 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum Prompting Foundation Models for Medical Image Segmentation
Sep 01, 2024



Adapting large pre-trained foundation models, e.g., SAM, for medical image segmentation remains a significant challenge. A crucial step involves the formulation of a series of specialized prompts that incorporate specific clinical instructions. Past works have been heavily reliant on a singular type of prompt for each instance, necessitating manual input of an ideally correct prompt, which is less efficient. To tackle this issue, we propose to utilize prompts of different granularity, which are sourced from original images to provide a broader scope of clinical insights. However, combining prompts of varying types can pose a challenge due to potential conflicts. In response, we have designed a coarse-to-fine mechanism, referred to as curriculum prompting, that progressively integrates prompts of different types. Through extensive experiments on three public medical datasets across various modalities, we demonstrate the effectiveness of our proposed approach, which not only automates the prompt generation process but also yields superior performance compared to other SAM-based medical image segmentation methods. Code is available at: https://github.com/AnnaZzz-zxq/Curriculum-Prompting.
Camera-Invariant Meta-Learning Network for Single-Camera-Training Person Re-identification
Jun 21, 2024Single-camera-training person re-identification (SCT re-ID) aims to train a re-ID model using SCT datasets where each person appears in only one camera. The main challenge of SCT re-ID is to learn camera-invariant feature representations without cross-camera same-person (CCSP) data as supervision. Previous methods address it by assuming that the most similar person should be found in another camera. However, this assumption is not guaranteed to be correct. In this paper, we propose a Camera-Invariant Meta-Learning Network (CIMN) for SCT re-ID. CIMN assumes that the camera-invariant feature representations should be robust to camera changes. To this end, we split the training data into meta-train set and meta-test set based on camera IDs and perform a cross-camera simulation via meta-learning strategy, aiming to enforce the representations learned from the meta-train set to be robust to the meta-test set. With the cross-camera simulation, CIMN can learn camera-invariant and identity-discriminative representations even there are no CCSP data. However, this simulation also causes the separation of the meta-train set and the meta-test set, which ignores some beneficial relations between them. Thus, we introduce three losses: meta triplet loss, meta classification loss, and meta camera alignment loss, to leverage the ignored relations. The experiment results demonstrate that our method achieves comparable performance with and without CCSP data, and outperforms the state-of-the-art methods on SCT re-ID benchmarks. In addition, it is also effective in improving the domain generalization ability of the model.
Uncertainty-Induced Transferability Representation for Source-Free Unsupervised Domain Adaptation
Aug 30, 2022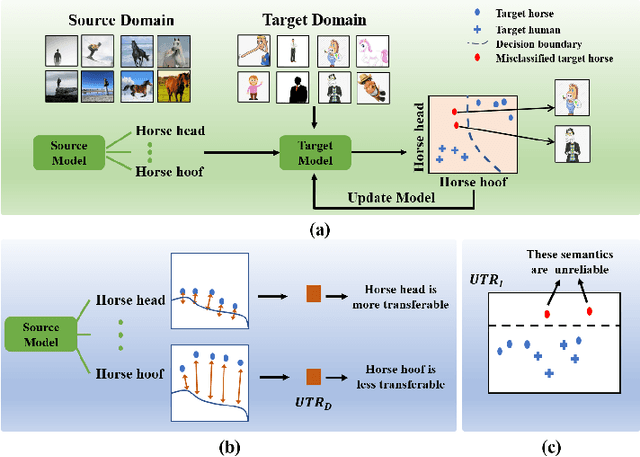

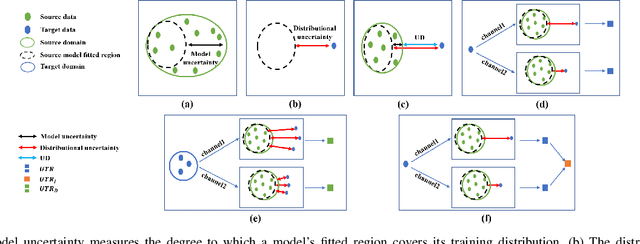
Source-free unsupervised domain adaptation (SFUDA) aims to learn a target domain model using unlabeled target data and the knowledge of a well-trained source domain model. Most previous SFUDA works focus on inferring semantics of target data based on the source knowledge. Without measuring the transferability of the source knowledge, these methods insufficiently exploit the source knowledge, and fail to identify the reliability of the inferred target semantics. However, existing transferability measurements require either source data or target labels, which are infeasible in SFUDA. To this end, firstly, we propose a novel Uncertainty-induced Transferability Representation (UTR), which leverages uncertainty as the tool to analyse the channel-wise transferability of the source encoder in the absence of the source data and target labels. The domain-level UTR unravels how transferable the encoder channels are to the target domain and the instance-level UTR characterizes the reliability of the inferred target semantics. Secondly, based on the UTR, we propose a novel Calibrated Adaption Framework (CAF) for SFUDA, including i)the source knowledge calibration module that guides the target model to learn the transferable source knowledge and discard the non-transferable one, and ii)the target semantics calibration module that calibrates the unreliable semantics. With the help of the calibrated source knowledge and the target semantics, the model adapts to the target domain safely and ultimately better. We verified the effectiveness of our method using experimental results and demonstrated that the proposed method achieves state-of-the-art performances on the three SFUDA benchmarks. Code is available at https://github.com/SPIresearch/UTR.
