 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree of Attributes Prompt Learning for Vision-Language Models
Oct 15, 2024



Prompt learning has proven effective in adapting vision language models for downstream tasks. However, existing methods usually append learnable prompt tokens solely with the category names to obtain textual features, which fails to fully leverage the rich context indicated in the category name. To address this issue, we propose the Tree of Attributes Prompt learning (TAP), which first instructs LLMs to generate a tree of attributes with a "concept - attribute - description" structure for each category, and then learn the hierarchy with vision and text prompt tokens. Unlike existing methods that merely augment category names with a set of unstructured descriptions, our approach essentially distills structured knowledge graphs associated with class names from LLMs. Furthermore, our approach introduces text and vision prompts designed to explicitly learn the corresponding visual attributes, effectively serving as domain experts. Additionally, the general and diverse descriptions generated based on the class names may be wrong or absent in the specific given images. To address this misalignment, we further introduce a vision-conditional pooling module to extract instance-specific text features. Extensive experimental results demonstrate that our approach outperforms state-of-the-art methods on the zero-shot base-to-novel generalization, cross-dataset transfer, as well as few-shot classification across 11 diverse datasets.
Pytorch-Wildlife: A Collaborative Deep Learning Framework for Conservation
May 21, 2024

The alarming decline in global biodiversity, driven by various factors, underscores the urgent need for large-scale wildlife monitoring. In response, scientists have turned to automated deep learning methods for data processing in wildlife monitoring. However, applying these advanced methods in real-world scenarios is challenging due to their complexity and the need for specialized knowledge, primarily because of technical challenges and interdisciplinary barriers. To address these challenges, we introduce Pytorch-Wildlife, an open-source deep learning platform built on PyTorch. It is designed for creating, modifying, and sharing powerful AI models. This platform emphasizes usability and accessibility, making it accessible to individuals with limited or no technical background. It also offers a modular codebase to simplify feature expansion and further development. Pytorch-Wildlife offers an intuitive, user-friendly interface, accessible through local installation or Hugging Face, for animal detection and classification in images and videos. As two real-world applications, Pytorch-Wildlife has been utilized to train animal classification models for species recognition in the Amazon Rainforest and for invasive opossum recognition in the Galapagos Islands. The Opossum model achieves 98% accuracy, and the Amazon model has 92% recognition accuracy for 36 animals in 90% of the data. As Pytorch-Wildlife evolves, we aim to integrate more conservation tasks, addressing various environmental challenges. Pytorch-Wildlife is available at https://github.com/microsoft/CameraTraps.
Multimodal Foundation Models for Zero-shot Animal Species Recognition in Camera Trap Images
Nov 02, 2023



Due to deteriorating environmental conditions and increasing human activity, conservation efforts directed towards wildlife is crucial. Motion-activated camera traps constitute an efficient tool for tracking and monitoring wildlife populations across the globe. Supervised learning techniques have been successfully deployed to analyze such imagery, however training such techniques requires annotations from experts. Reducing the reliance on costly labelled data therefore has immense potential in developing large-scale wildlife tracking solutions with markedly less human labor. In this work we propose WildMatch, a novel zero-shot species classification framework that leverages multimodal foundation models. In particular, we instruction tune vision-language models to generate detailed visual descriptions of camera trap images using similar terminology to experts. Then, we match the generated caption to an external knowledge base of descriptions in order to determine the species in a zero-shot manner. We investigate techniques to build instruction tuning datasets for detailed animal description generation and propose a novel knowledge augmentation technique to enhance caption quality. We demonstrate the performance of WildMatch on a new camera trap dataset collected in the Magdalena Medio region of Colombia.
