 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreeCUA: Efficiently Scaling GUI Automation with Tree-Structured Verifiable Evolution
Feb 10, 2026Effectively scaling GUI automation is essential for computer-use agents (CUAs); however, existing work primarily focuses on scaling GUI grounding rather than the more crucial GUI planning, which requires more sophisticated data collection. In reality, the exploration process of a CUA across apps/desktops/web pages typically follows a tree structure, with earlier functional entry points often being explored more frequently. Thus, organizing large-scale trajectories into tree structures can reduce data cost and streamline the data scaling of GUI planning. In this work, we propose TreeCUA to efficiently scale GUI automation with tree-structured verifiable evolution. We propose a multi-agent collaborative framework to explore the environment, verify actions, summarize trajectories, and evaluate quality to generate high-quality and scalable GUI trajectories. To improve efficiency, we devise a novel tree-based topology to store and replay duplicate exploration nodes, and design an adaptive exploration algorithm to balance the depth (\emph{i.e.}, trajectory difficulty) and breadth (\emph{i.e.}, trajectory diversity). Moreover, we develop world knowledge guidance and global memory backtracking to avoid low-quality generation. Finally, we naturally extend and propose the TreeCUA-DPO method from abundant tree node information, improving GUI planning capability by referring to the branch information of adjacent trajectories. Experimental results show that TreeCUA and TreeCUA-DPO offer significant improvements, and out-of-domain (OOD) studies further demonstrate strong generalization. All trajectory node information and code will be available at https://github.com/UITron-hub/TreeCUA.
Flexible Entropy Control in RLVR with Gradient-Preserving Perspective
Feb 10, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a critical method for enhancing the reasoning capabilities of Large Language Models (LLMs). However, continuous training often leads to policy entropy collapse, characterized by a rapid decay in entropy that results in premature overconfidence, reduced output diversity, and vanishing gradient norms that inhibit learning. Gradient-Preserving Clipping is a primary factor influencing these dynamics, but existing mitigation strategies are largely static and lack a framework connecting clipping mechanisms to precise entropy control. This paper proposes reshaping entropy control in RL from the perspective of Gradient-Preserving Clipping. We first theoretically and empirically verify the contributions of specific importance sampling ratio regions to entropy growth and reduction. Leveraging these findings, we introduce a novel regulation mechanism using dynamic clipping threshold to precisely manage entropy. Furthermore, we design and evaluate dynamic entropy control strategies, including increase-then-decrease, decrease-increase-decrease, and oscillatory decay. Experimental results demonstrate that these strategies effectively mitigate entropy collapse, and achieve superior performance across multiple benchmarks.
Length-Unbiased Sequence Policy Optimization: Revealing and Controlling Response Length Variation in RLVR
Feb 05, 2026Recent applications of Reinforcement Learning with Verifiable Rewards (RLVR) to Large Language Models (LLMs) and Vision-Language Models (VLMs) have demonstrated significant success in enhancing reasoning capabilities for complex tasks. During RLVR training, an increase in response length is often regarded as a key factor contributing to the growth of reasoning ability. However, the patterns of change in response length vary significantly across different RLVR algorithms during the training process. To provide a fundamental explanation for these variations, this paper conducts an in-depth analysis of the components of mainstream RLVR algorithms. We present a theoretical analysis of the factors influencing response length and validate our theory through extensive experimentation. Building upon these theoretical findings, we propose the Length-Unbiased Sequence Policy Optimization (LUSPO) algorithm. Specifically, we rectify the length bias inherent in Group Sequence Policy Optimization (GSPO), rendering its loss function unbiased with respect to response length and thereby resolving the issue of response length collapse. We conduct extensive experiments across mathematical reasoning benchmarks and multimodal reasoning scenarios, where LUSPO consistently achieves superior performance. Empirical results demonstrate that LUSPO represents a novel, state-of-the-art optimization strategy compared to existing methods such as GRPO and GSPO.