Delving into the Continuous Domain Adaptation
Aug 28, 2022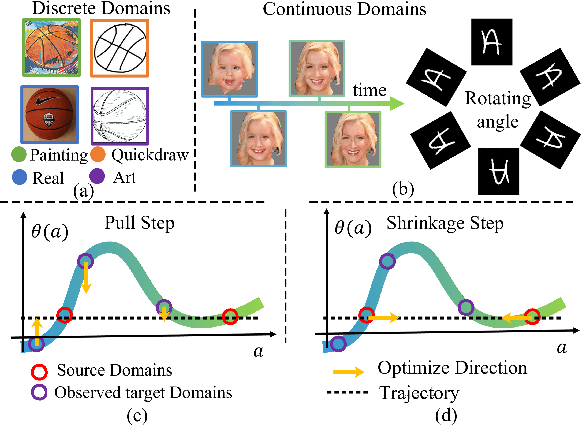

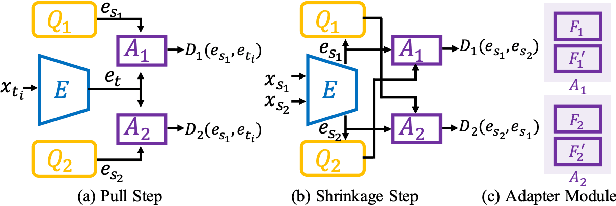
Existing domain adaptation methods assume that domain discrepancies are caused by a few discrete attributes and variations, e.g., art, real, painting, quickdraw, etc. We argue that this is not realistic as it is implausible to define the real-world datasets using a few discrete attributes. Therefore, we propose to investigate a new problem namely the Continuous Domain Adaptation (CDA) through the lens where infinite domains are formed by continuously varying attributes. Leveraging knowledge of two labeled source domains and several observed unlabeled target domains data, the objective of CDA is to learn a generalized model for whole data distribution with the continuous attribute. Besides the contributions of formulating a new problem, we also propose a novel approach as a strong CDA baseline. To be specific, firstly we propose a novel alternating training strategy to reduce discrepancies among multiple domains meanwhile generalize to unseen target domains. Secondly, we propose a continuity constraint when estimating the cross-domain divergence measurement. Finally, to decouple the discrepancy from the mini-batch size, we design a domain-specific queue to maintain the global view of the source domain that further boosts the adaptation performances. Our method is proven to achieve the state-of-the-art in CDA problem using extensive experiments. The code is available at https://github.com/SPIresearch/CDA.
