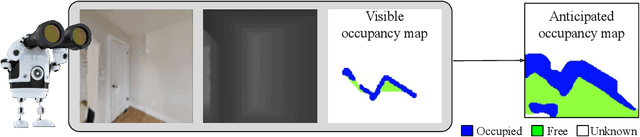
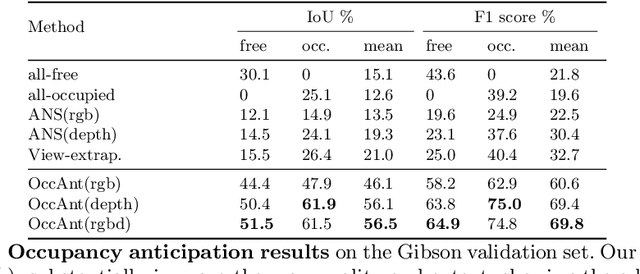
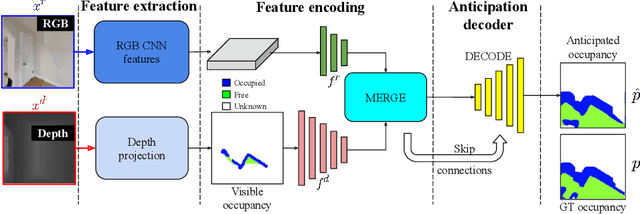
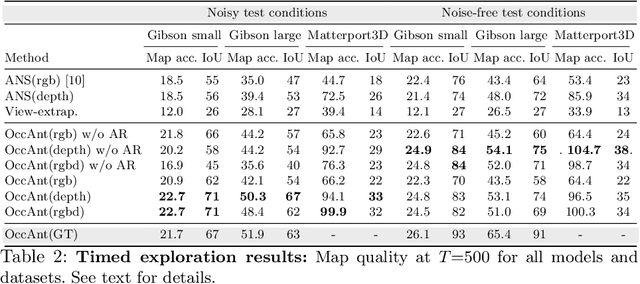
State-of-the-art navigation methods leverage a spatial memory to generalize to new environments, but their occupancy maps are limited to capturing the geometric structures directly observed by the agent. We propose occupancy anticipation, where the agent uses its egocentric RGB-D observations to infer the occupancy state beyond the visible regions. In doing so, the agent builds its spatial awareness more rapidly, which facilitates efficient exploration and navigation in 3D environments. By exploiting context in both the egocentric views and top-down maps our model successfully anticipates a broader map of the environment, with performance significantly better than strong baselines. Furthermore, when deployed for the sequential decision-making tasks of exploration and navigation, our model outperforms state-of-the-art methods on the Gibson and Matterport3D datasets. Our approach is the winning entry in the 2020 Habitat PointNav Challenge. Project page: http://vision.cs.utexas.edu/projects/occupancy_anticipation/
Audio-Visual Waypoints for Navigation
Aug 21, 2020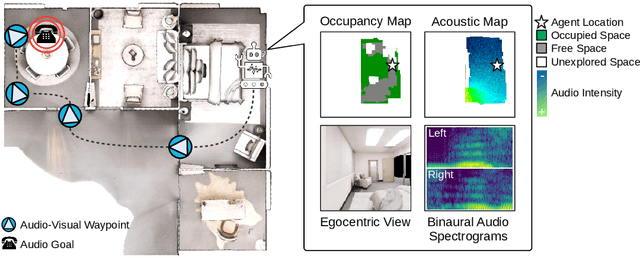
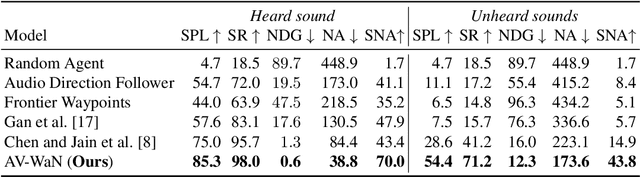
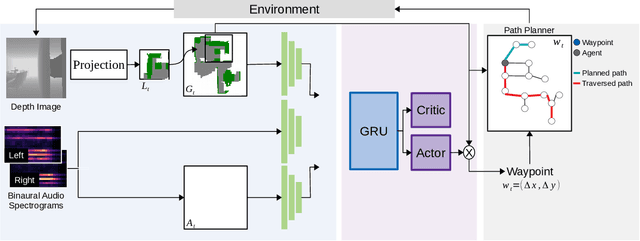
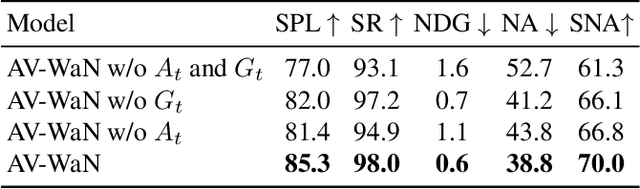
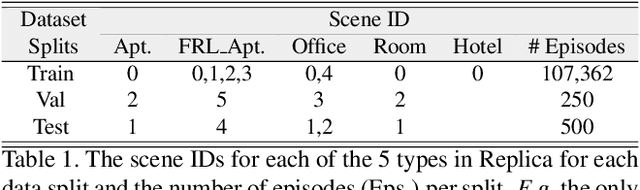
In audio-visual navigation, an agent intelligently travels through a complex, unmapped 3D environment using both sights and sounds to find a sound source (e.g., a phone ringing in another room). Existing models learn to act at a fixed granularity of agent motion and rely on simple recurrent aggregations of the audio observations. We introduce a reinforcement learning approach to audio-visual navigation with two key novel elements 1) audio-visual