Open Long-Tailed Recognition in a Dynamic World
Aug 17, 2022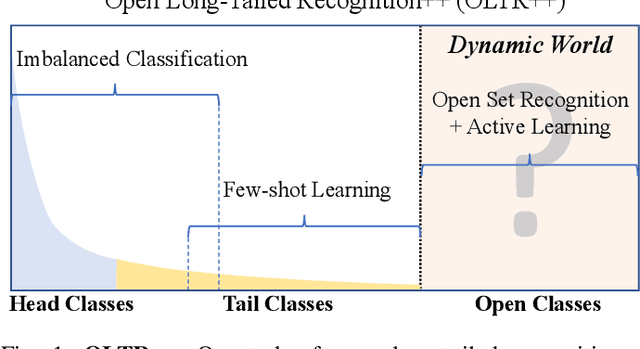
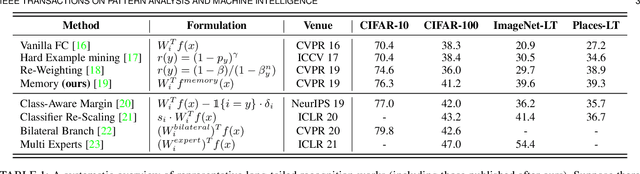
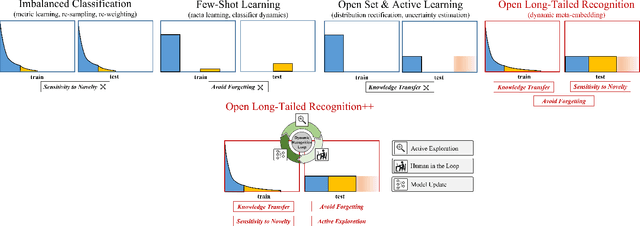

Real world data often exhibits a long-tailed and open-ended (with unseen classes) distribution. A practical recognition system must balance between majority (head) and minority (tail) classes, generalize across the distribution, and acknowledge novelty upon the instances of unseen classes (open classes). We define Open Long-Tailed Recognition++ (OLTR++) as learning from such naturally distributed data and optimizing for the classification accuracy over a balanced test set which includes both known and open classes. OLTR++ handles imbalanced classification, few-shot learning, open-set recognition, and active learning in one integrated algorithm, whereas existing classification approaches often focus only on one or two aspects and deliver poorly over the entire spectrum. The key challenges are: 1) how to share visual knowledge between head and tail classes, 2) how to reduce confusion between tail and open classes, and 3) how to actively explore open classes with learned knowledge. Our algorithm, OLTR++, maps images to a feature space such that visual concepts can relate to each other through a memory association mechanism and a learned metric (dynamic meta-embedding) that both respects the closed world classification of seen classes and acknowledges the novelty of open classes. Additionally, we propose an active learning scheme based on visual memory, which learns to recognize open classes in a data-efficient manner for future expansions. On three large-scale open long-tailed datasets we curated from ImageNet (object-centric), Places (scene-centric), and MS1M (face-centric) data, as well as three standard benchmarks (CIFAR-10-LT, CIFAR-100-LT, and iNaturalist-18), our approach, as a unified framework, consistently demonstrates competitive performance. Notably, our approach also shows strong potential for the active exploration of open classes and the fairness analysis of minority groups.
