 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisible Light Positioning With Lamé Curve LEDs: A Generic Approach for Camera Pose Estimation
Feb 02, 2026Camera-based visible light positioning (VLP) is a promising technique for accurate and low-cost indoor camera pose estimation (CPE). To reduce the number of required light-emitting diodes (LEDs), advanced methods commonly exploit LED shape features for positioning. Although interesting, they are typically restricted to a single LED geometry, leading to failure in heterogeneous LED-shape scenarios. To address this challenge, this paper investigates Lamé curves as a unified representation of common LED shapes and proposes a generic VLP algorithm using Lamé curve-shaped LEDs, termed LC-VLP. In the considered system, multiple ceiling-mounted Lamé curve-shaped LEDs periodically broadcast their curve parameters via visible light communication, which are captured by a camera-equipped receiver. Based on the received LED images and curve parameters, the receiver can estimate the camera pose using LC-VLP. Specifically, an LED database is constructed offline to store the curve parameters, while online positioning is formulated as a nonlinear least-squares problem and solved iteratively. To provide a reliable initialization, a correspondence-free perspective-\textit{n}-points (FreeP\textit{n}P) algorithm is further developed, enabling approximate CPE without any pre-calibrated reference points. The performance of LC-VLP is verified by both simulations and experiments. Simulations show that LC-VLP outperforms state-of-the-art methods in both circular- and rectangular-LED scenarios, achieving reductions of over 40% in position error and 25% in rotation error. Experiments further show that LC-VLP can achieve an average position accuracy of less than 4 cm.
Optimal Look-back Horizon for Time Series Forecasting in Federated Learning
Nov 18, 2025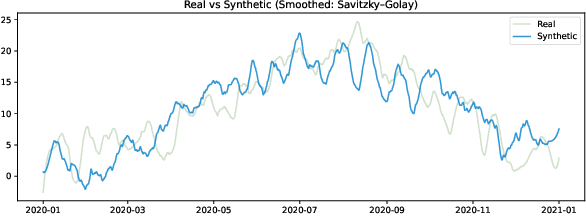
Selecting an appropriate look-back horizon remains a fundamental challenge in time series forecasting (TSF), particularly in the federated learning scenarios where data is decentralized, heterogeneous, and often non-independent. While recent work has explored horizon selection by preserving forecasting-relevant information in an intrinsic space, these approaches are primarily restricted to centralized and independently distributed settings. This paper presents a principled framework for adaptive horizon selection in federated time series forecasting through an intrinsic space formulation. We introduce a synthetic data generator (SDG) that captures essential temporal structures in client data, including autoregressive dependencies, seasonality, and trend, while incorporating client-specific heterogeneity. Building on this model, we define a transformation that maps time series windows into an intrinsic representation space with well-defined geometric and statistical properties. We then derive a decomposition of the forecasting loss into a Bayesian term, which reflects irreducible uncertainty, and an approximation term, which accounts for finite-sample effects and limited model capacity. Our analysis shows that while increasing the look-back horizon improves the identifiability of deterministic patterns, it also increases approximation error due to higher model complexity and reduced sample efficiency. We prove that the total forecasting loss is minimized at the smallest horizon where the irreducible loss starts to saturate, while the approximation loss continues to rise. This work provides a rigorous theoretical foundation for adaptive horizon selection for time series forecasting in federated learning.
Optimizing Multi-Modal Trackers via Sensitivity-aware Regularized Tuning
Aug 24, 2025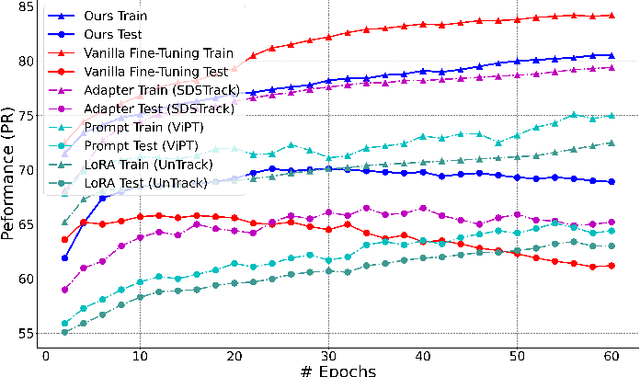