Lvio-Fusion: A Self-adaptive Multi-sensor Fusion SLAM Framework Using Actor-critic Method
Jun 12, 2021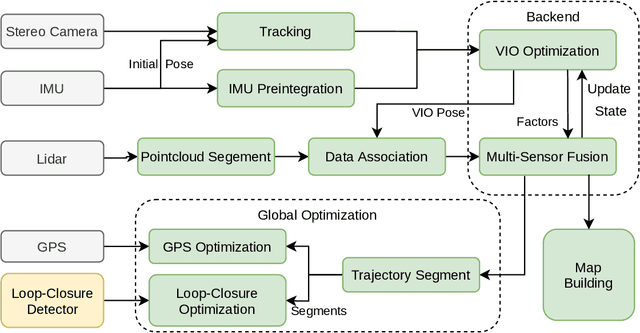
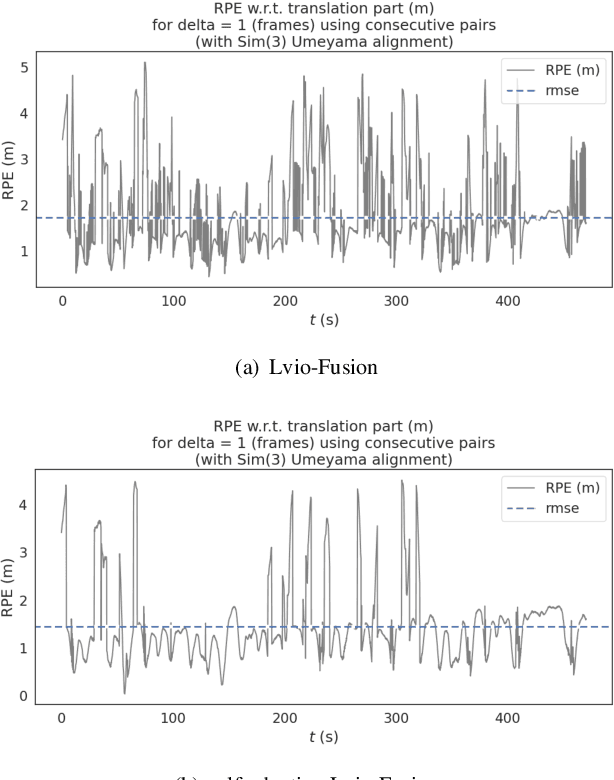

State estimation with sensors is essential for mobile robots. Due to sensors have different performance in different environments, how to fuse measurements of various sensors is a problem. In this paper, we propose a tightly-coupled multi-sensor fusion framework, Lvio-Fusion, which fuses stereo camera, Lidar, IMU, and GPS based on the graph optimization. Especially for urban traffic scenes, we introduce a segmented global pose graph optimization with GPS and loop-closure, which can eliminate accumulated drifts. Additionally, we creatively use a actor-critic method in reinforcement learning to adaptively adjust sensors' weight. After training, actor-critic agent can provide the system with better and dynamic sensors' weight. We evaluate the performance of our system on public datasets and compare it with other state-of-the-art methods, showing that the proposed method achieves high estimation accuracy and robustness to various environments. And our implementations are open source and highly scalable.
Rethinking the constraints of multimodal fusion: case study in Weakly-Supervised Audio-Visual Video Parsing
May 30, 2021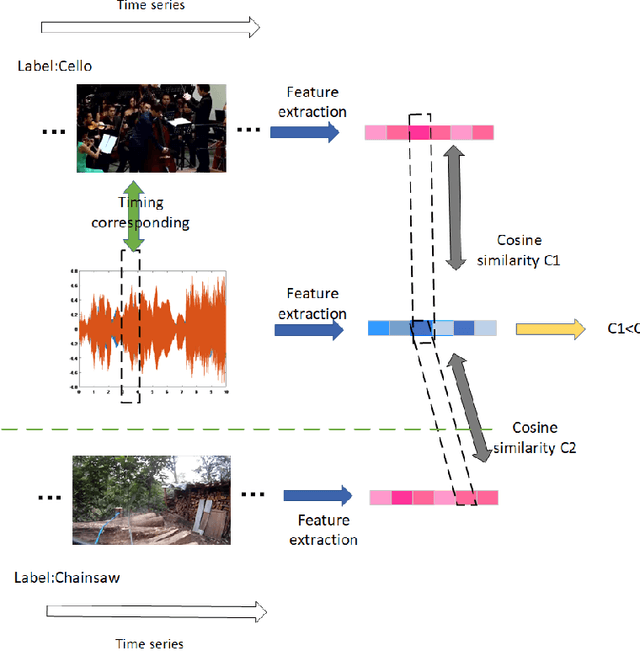

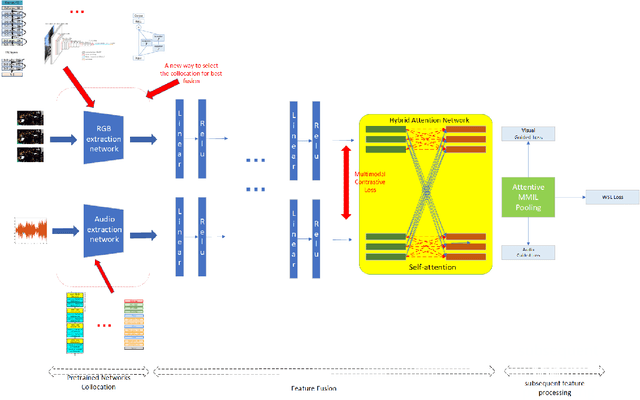
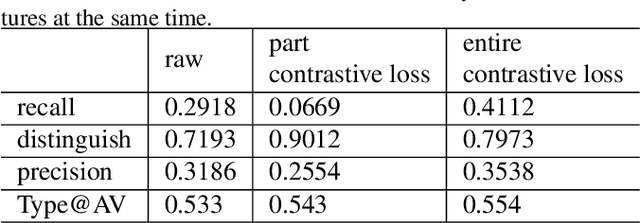
For multimodal tasks, a good feature extraction network should extract information as much as possible and ensure that the extracted feature embedding and other modal feature embedding have an excellent mutual understanding. The latter is often more critical in feature fusion than the former. Therefore, selecting