Iterative Human and Automated Identification of Wildlife Images
May 05, 2021
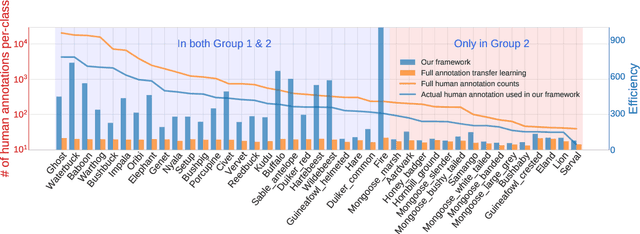
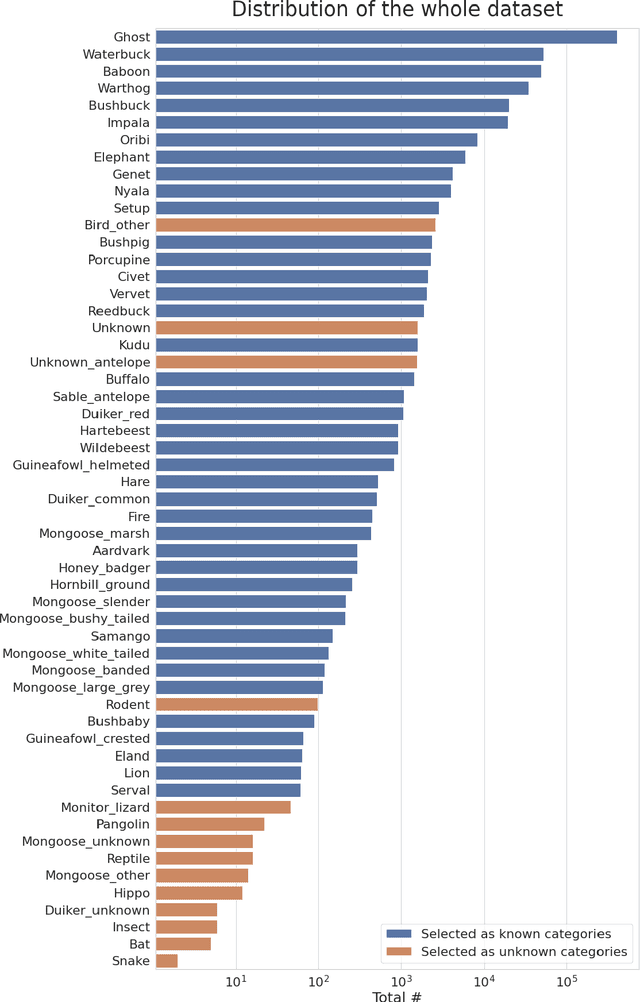
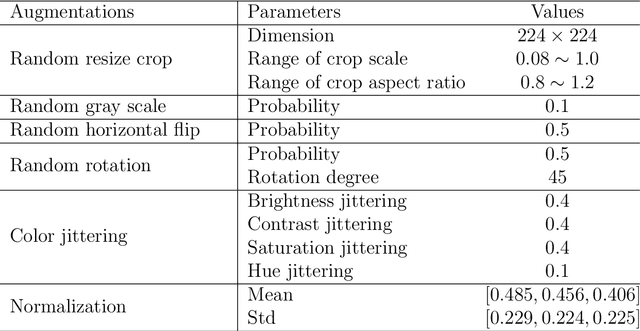
Camera trapping is increasingly used to monitor wildlife, but this technology typically requires extensive data annotation. Recently, deep learning has significantly advanced automatic wildlife recognition. However, current methods are hampered by a dependence on large static data sets when wildlife data is intrinsically dynamic and involves long-tailed distributions. These two drawbacks can be overcome through a hybrid combination of machine learning and humans in the loop. Our proposed iterative human and automated identification approach is capable of learning from wildlife imagery data with a long-tailed distribution. Additionally, it includes self-updating learning that facilitates capturing the community dynamics of rapidly changing natural systems. Extensive experiments show that our approach can achieve a ~90% accuracy employing only ~20% of the human annotations of existing approaches. Our synergistic collaboration of humans and machines transforms deep learning from a relatively inefficient post-annotation tool to a collaborative on-going annotation tool that vastly relieves the burden of human annotation and enables efficient and constant model updates.
