 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobal Convergence of Policy Gradient for Linear-Quadratic Mean-Field Control/Game in Continuous Time
Aug 16, 2020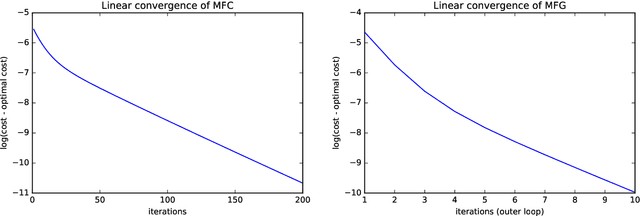
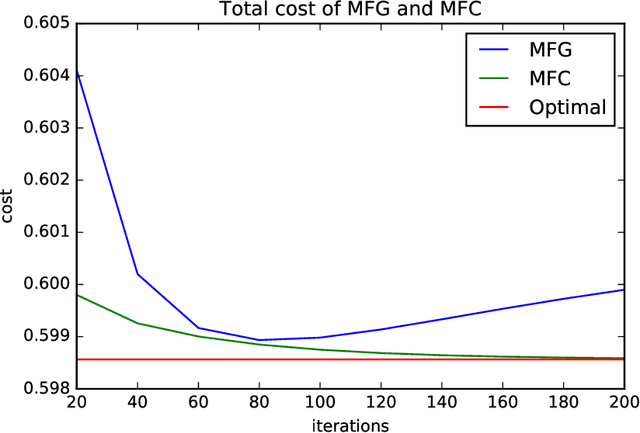
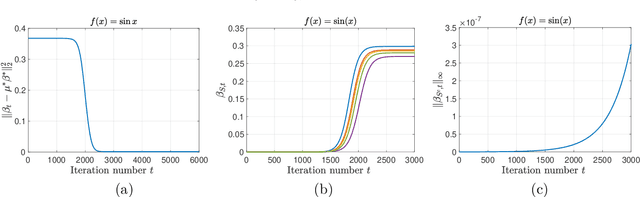
Reinforcement learning is a powerful tool to learn the optimal policy of possibly multiple agents by interacting with the environment. As the number of agents grow to be very large, the system can be approximated by a mean-field problem. Therefore, it has motivated new research directions for mean-field control (MFC) and mean-field game (MFG). In this paper, we study the policy gradient method for the linear-quadratic mean-field control and game, where we assume each agent has identical linear state transitions and quadratic cost functions. While most of the recent works on policy gradient for MFC and MFG are based on discrete-time models, we focus on the continuous-time models where some analyzing techniques can be interesting to the readers. For both MFC and MFG, we provide policy gradient update and show that it converges to the optimal solution at a linear rate, which is verified by a synthetic simulation. For MFG, we also provide sufficient conditions for the existence and uniqueness of the Nash equilibrium.
Single-Timescale Actor-Critic Provably Finds Globally Optimal Policy
Aug 02, 2020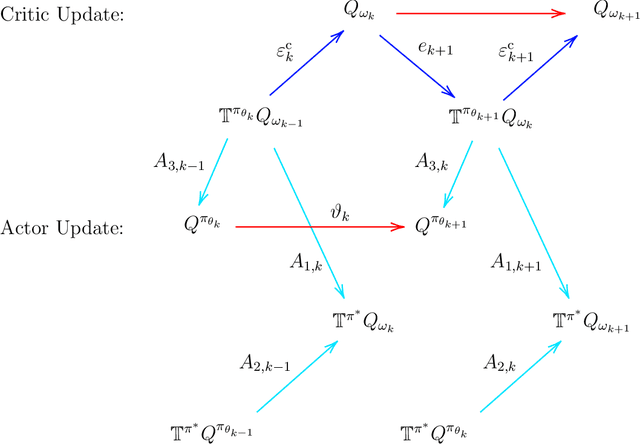
We study the global convergence and global optimality of actor-critic, one of the most popular families of reinforcement learning algorithms. While most existing works on actor-critic employ bi-level or two-timescale updates, we focus on the more practical single-timescale setting, where the actor and critic are updated simultaneously. Specifically, in each iteration, the critic update is obtained by applying the Bellman evaluation operator only once while the actor is updated in the policy gradient direction computed using the critic. Moreover, we consider two function approximation settings where both the actor and critic are represented by linear or deep neural networks. For both cases, we prove that the actor sequence converges to a globally optimal policy at a sublinear $O(K^{-1/2})$ rate, where $K$ is the number of iterations. To the best of our knowledge, we establish the rate of convergence and global optimality of single-timescale actor-critic with linear function approximation for the first time. Moreover, under the broader scope of policy optimization with nonlinear function approximation, we prove that actor-critic with deep neural network finds the globally optimal policy at a sublinear rate for the first time.
