 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive Transfer Learning for Person Re-identification
Aug 08, 2019
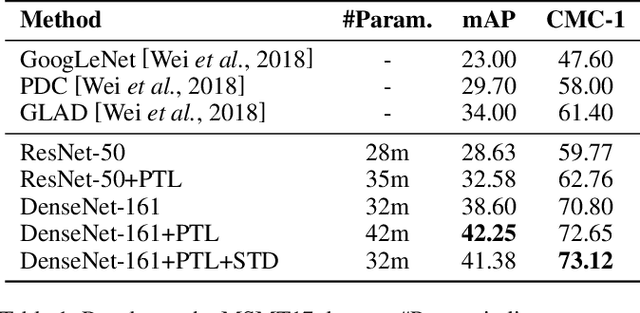
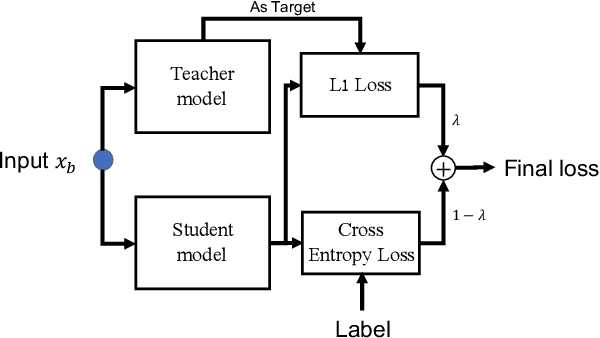
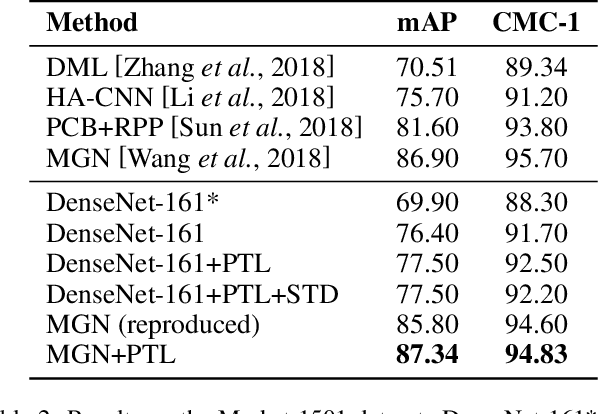
Model fine-tuning is a widely used transfer learning approach in person Re-identification (ReID) applications, which fine-tuning a pre-trained feature extraction model into the target scenario instead of training a model from scratch. It is challenging due to the significant variations inside the target scenario, e.g., different camera viewpoint, illumination changes, and occlusion. These variations result in a gap between the distribution of each mini-batch and the distribution of the whole dataset when using mini-batch training. In this paper, we study model fine-tuning from the perspective of the aggregation and utilization of the global information of the dataset when using mini-batch training. Specifically, we introduce a novel network structure called Batch-related Convolutional Cell (BConv-Cell), which progressively collects the global information of the dataset into a latent state and uses this latent state to rectify the extracted feature. Based on BConv-Cells, we further proposed the Progressive Transfer Learning (PTL) method to facilitate the model fine-tuning process by joint training the BConv-Cells and the pre-trained ReID model. Empirical experiments show that our proposal can improve the performance of the ReID model greatly on MSMT17, Market-1501, CUHK03 and DukeMTMC-reID datasets. The code will be released later on at \url{https://github.com/ZJULearning/PTL}
Deep Active Learning for Video-based Person Re-identification
Dec 14, 2018
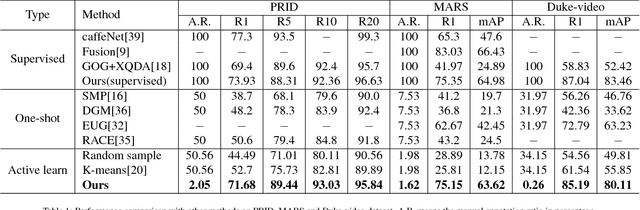
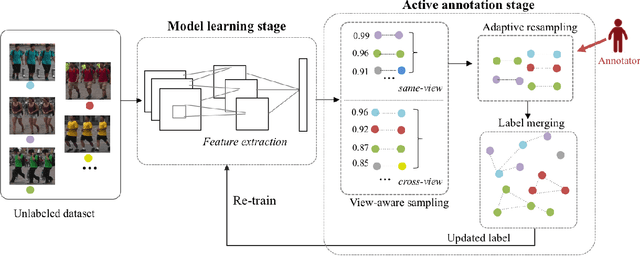

It is prohibitively expensive to annotate a large-scale video-based person re-identification (re-ID) dataset, which makes fully supervised methods inapplicable to real-world deployment. How to maximally reduce the annotation cost while retaining the re-ID performance becomes an interesting problem. In this paper, we address this problem by integrating an active learning scheme into a deep learning framework. Noticing that the truly matched tracklet-pairs, also denoted as true positives (TP), are the most informative samples for our re-ID model, we propose a sampling criterion to choose the most TP-likely