Long-tailed Recognition by Routing Diverse Distribution-Aware Experts
Oct 05, 2020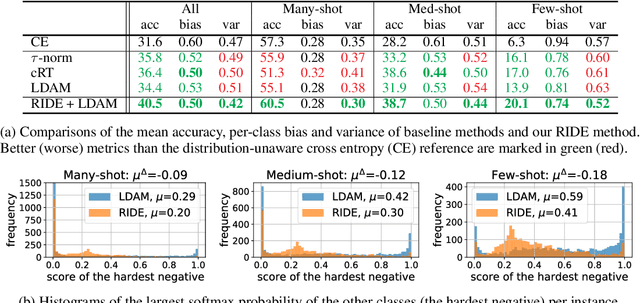
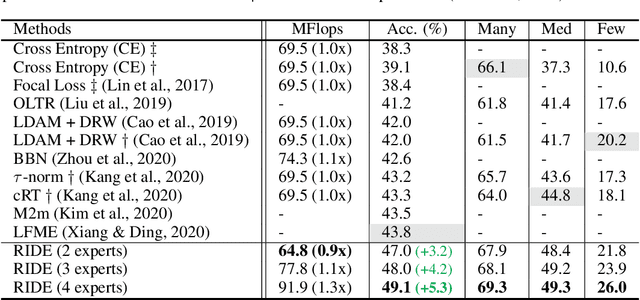
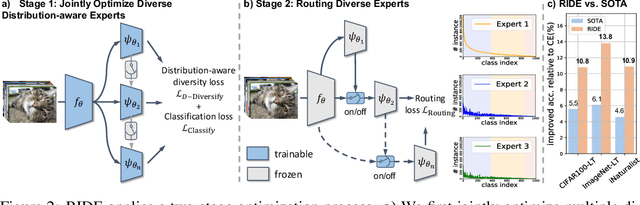
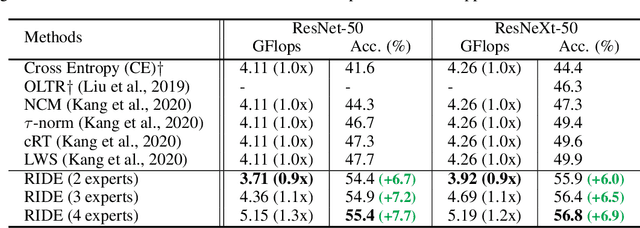
Natural data are often long-tail distributed over semantic classes. Existing recognition methods tend to focus on tail performance gain, often at the expense of head performance loss from increased classifier variance. The low tail performance manifests itself in large inter-class confusion and high classifier variance. We aim to reduce both the bias and the variance of a long-tailed classifier by RoutIng Diverse Experts (RIDE). It has three components: 1) a shared architecture for multiple classifiers (experts); 2) a distribution-aware diversity loss that encourages more diverse decisions for classes with fewer training instances; and 3) an expert routing module that dynamically assigns more ambiguous instances to additional experts. With on-par computational complexity, RIDE significantly outperforms the state-of-the-art methods by 5% to 7% on all the benchmarks including CIFAR100-LT, ImageNet-LT and iNaturalist. RIDE is also a universal framework that can be applied to different backbone networks and integrated into various long-tailed algorithms and training mechanisms for consistent performance gains.
Compound Domain Adaptation in an Open World
Sep 08, 2019
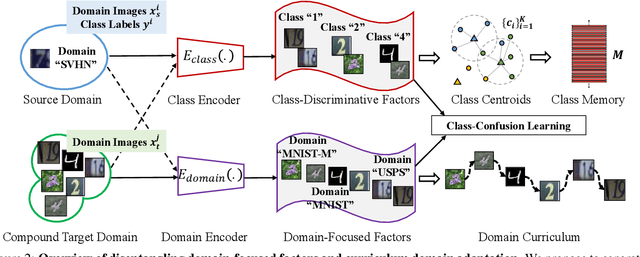

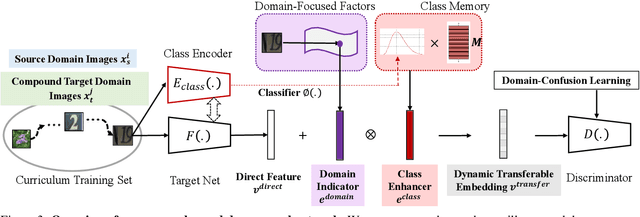
Existing works on domain adaptation often assume clear boundaries between source and target domains. Despite giving rise to a clean problem formalization, such form falls short of simulating the real world where domains are compounded of interleaving and confounding factors, blurring the domain boundaries. In this work, we opt for a different problem, dubbed open compound domain adaptation (OCDA), for studying the techniques of training domain-robust models in a more realistic setting. OCDA considers a compound (unlabeled) target domain which mixes several major factors (e.g., backgrounds, lighting conditions, etc.), along with a labeled training set, in the training stage and new open domains during inference. The compound target domain can be seen as a combination of multiple traditional target domains each with its own idiosyncrasy. To tackle OCDA, we propose a class-confusion loss to disentangle the domain-dominant factors out of the data and then use them to schedule a curriculum domain adaptation strategy. Moreover, we use a memory-augmented neural network architecture to increase the network's capacity for handling previously unseen domains. Extensive experiments on digit classification, facial expression recognition, semantic segmentation, and reinforcement learning verify the effectiveness of our approach.