Understanding Implicit Regularization in Over-Parameterized Nonlinear Statistical Model
Jul 16, 2020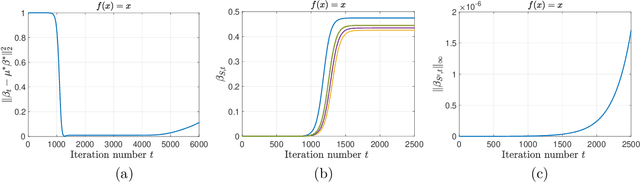
We study the implicit regularization phenomenon induced by simple optimization algorithms in over-parameterized nonlinear statistical models. Specifically, we study both vector and matrix single index models where the link function is nonlinear and unknown, the signal parameter is either a sparse vector or a low-rank symmetric matrix, and the response variable can be heavy-tailed. To gain a better understanding the role of implicit regularization in the nonlinear models without excess technicality, we assume that the distribution of the covariates is known as a priori. For both the vector and matrix settings, we construct an over-parameterized least-squares loss function by employing the score function transform and a robust truncation step designed specifically for heavy-tailed data. We propose to estimate the true parameter by applying regularization-free gradient descent to the loss function. When the initialization is close to the origin and the stepsize is sufficiently small, we prove that the obtained solution achieves minimax optimal statistical rates of convergence in both the vector and matrix cases. In particular, for the vector single index model with Gaussian covariates, our proposed estimator is shown to enjoy the oracle statistical rate. Our results capture the implicit regularization phenomenon in over-parameterized nonlinear and noisy statistical models with possibly heavy-tailed data.
A Two-Timescale Framework for Bilevel Optimization: Complexity Analysis and Application to Actor-Critic
Jul 10, 2020
This paper analyzes a two-timescale stochastic algorithm for a class of bilevel optimization problems with applications such as policy optimization in reinforcement learning, hyperparameter optimization, among others. We consider a case when the inner problem is unconstrained and strongly convex, and the outer problem is either strongly convex, convex or weakly convex. We propose a nonlinear two-timescale stochastic approximation (TTSA) algorithm for tackling the bilevel optimization. In the algorithm, a stochastic (semi)gradient update with a larger step size (faster timescale) is used for the inner problem, while a stochastic mirror descent update with a smaller step size (slower timescale) is used for the outer problem. When the outer problem is strongly convex (resp. weakly convex), the TTSA algorithm finds an $\mathcal{O}(K^{-1/2})$-optimal (resp. $\mathcal{O}(K^{-2/5})$-stationary) solution, where $K$ is the iteration number. To our best knowledge, these are the first convergence rate results for using nonlinear TTSA algorithms on the concerned class of bilevel optimization problems. Lastly, specific to the application of policy optimization, we show that a two-timescale actor-critic proximal policy optimization algorithm can be viewed as a special case of our framework. The actor-critic algorithm converges at $\mathcal{O}(K^{-1/4})$ in terms of the gap in objective value to a globally optimal policy.
Provably Efficient Neural Estimation of Structural Equation Model: An Adversarial Approach
Jul 02, 2020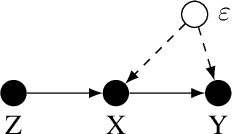
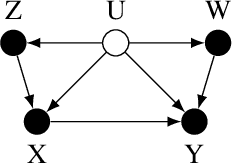
Structural equation models (SEMs) are widely used in sciences, ranging from economics to psychology, to uncover causal relationships underlying a complex system under consideration and estimate structural parameters of interest. We study estimation in a class of generalized SEMs where the object of interest is defined as the solution to a linear operator equation. We formulate the linear operator equation as a min-max game, where both players are parameterized by neural networks (NNs), and learn the parameters of these neural networks using the stochastic gradient descent. We consider both 2-layer and multi-layer NNs with ReLU activation functions and prove global convergence in an overparametrized regime, where the number of neurons is diverging. The results are established using techniques from online learning and local linearization of NNs, and improve in several aspects the current state-of-the-art. For the first time we provide a tractable estimation procedure for SEMs based on NNs with provable convergence and without the need for sample splitting.