waypoints that are dynamically set and learned end-to-end within the navigation policy, and 2) an acoustic memory that provides a structured, spatially grounded record of what the agent has heard as it moves. Both new ideas capitalize on the synergy of audio and visual data for revealing the geometry of an unmapped space. We demonstrate our approach on the challenging Replica environments of real-world 3D scenes. Our model improves the state of the art by a substantial margin, and our experiments reveal that learning the links between sights, sounds, and space is essential for audio-visual navigation.
VisualEchoes: Spatial Image Representation Learning through Echolocation
May 04, 2020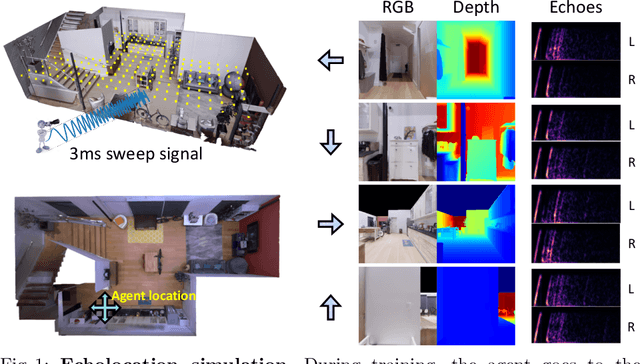

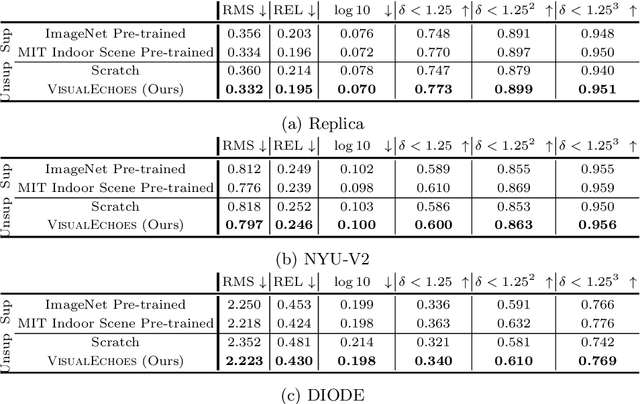
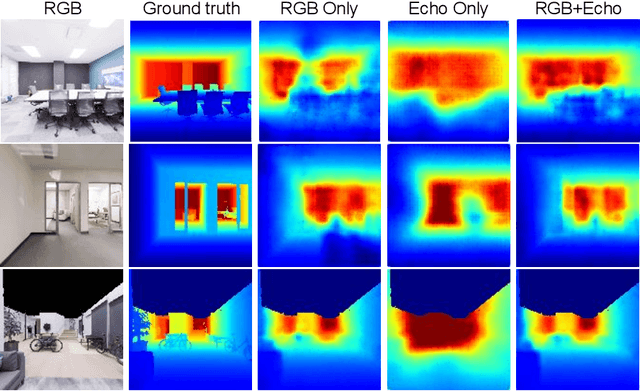
Several animal species (e.g., bats, dolphins, and whales) and even visually impaired humans have the remarkable ability to perform echolocation: a biological sonar used to perceive spatial layout and locate objects in the world. We explore the spatial cues contained in echoes and how they can benefit vision tasks that require spatial reasoning. First we capture echo responses in photo-realistic 3D indoor scene environments. Then we propose a novel interaction-based representation learning framework that learns useful visual features via echolocation. We show that the learned image features are useful for multiple downstream vision tasks requiring spatial reasoning---monocular depth estimation, surface normal estimation, and visual navigation. Our work opens a new path for representation learning for embodied agents, where supervision comes from interacting with the physical world. Our experiments demonstrate that our image features learned from echoes are comparable or even outperform heavily supervised pre-training methods for multiple fundamental spatial tasks.