the optimal feature extraction network collocation is a very important subproblem in multimodal tasks. Most of the existing studies ignore this problem or adopt an ergodic approach. This problem is modeled as an optimization problem in this paper. A novel method is proposed to convert the optimization problem into an issue of comparative upper bounds by referring to the general practice of extreme value conversion in mathematics. Compared with the traditional method, it reduces the time cost. Meanwhile, aiming at the common problem that the feature similarity and the feature semantic similarity are not aligned in the multimodal time-series problem, we refer to the idea of contrast learning and propose a multimodal time-series contrastive loss(MTSC). Based on the above issues, We demonstrated the feasibility of our approach in the audio-visual video parsing task. Substantial analyses verify that our methods promote the fusion of different modal features.
Taylor saves for later: disentanglement for video prediction using Taylor representation
May 24, 2021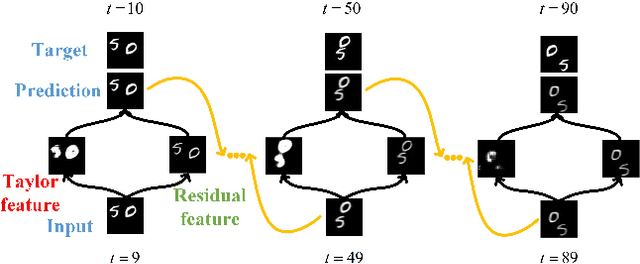
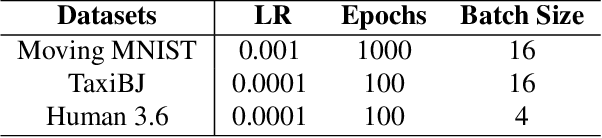
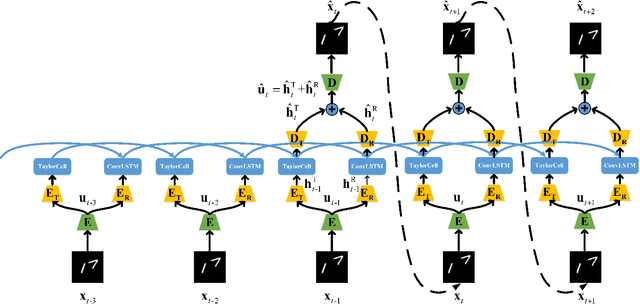
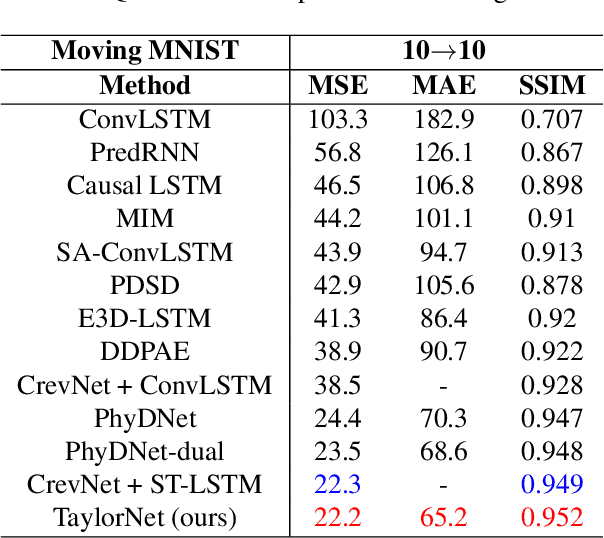
Video prediction is a challenging task with wide application prospects in meteorology and robot systems. Existing works fail to trade off short-term and long-term prediction performances and extract robust latent dynamics laws in video frames. We propose a two-branch seq-to-seq deep model to disentangle the Taylor feature and the residual feature in video frames by a novel recurrent prediction module (TaylorCell) and residual module. TaylorCell can expand the video frames' high-dimensional features into the finite Taylor