Dynamic Regret of Policy Optimization in Non-stationary Environments
Jun 30, 2020We consider reinforcement learning (RL) in episodic MDPs with adversarial full-information reward feedback and unknown fixed transition kernels. We propose two model-free policy optimization algorithms, POWER and POWER++, and establish guarantees for their dynamic regret. Compared with the classical notion of static regret, dynamic regret is a stronger notion as it explicitly accounts for the non-stationarity of environments. The dynamic regret attained by the proposed algorithms interpolates between different regimes of non-stationarity, and moreover satisfies a notion of adaptive (near-)optimality, in the sense that it matches the (near-)optimal static regret under slow-changing environments. The dynamic regret bound features two components, one arising from exploration, which deals with the uncertainty of transition kernels, and the other arising from adaptation, which deals with non-stationary environments. Specifically, we show that POWER++ improves over POWER on the second component of the dynamic regret by actively adapting to non-stationarity through prediction. To the best of our knowledge, our work is the first dynamic regret analysis of model-free RL algorithms in non-stationary environments.
On the Global Optimality of Model-Agnostic Meta-Learning
Jun 23, 2020Model-agnostic meta-learning (MAML) formulates meta-learning as a bilevel optimization problem, where the inner level solves each subtask based on a shared prior, while the outer level searches for the optimal shared prior by optimizing its aggregated performance over all the subtasks. Despite its empirical success, MAML remains less understood in theory, especially in terms of its global optimality, due to the nonconvexity of the meta-objective (the outer-level objective). To bridge such a gap between theory and practice, we characterize the optimality gap of the stationary points attained by MAML for both reinforcement learning and supervised learning, where the inner-level and outer-level problems are solved via first-order optimization methods. In particular, our characterization connects the optimality gap of such stationary points with (i) the functional geometry of inner-level objectives and (ii) the representation power of function approximators, including linear models and neural networks. To the best of our knowledge, our analysis establishes the global optimality of MAML with nonconvex meta-objectives for the first time.
Risk-Sensitive Reinforcement Learning: Near-Optimal Risk-Sample Tradeoff in Regret
Jun 22, 2020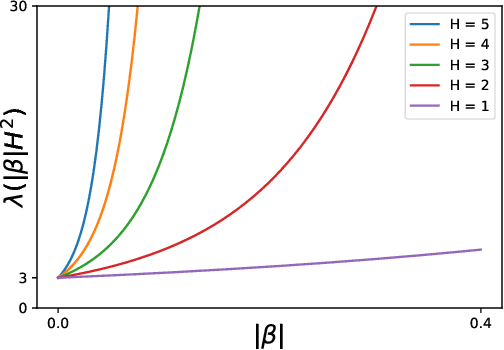
We study risk-sensitive reinforcement learning in episodic Markov decision processes with unknown transition kernels, where the goal is to optimize the total reward under the risk measure of exponential utility. We propose two provably efficient model-free algorithms, Risk-Sensitive Value Iteration (RSVI) and Risk-Sensitive Q-learning (RSQ). These algorithms implement a form of risk-sensitive optimism in the face of uncertainty, which adapts to both risk-seeking and risk-averse modes of exploration. We prove that RSVI attains an $\tilde{O}\big(\lambda(|\beta| H^2) \cdot \sqrt{H^{3} S^{2}AT} \big)$ regret, while RSQ attains an $\tilde{O}\big(\lambda(|\beta| H^2) \cdot \sqrt{H^{4} SAT} \big)$ regret, where $\lambda(u) = (e^{3u}-1)/u$ for $u>0$. In the above, $\beta$ is the risk parameter of the exponential utility function, $S$ the number of states, $A$ the number of actions, $T$ the total number of timesteps, and $H$ the episode length. On the flip side, we establish a regret lower bound showing that the exponential dependence on $|\beta|$ and $H$ is unavoidable for any algorithm with an $\tilde{O}(\sqrt{T})$ regret (even when the risk objective is on the same scale as the original reward), thus certifying the near-optimality of the proposed algorithms. Our results demonstrate that incorporating risk awareness into reinforcement learning necessitates an exponential cost in $|\beta|$ and $H$, which quantifies the fundamental tradeoff between risk sensitivity (related to aleatoric uncertainty) and sample efficiency (related to epistemic uncertainty). To the best of our knowledge, this is the first regret analysis of risk-sensitive reinforcement learning with the exponential utility.
