 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniX: Unifying Autoregression and Diffusion for Chest X-Ray Understanding and Generation
Jan 16, 2026Despite recent progress, medical foundation models still struggle to unify visual understanding and generation, as these tasks have inherently conflicting goals: semantic abstraction versus pixel-level reconstruction. Existing approaches, typically based on parameter-shared autoregressive architectures, frequently lead to compromised performance in one or both tasks. To address this, we present UniX, a next-generation unified medical foundation model for chest X-ray understanding and generation. UniX decouples the two tasks into an autoregressive branch for understanding and a diffusion branch for high-fidelity generation. Crucially, a cross-modal self-attention mechanism is introduced to dynamically guide the generation process with understanding features. Coupled with a rigorous data cleaning pipeline and a multi-stage training strategy, this architecture enables synergistic collaboration between tasks while leveraging the strengths of diffusion models for superior generation. On two representative benchmarks, UniX achieves a 46.1% improvement in understanding performance (Micro-F1) and a 24.2% gain in generation quality (FD-RadDino), using only a quarter of the parameters of LLM-CXR. By achieving performance on par with task-specific models, our work establishes a scalable paradigm for synergistic medical image understanding and generation. Codes and models are available at https://github.com/ZrH42/UniX.
OpenGround: Active Cognition-based Reasoning for Open-World 3D Visual Grounding
Dec 31, 20253D visual grounding aims to locate objects based on natural language descriptions in 3D scenes. Existing methods rely on a pre-defined Object Lookup Table (OLT) to query Visual Language Models (VLMs) for reasoning about object locations, which limits the applications in scenarios with undefined or unforeseen targets. To address this problem, we present OpenGround, a novel zero-shot framework for open-world 3D visual grounding. Central to OpenGround is the Active Cognition-based Reasoning (ACR) module, which is designed to overcome the fundamental limitation of pre-defined OLTs by progressively augmenting the cognitive scope of VLMs. The ACR module performs human-like perception of the target via a cognitive task chain and actively reasons about contextually relevant objects, thereby extending VLM cognition through a dynamically updated OLT. This allows OpenGround to function with both pre-defined and open-world categories. We also propose a new dataset named OpenTarget, which contains over 7000 object-description pairs to evaluate our method in open-world scenarios. Extensive experiments demonstrate that OpenGround achieves competitive performance on Nr3D, state-of-the-art on ScanRefer, and delivers a substantial 17.6% improvement on OpenTarget. Project Page at https://why-102.github.io/openground.io/.
Raw Bayer Pattern Image Synthesis with Conditional GAN
Oct 25, 2021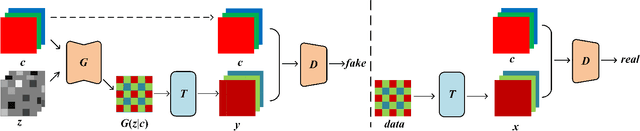
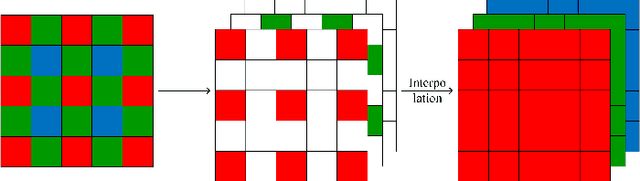

In this paper, we propose a method to generate Bayer pattern images by Generative adversarial network (GANs). It is shown theoretically that using the transformed data in GANs training is able to improve the generator learning of the original data distribution, owing to the invariant of Jensen Shannon(JS) divergence between two distributions under invertible and differentiable transformation. The Bayer pattern images can be generated by configuring the transformation as demosaicing, by converting the existing standard color datasets to Bayer domain, the proposed method is promising in the applications such as to find the optimal ISP configuration for computer vision tasks, in the in sensor or near sensor computing, even in photography. Experiments show that the images generated by our proposed method outperform the original Pix2PixHD model in FID score, PSNR, and SSIM, and the training process is more stable. For the situation similar to in sensor or near sensor computing for object detection, by using our proposed method, the model performance can be improved without the modification to the image sensor.
The Impact of ASR on the Automatic Analysis of Linguistic Complexity and Sophistication in Spontaneous L2 Speech
Apr 17, 2021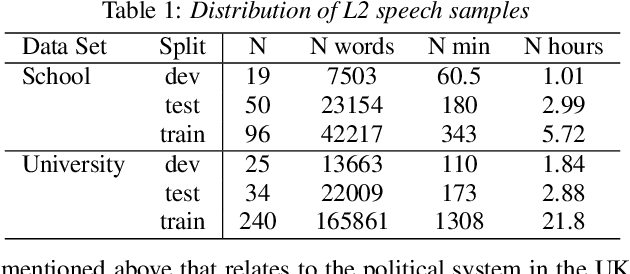
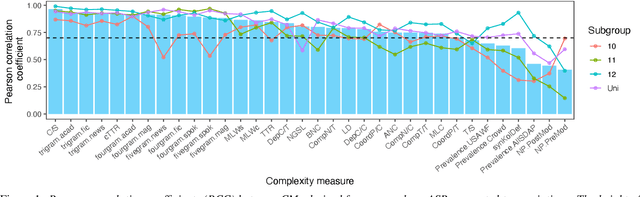
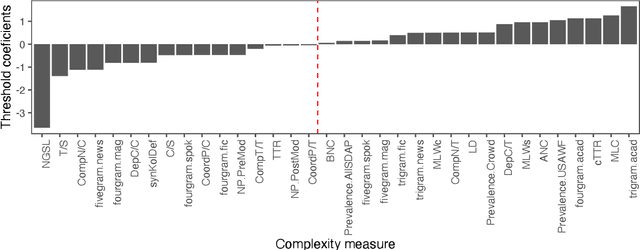
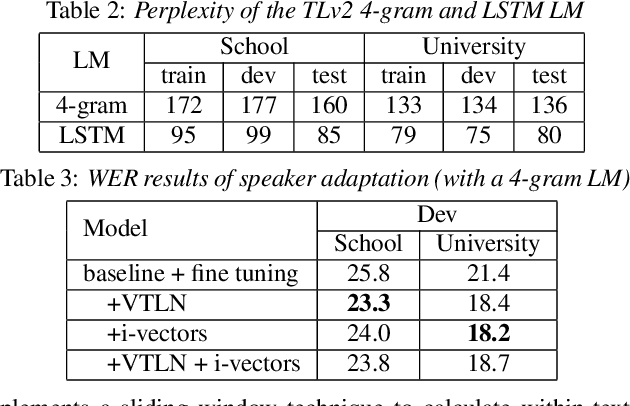
In recent years, automated approaches to assessing linguistic complexity in second language (L2) writing have made significant progress in gauging learner performance, predicting human ratings of the quality of learner productions, and benchmarking L2 development. In contrast, there is comparatively little work in the area of speaking, particularly with respect to fully automated approaches to assessing L2 spontaneous speech. While the importance of a well-performing ASR system is widely recognized, little research has been conducted to investigate the impact of its performance on subsequent automatic text analysis. In this paper, we focus on this issue and examine the impact of using a state-of-the-art ASR system for subsequent automatic analysis of linguistic complexity in spontaneously produced L2 speech. A set of 34 selected measures were considered, falling into four categories: syntactic, lexical, n-gram frequency, and information-theoretic measures. The agreement between the scores for these measures obtained on the basis of ASR-generated vs. manual transcriptions was determined through correlation analysis. A more differential effect of ASR performance on specific types of complexity measures when controlling for task type effects is also presented.