series to describe the latent laws. In TaylorCell, we propose the Taylor prediction unit (TPU) and the memory correction unit (MCU). TPU employs the first input frame's derivative information to predict the future frames, avoiding error accumulation. MCU distills all past frames' information to correct the predicted Taylor feature from TPU. Correspondingly, the residual module extracts the residual feature complementary to the Taylor feature. On three generalist datasets (Moving MNIST, TaxiBJ, Human 3.6), our model outperforms or reaches state-of-the-art models, and ablation experiments demonstrate the effectiveness of our model in long-term prediction.
Bridge the Vision Gap from Field to Command: A Deep Learning Network Enhancing Illumination and Details
Jan 20, 2021


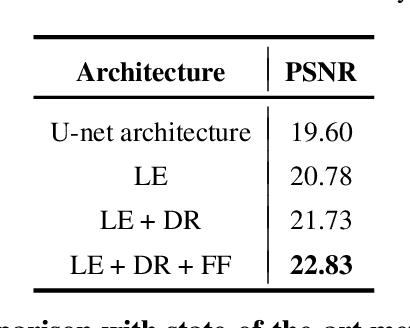
With the goal of tuning up the brightness, low-light image enhancement enjoys numerous applications, such as surveillance, remote sensing and computational photography. Images captured under low-light conditions often suffer from poor visibility and blur. Solely brightening the dark regions will inevitably amplify the blur, thus may lead to detail loss. In this paper, we propose a simple yet effective two-stream framework named NEID to tune up the brightness and enhance the details simultaneously without introducing many computational costs. Precisely, the proposed method consists of three parts: Light Enhancement (LE), Detail Refinement (DR) and Feature Fusing (FF) module, which can aggregate composite features oriented to multiple tasks based on channel attention mechanism. Extensive experiments conducted on several benchmark datasets demonstrate the efficacy of our method and its superiority over state-of-the-art methods.