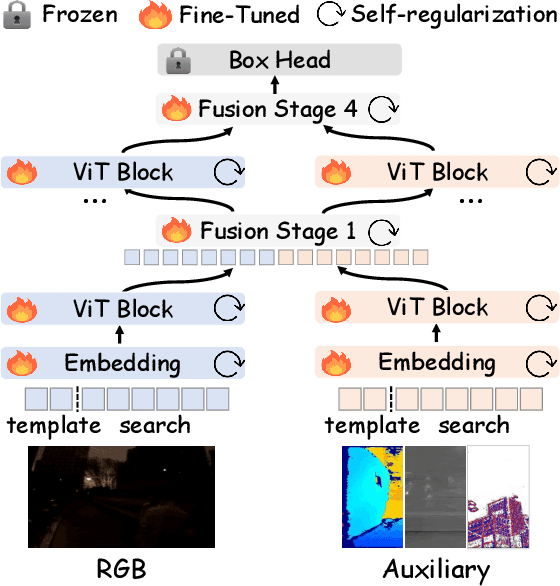
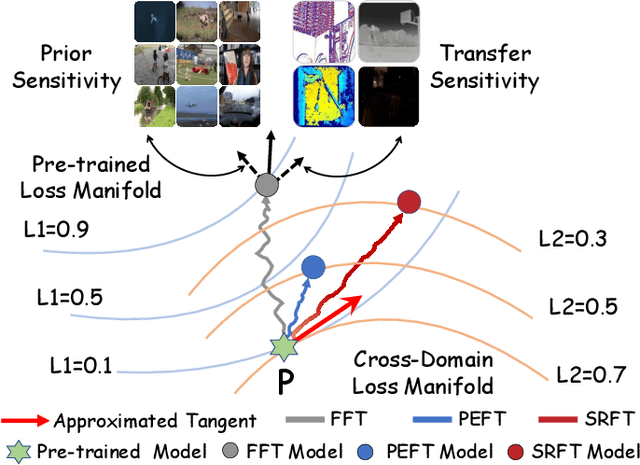
This paper tackles the critical challenge of optimizing multi-modal trackers by effectively adapting the pre-trained models for RGB data. Existing fine-tuning paradigms oscillate between excessive freedom and over-restriction, both leading to a suboptimal plasticity-stability trade-off. To mitigate this dilemma, we propose a novel sensitivity-aware regularized tuning framework, which delicately refines the learning process by incorporating intrinsic parameter sensitivities. Through a comprehensive investigation from pre-trained to multi-modal contexts, we identify that parameters sensitive to pivotal foundational patterns and cross-domain shifts are primary drivers of this issue. Specifically, we first analyze the tangent space of pre-trained weights to measure and orient prior sensitivities, dedicated to preserving generalization. Then, we further explore transfer sensitivities during the tuning phase, emphasizing adaptability and stability. By incorporating these sensitivities as regularization terms, our method significantly enhances the transferability across modalities. Extensive experiments showcase the superior performance of the proposed method, surpassing current state-of-the-art techniques across various multi-modal tracking. The source code and models will be publicly available at https://github.com/zhiwen-xdu/SRTrack.
ABE: A Unified Framework for Robust and Faithful Attribution-Based Explainability
May 03, 2025Attribution algorithms are essential for enhancing the interpretability and trustworthiness of deep learning models by identifying key features driving model decisions. Existing frameworks, such as InterpretDL and OmniXAI, integrate multiple attribution methods but suffer from scalability limitations, high coupling, theoretical constraints, and lack of user-friendly implementations, hindering neural network transparency and interoperability. To address these challenges, we propose Attribution-Based Explainability (ABE), a unified framework that formalizes Fundamental Attribution Methods and integrates state-of-the-art attribution algorithms while ensuring compliance with attribution axioms. ABE enables researchers to develop novel attribution techniques and enhances interpretability through four customizable modules: Robustness, Interpretability, Validation, and Data & Model. This framework provides a scalable, extensible foundation for advancing attribution-based explainability and fostering transparent AI systems. Our code is available at: https://github.com/LMBTough/ABE-XAI.
Acc3D: Accelerating Single Image to 3D Diffusion Models via Edge Consistency Guided Score Distillation
Mar 20, 2025



We present Acc3D to tackle the challenge of accelerating the diffusion process to generate 3D models from single images. To derive high-quality reconstructions through few-step inferences, we emphasize the critical issue of regularizing the learning of score function in states of random noise. To this end, we propose edge consistency, i.e., consistent predictions across the high signal-to-noise ratio region, to enhance a pre-trained diffusion model, enabling a distillation-based refinement of the endpoint score function. Building on those distilled diffusion models, we propose an adversarial augmentation strategy to further enrich the generation detail and boost overall generation quality. The two modules complement each other, mutually reinforcing to elevate generative performance. Extensive experiments demonstrate that our Acc3D not only achieves over a $20\times$ increase in computational efficiency but also yields notable quality improvements, compared to the state-of-the-arts.
Attribution for Enhanced Explanation with Transferable Adversarial eXploration
Dec 27, 2024



The interpretability of deep neural networks is crucial for understanding model decisions in various applications, including computer vision. AttEXplore++, an advanced framework built upon AttEXplore, enhances attribution by incorporating transferable adversarial attack methods such as MIG and GRA, significantly improving the accuracy and robustness of model explanations. We conduct extensive experiments on five models, including CNNs (Inception-v3, ResNet-50, VGG16) and vision transformers (MaxViT-T, ViT-B/16), using the ImageNet dataset. Our method achieves an average performance improvement of 7.57\% over AttEXplore and 32.62\% compared to other state-of-the-art interpretability algorithms. Using insertion and deletion scores as evaluation metrics, we show that adversarial transferability plays a vital role in enhancing attribution results. Furthermore, we explore the impact of randomness, perturbation rate, noise amplitude, and diversity probability on attribution performance, demonstrating that AttEXplore++ provides more stable and reliable explanations across various models. We release our code at: https://anonymous.4open.science/r/ATTEXPLOREP-8435/
ResFlow: Fine-tuning Residual Optical Flow for Event-based High Temporal Resolution Motion Estimation
Dec 12, 2024