From Paris to Berlin: Discovering Fashion Style Influences Around the World
Apr 03, 2020
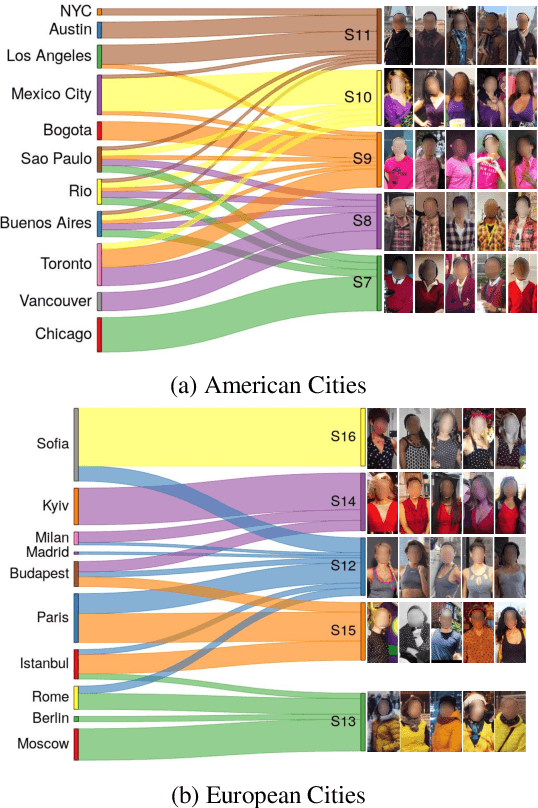
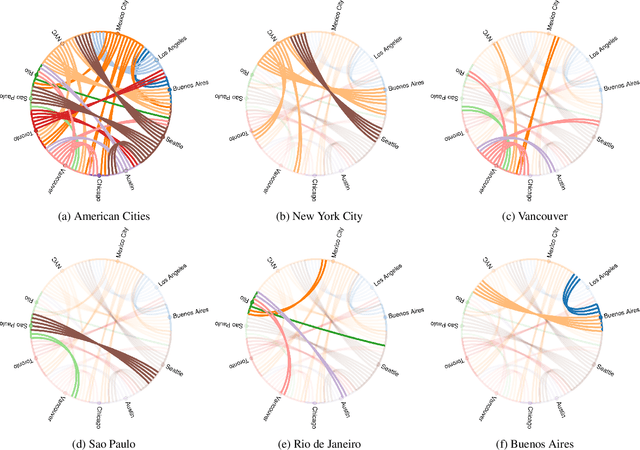
The evolution of clothing styles and their migration across the world is intriguing, yet difficult to describe quantitatively. We propose to discover and quantify fashion influences from everyday images of people wearing clothes. We introduce an approach that detects which cities influence which other cities in terms of propagating their styles. We then leverage the discovered influence patterns to inform a forecasting model that predicts the popularity of any given style at any given city into the future. Demonstrating our idea with GeoStyle---a large-scale dataset of 7.7M images covering 44 major world cities, we present the discovered influence relationships, revealing how cities exert and receive fashion influence for an array of 50 observed visual styles. Furthermore, the proposed forecasting model achieves state-of-the-art results for a challenging style forecasting task, showing the advantage of grounding visual style evolution both spatially and temporally.