Shed Various Lights on a Low-Light Image: Multi-Level Enhancement Guided by Arbitrary References
Jan 04, 2021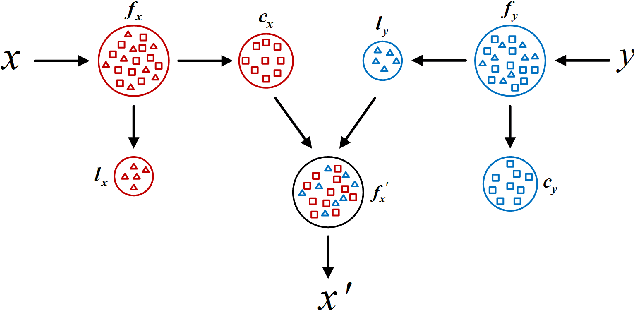

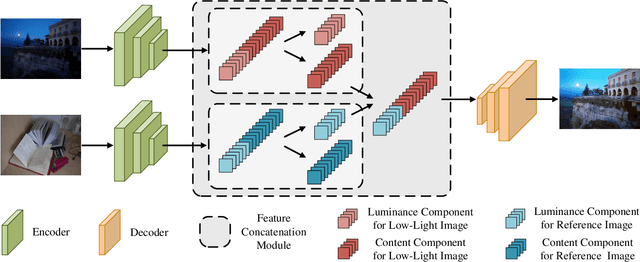

It is suggested that low-light image enhancement realizes one-to-many mapping since we have different definitions of NORMAL-light given application scenarios or users' aesthetic. However, most existing methods ignore subjectivity of the task, and simply produce one result with fixed brightness. This paper proposes a neural network for multi-level low-light image enhancement, which is user-friendly to meet various requirements by selecting different images as brightness reference. Inspired by style transfer, our method decomposes an image into two low-coupling feature components in the latent space, which allows the concatenation feasibility of the content components from low-light images and the luminance components from reference images. In such a way, the network learns to extract scene-invariant and brightness-specific information from a set of image pairs instead of learning brightness differences. Moreover, information except for the brightness is preserved to the greatest extent to alleviate color distortion. Extensive results show strong capacity and superiority of our network against existing methods.
A Switched View of Retinex: Deep Self-Regularized Low-Light Image Enhancement
Jan 03, 2021
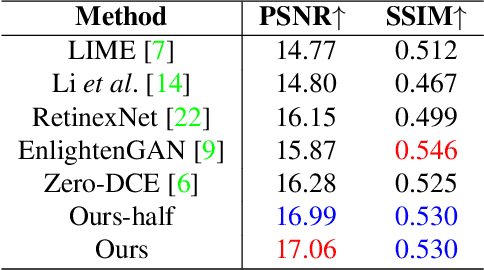
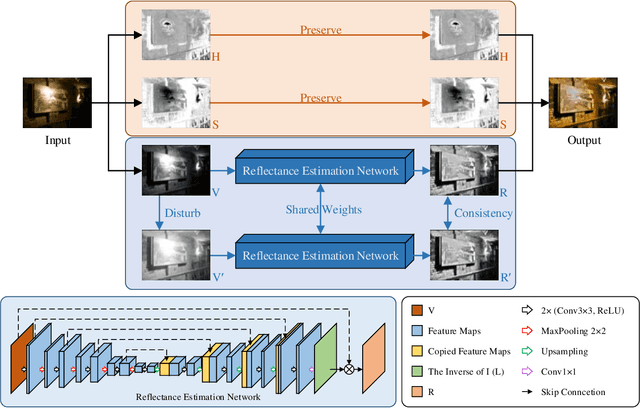
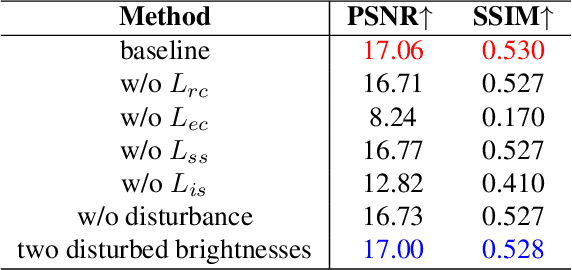
Self-regularized low-light image enhancement does not require any normal-light image in training, thereby freeing from the chains on paired or unpaired low-/normal-images. However, existing methods suffer color deviation and fail to generalize to various lighting conditions. This paper presents a novel self-regularized method based on Retinex, which, inspired by HSV, preserves all colors (Hue, Saturation) and only integrates Retinex theory into brightness (Value). We build a reflectance estimation network by restricting the consistency of reflectances embedded in both the original and a novel random disturbed form of the brightness of the same scene. The generated reflectance, which is assumed to be irrelevant of illumination by Retinex, is treated as enhanced brightness. Our method is efficient as a low-light image is decoupled into two subspaces, color and brightness, for better preservation and enhancement. Extensive experiments demonstrate that our method outperforms multiple state-of-the-art algorithms qualitatively and quantitatively and adapts to more lighting conditions.