tracklet-pairs for annotation. A view-aware sampling strategy considering view-specific biases is designed to facilitate candidate selection, followed by an adaptive resampling step to leave out the selected candidates that are unnecessary to annotate. Our method learns the re-ID model and updates the annotation set iteratively. The re-ID model is supervised by the tracklets' pesudo labels that are initialized by treating each tracklet as a distinct class. With the gained annotations of the actively selected candidates, the tracklets' pesudo labels are updated by label merging and further used to re-train our re-ID model. While being simple, the proposed method demonstrates its effectiveness on three video-based person re-ID datasets. Experimental results show that less than 3\% pairwise annotations are needed for our method to reach comparable performance with the fully-supervised setting.
Dynamic Spatio-temporal Graph-based CNNs for Traffic Prediction
Dec 06, 2018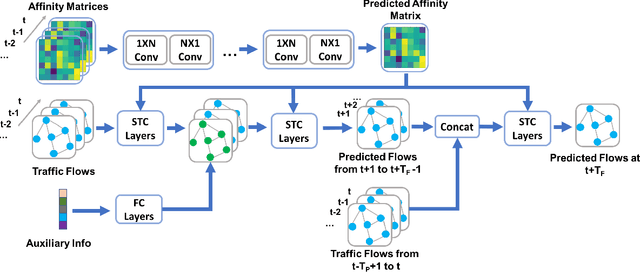
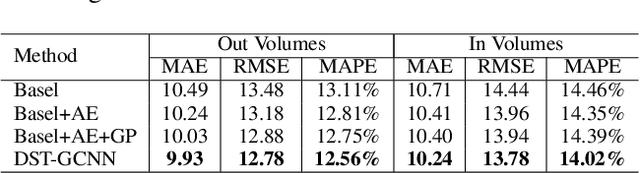
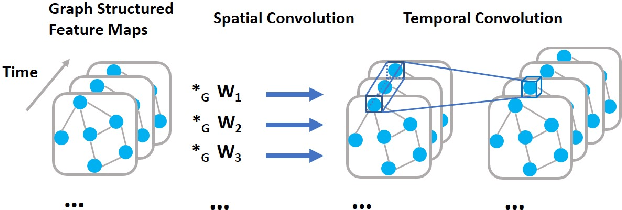
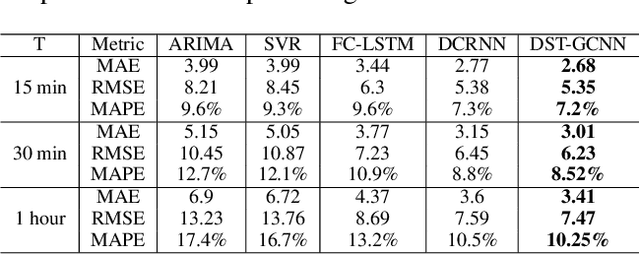
Accurate traffic forecast is a challenging problem due to the large-scale problem size, as well as the complex and dynamic nature of spatio-temporal dependency of traffic flow. Most existing graph-based CNNs attempt to capture the static relations while largely neglecting the dynamics underlying sequential data. In this paper, we present dynamic spatio-temporal graph-based CNNs (DST-GCNNs) by learning expressive features to represent spatio-temporal structures and predict future traffic from historical traffic flow. In particular, DST-GCNN is a two stream network. In the flow prediction stream, we present a novel graph-based spatio-temporal convolutional layer to extract features from a graph representation of traffic flow. Then several such layers are stacked together to predict future traffic over time. Meanwhile, the proximity relations between nodes in the graph are often time variant as the traffic condition changes over time. To capture the graph dynamics, we use the graph prediction stream to predict the dynamic graph structures, and the predicted structures are fed into the flow prediction stream. Experiments on real traffic datasets demonstrate that the proposed model achieves competitive performances compared with the other state-of-the-art methods.