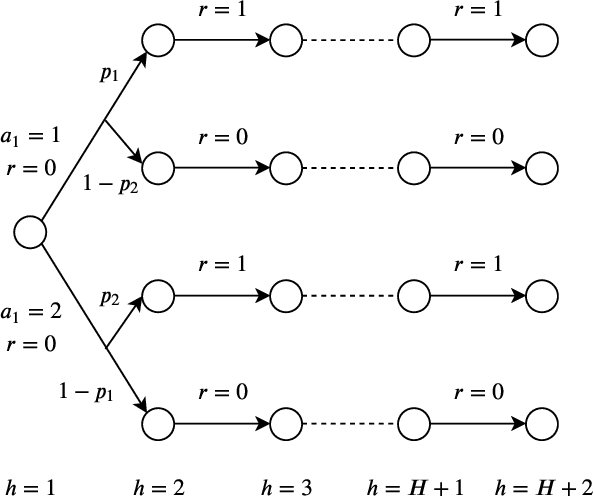
Provably Efficient Causal Reinforcement Learning with Confounded Observational Data
Jun 22, 2020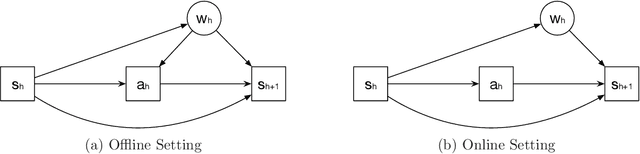
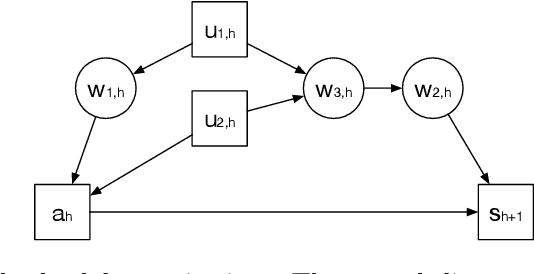
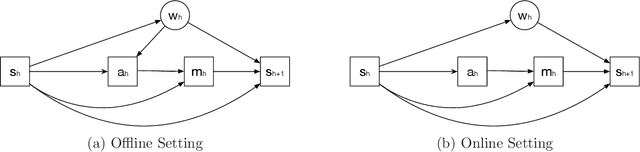
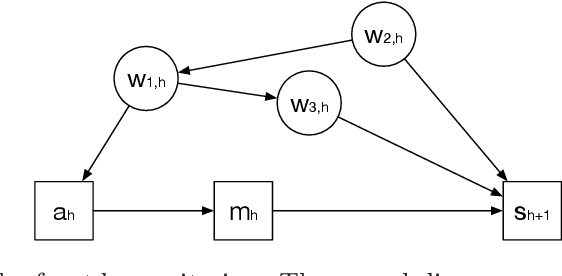
Empowered by expressive function approximators such as neural networks, deep reinforcement learning (DRL) achieves tremendous empirical successes. However, learning expressive function approximators requires collecting a large dataset (interventional data) by interacting with the environment. Such a lack of sample efficiency prohibits the application of DRL to critical scenarios, e.g., autonomous driving and personalized medicine, since trial and error in the online setting is often unsafe and even unethical. In this paper, we study how to incorporate the dataset (observational data) collected offline, which is often abundantly available in practice, to improve the sample efficiency in the online setting. To incorporate the possibly confounded observational data, we propose the deconfounded optimistic value iteration (DOVI) algorithm, which incorporates the confounded observational data in a provably efficient manner. More specifically, DOVI explicitly adjusts for the confounding bias in the observational data, where the confounders are partially observed or unobserved. In both cases, such adjustments allow us to construct the bonus based on a notion of information gain, which takes into account the amount of information acquired from the offline setting. In particular, we prove that the regret of DOVI is smaller than the optimal regret achievable in the pure online setting by a multiplicative factor, which decreases towards zero when the confounded observational data are more informative upon the adjustments. Our algorithm and analysis serve as a step towards causal reinforcement learning.
Breaking the Curse of Many Agents: Provable Mean Embedding Q-Iteration for Mean-Field Reinforcement Learning
Jun 21, 2020Multi-agent reinforcement learning (MARL) achieves significant empirical successes. However, MARL suffers from the curse of many agents. In this paper, we exploit the symmetry of agents in MARL. In the most generic form, we study a mean-field MARL problem. Such a mean-field MARL is defined on mean-field states, which are distributions that are supported on continuous space. Based on the mean embedding of the distributions, we propose MF-FQI algorithm that solves the mean-field MARL and establishes a non-asymptotic analysis for MF-FQI algorithm. We highlight that MF-FQI algorithm enjoys a "blessing of many agents" property in the sense that a larger number of observed agents improves the performance of MF-FQI algorithm.