Event cameras hold significant promise for high-temporal-resolution (HTR) motion estimation. However, estimating event-based HTR optical flow faces two key challenges: the absence of HTR ground-truth data and the intrinsic sparsity of event data. Most existing approaches rely on the flow accumulation paradigms to indirectly supervise intermediate flows, often resulting in accumulation errors and optimization difficulties. To address these challenges, we propose a residual-based paradigm for estimating HTR optical flow with event data. Our approach separates HTR flow estimation into two stages: global linear motion estimation and HTR residual flow refinement. The residual paradigm effectively mitigates the impacts of event sparsity on optimization and is compatible with any LTR algorithm. Next, to address the challenge posed by the absence of HTR ground truth, we incorporate novel learning strategies. Specifically, we initially employ a shared refiner to estimate the residual flows, enabling both LTR supervision and HTR inference. Subsequently, we introduce regional noise to simulate the residual patterns of intermediate flows, facilitating the adaptation from LTR supervision to HTR inference. Additionally, we show that the noise-based strategy supports in-domain self-supervised training. Comprehensive experimental results demonstrate that our approach achieves state-of-the-art accuracy in both LTR and HTR metrics, highlighting its effectiveness and superiority.
AI-Compass: A Comprehensive and Effective Multi-module Testing Tool for AI Systems
Nov 09, 2024



AI systems, in particular with deep learning techniques, have demonstrated superior performance for various real-world applications. Given the need for tailored optimization in specific scenarios, as well as the concerns related to the exploits of subsurface vulnerabilities, a more comprehensive and in-depth testing AI system becomes a pivotal topic. We have seen the emergence of testing tools in real-world applications that aim to expand testing capabilities. However, they often concentrate on ad-hoc tasks, rendering them unsuitable for simultaneously testing multiple aspects or components. Furthermore, trustworthiness issues arising from adversarial attacks and the challenge of interpreting deep learning models pose new challenges for developing more comprehensive and in-depth AI system testing tools. In this study, we design and implement a testing tool, \tool, to comprehensively and effectively evaluate AI systems. The tool extensively assesses multiple measurements towards adversarial robustness, model interpretability, and performs neuron analysis. The feasibility of the proposed testing tool is thoroughly validated across various modalities, including image classification, object detection, and text classification. Extensive experiments demonstrate that \tool is the state-of-the-art tool for a comprehensive assessment of the robustness and trustworthiness of AI systems. Our research sheds light on a general solution for AI systems testing landscape.
PrefPaint: Aligning Image Inpainting Diffusion Model with Human Preference
Oct 29, 2024



In this paper, we make the first attempt to align diffusion models for image inpainting with human aesthetic standards via a reinforcement learning framework, significantly improving the quality and visual appeal of inpainted images. Specifically, instead of directly measuring the divergence with paired images, we train a reward model with the dataset we construct, consisting of nearly 51,000 images annotated with human preferences. Then, we adopt a reinforcement learning process to fine-tune the distribution of a pre-trained diffusion model for image inpainting in the direction of higher reward. Moreover, we theoretically deduce the upper bound on the error of the reward model, which illustrates the potential confidence of reward estimation throughout the reinforcement alignment process, thereby facilitating accurate regularization. Extensive experiments on inpainting comparison and downstream tasks, such as image extension and 3D reconstruction, demonstrate the effectiveness of our approach, showing significant improvements in the alignment of inpainted images with human preference compared with state-of-the-art methods. This research not only advances the field of image inpainting but also provides a framework for incorporating human preference into the iterative refinement of generative models based on modeling reward accuracy, with broad implications for the design of visually driven AI applications. Our code and dataset are publicly available at https://prefpaint.github.io.
E-Motion: Future Motion Simulation via Event Sequence Diffusion
Oct 11, 2024Forecasting a typical object's future motion is a critical task for interpreting and interacting with dynamic environments in computer vision. Event-based sensors, which could capture changes in the scene with exceptional temporal granularity, may potentially offer a unique opportunity to predict future motion with a level of detail and precision previously unachievable. Inspired by that, we propose to integrate the strong learning capacity of the video diffusion model with the rich motion information of an event camera as a motion simulation framework. Specifically, we initially employ pre-trained stable video diffusion models to adapt the event sequence dataset. This process facilitates the transfer of extensive knowledge from RGB videos to an event-centric domain. Moreover, we introduce an alignment mechanism that utilizes reinforcement learning techniques to enhance the reverse generation trajectory of the diffusion model, ensuring improved performance and accuracy. Through extensive testing and validation, we demonstrate the effectiveness of our method in various complex scenarios, showcasing its potential to revolutionize motion flow prediction in computer vision applications such as autonomous vehicle guidance, robotic navigation, and interactive media. Our findings suggest a promising direction for future research in enhancing the interpretative power and predictive accuracy of computer vision systems.