Sharp Attention Network via Adaptive Sampling for Person Re-identification
Sep 26, 2018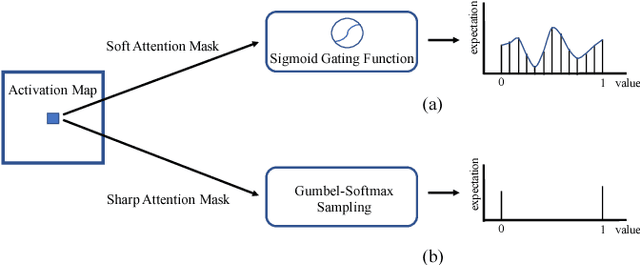
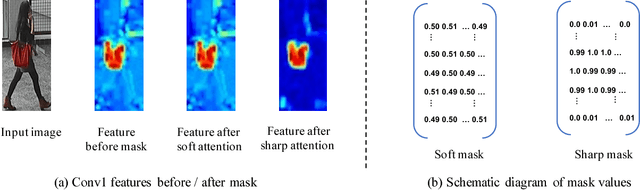
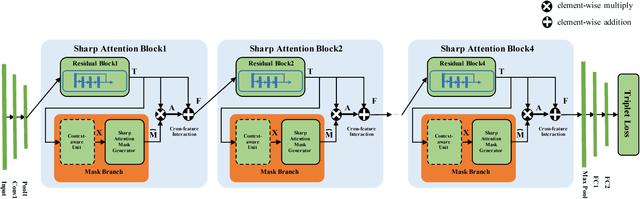
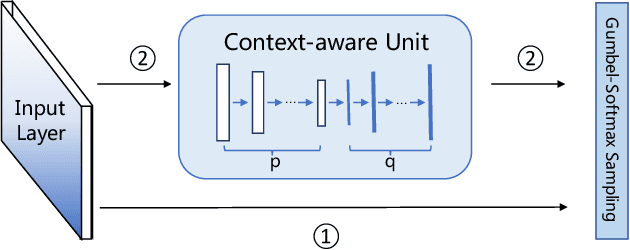
In this paper, we present novel sharp attention networks by adaptively sampling feature maps from convolutional neural networks (CNNs) for person re-identification (re-ID) problem. Due to the introduction of sampling-based attention models, the proposed approach can adaptively generate sharper attention-aware feature masks. This greatly differs from the gating-based attention mechanism that relies soft gating functions to select the relevant features for person re-ID. In contrast, the proposed sampling-based attention mechanism allows us to effectively trim irrelevant features by enforcing the resultant feature masks to focus on the most discriminative features. It can produce sharper attentions that are more assertive in localizing subtle features relevant to re-identifying people across cameras. For this purpose, a differentiable Gumbel-Softmax sampler is employed to approximate the Bernoulli sampling to train the sharp attention networks. Extensive experimental evaluations demonstrate the superiority of this new sharp attention model for person re-ID over the other state-of-the-art methods on three challenging benchmarks including CUHK03, Market-1501, and DukeMTMC-reID.