Large-Scale Long-Tailed Recognition in an Open World
Apr 16, 2019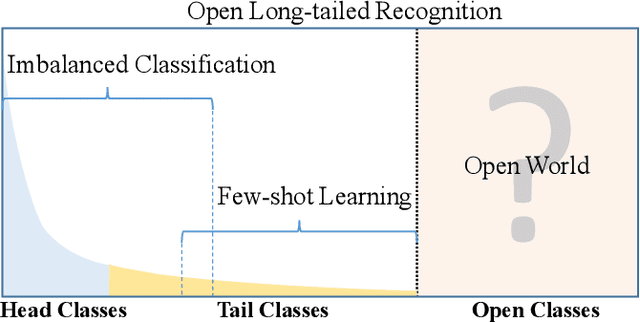

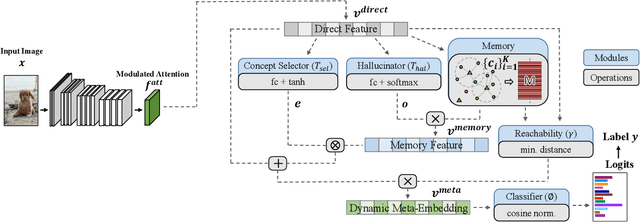
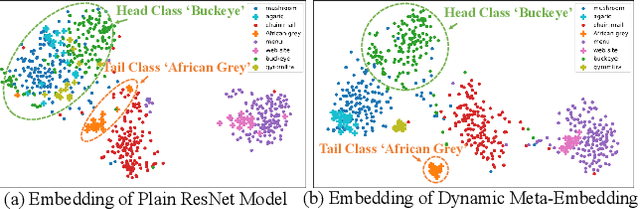
Real world data often have a long-tailed and open-ended distribution. A practical recognition system must classify among majority and minority classes, generalize from a few known instances, and acknowledge novelty upon a never seen instance. We define Open Long-Tailed Recognition (OLTR) as learning from such naturally distributed data and optimizing the classification accuracy over a balanced test set which include head, tail, and open classes. OLTR must handle imbalanced classification, few-shot learning, and open-set recognition in one integrated algorithm, whereas existing classification approaches focus only on one aspect and deliver poorly over the entire class spectrum. The key challenges are how to share visual knowledge between head and tail classes and how to reduce confusion between tail and open classes. We develop an integrated OLTR algorithm that maps an image to a feature space such that visual concepts can easily relate to each other based on a learned metric that respects the closed-world classification while acknowledging the novelty of the open world. Our so-called dynamic meta-embedding combines a direct image feature and an associated memory feature, with the feature norm indicating the familiarity to known classes. On three large-scale OLTR datasets we curate from object-centric ImageNet, scene-centric Places, and face-centric MS1M data, our method consistently outperforms the state-of-the-art. Our code, datasets, and models enable future OLTR research and are publicly available at https://liuziwei7.github.io/projects/LongTail.html.