Audio-Visual Embodied Navigation
Dec 24, 2019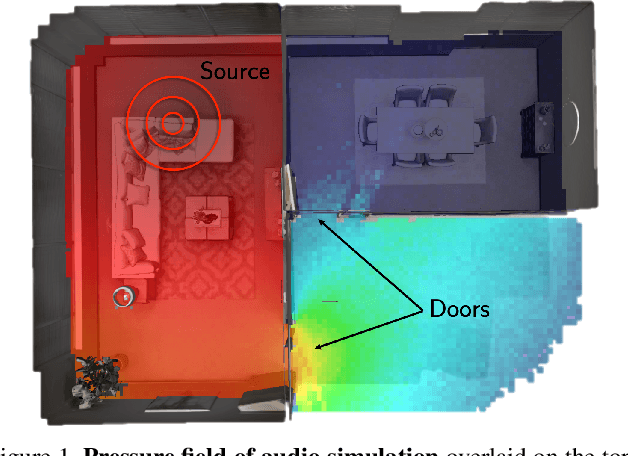


Moving around in the world is naturally a multisensory experience, but today's embodied agents are deaf - restricted to solely their visual perception of the environment. We introduce audio-visual navigation for complex, acoustically and visually realistic 3D environments. By both seeing and hearing, the agent must learn to navigate to an audio-based target. We develop a multi-modal deep reinforcement learning pipeline to train navigation policies end-to-end from a stream of egocentric audio-visual observations, allowing the agent to (1) discover elements of the geometry of the physical space indicated by the reverberating audio and (2) detect and follow sound-emitting targets. We further introduce audio renderings based on geometrical acoustic simulations for a set of publicly available 3D assets and instrument AI-Habitat to support the new sensor, making it possible to insert arbitrary sound sources in an array of apartment, office, and hotel environments. Our results show that audio greatly benefits embodied visual navigation in 3D spaces.
Smile, be Happy :) Emoji Embedding for Visual Sentiment Analysis
Jul 14, 2019
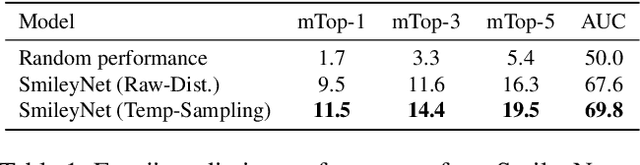
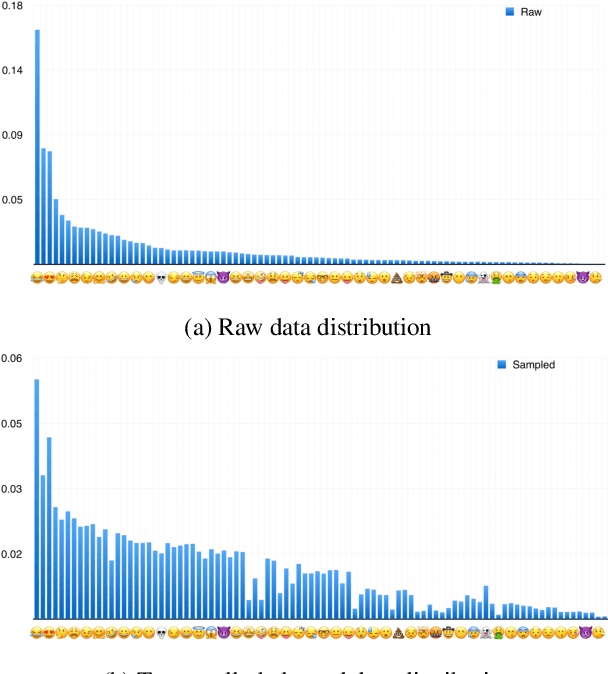
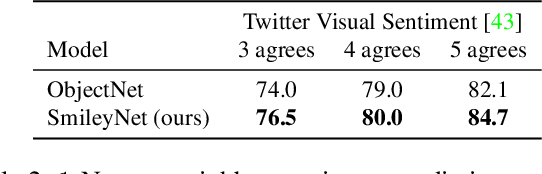
Due to the lack of large-scale datasets, the prevailing approach in visual sentiment analysis is to leverage models trained for object classification in large datasets like ImageNet. However, objects are sentiment neutral which hinders the expected gain of transfer learning for such tasks. In this work, we propose to overcome this problem by learning a novel sentiment-aligned image embedding that is better suited for subsequent visual sentiment analysis. Our embedding leverages the intricate relation between emojis and images in large-scale and readily available data from social media. Emojis are language-agnostic, consistent, and carry a clear sentiment signal which make them an excellent proxy to learn a sentiment aligned embedding. Hence, we construct a novel dataset of $4$ million images collected from Twitter with their associated emojis. We train a deep neural model for image embedding using emoji prediction task as a proxy. Our evaluation demonstrates that the proposed embedding outperforms the popular object-based counterpart consistently across several sentiment analysis benchmarks. Furthermore, without bell and whistles, our compact, effective and simple embedding outperforms the more elaborate and customized state-of-the-art deep models on these public benchmarks. Additionally, we introduce a novel emoji representation based on their visual emotional response which support a deeper understanding of the emoji modality and their usage on social media.