Agentic Reward Modeling: Verifying GUI Agent via Online Proactive Interaction
Jan 31, 2026Reinforcement learning with verifiable rewards (RLVR) is pivotal for the continuous evolution of GUI agents, yet existing evaluation paradigms face significant limitations. Rule-based methods suffer from poor scalability and cannot handle open-ended tasks, while LLM-as-a-Judge approaches rely on passive visual observation, often failing to capture latent system states due to partial state observability. To address these challenges, we advocate for a paradigm shift from passive evaluation to Agentic Interactive Verification. We introduce VAGEN, a framework that employs a verifier agent equipped with interaction tools to autonomously plan verification strategies and proactively probe the environment for evidence of task completion. Leveraging the insight that GUI tasks are typically "easy to verify but hard to solve", VAGEN overcomes the bottlenecks of visual limitations. Experimental results on OSWorld-Verified and AndroidWorld benchmarks demonstrate that VAGEN significantly improves evaluation accuracy compared to LLM-as-a-Judge baselines and further enhances performance through test-time scaling strategies.
OCRVerse: Towards Holistic OCR in End-to-End Vision-Language Models
Jan 29, 2026The development of large vision language models drives the demand for managing, and applying massive amounts of multimodal data, making OCR technology, which extracts information from visual images, increasingly popular. However, existing OCR methods primarily focus on recognizing text elements from images or scanned documents (\textbf{Text-centric OCR}), neglecting the identification of visual elements from visually information-dense image sources (\textbf{Vision-centric OCR}), such as charts, web pages and science plots. In reality, these visually information-dense images are widespread on the internet and have significant real-world application value, such as data visualization and web page analysis. In this technical report, we propose \textbf{OCRVerse}, the first holistic OCR method in end-to-end manner that enables unified text-centric OCR and vision-centric OCR. To this end, we constructe comprehensive data engineering to cover a wide range of text-centric documents, such as newspapers, magazines and books, as well as vision-centric rendered composites, including charts, web pages and scientific plots. Moreover, we propose a two-stage SFT-RL multi-domain training method for OCRVerse. SFT directly mixes cross-domain data to train and establish initial domain knowledge, while RL focuses on designing personalized reward strategies for the characteristics of each domain. Specifically, since different domains require various output formats and expected outputs, we provide sufficient flexibility in the RL stage to customize flexible reward signals for each domain, thereby improving cross-domain fusion and avoiding data conflicts. Experimental results demonstrate the effectiveness of OCRVerse, achieving competitive results across text-centric and vision-centric data types, even comparable to large-scale open-source and closed-source models.
MobileDreamer: Generative Sketch World Model for GUI Agent
Jan 07, 2026Mobile GUI agents have shown strong potential in real-world automation and practical applications. However, most existing agents remain reactive, making decisions mainly from current screen, which limits their performance on long-horizon tasks. Building a world model from repeated interactions enables forecasting action outcomes and supports better decision making for mobile GUI agents. This is challenging because the model must predict post-action states with spatial awareness while remaining efficient enough for practical deployment. In this paper, we propose MobileDreamer, an efficient world-model-based lookahead framework to equip the GUI agents based on the future imagination provided by the world model. It consists of textual sketch world model and rollout imagination for GUI agent. Textual sketch world model forecasts post-action states through a learning process to transform digital images into key task-related sketches, and designs a novel order-invariant learning strategy to preserve the spatial information of GUI elements. The rollout imagination strategy for GUI agent optimizes the action-selection process by leveraging the prediction capability of world model. Experiments on Android World show that MobileDreamer achieves state-of-the-art performance and improves task success by 5.25%. World model evaluations further verify that our textual sketch modeling accurately forecasts key GUI elements.
Learning When to Look: A Disentangled Curriculum for Strategic Perception in Multimodal Reasoning
Dec 19, 2025Multimodal Large Language Models (MLLMs) demonstrate significant potential but remain brittle in complex, long-chain visual reasoning tasks. A critical failure mode is "visual forgetting", where models progressively lose visual grounding as reasoning extends, a phenomenon aptly described as "think longer, see less". We posit this failure stems from current training paradigms prematurely entangling two distinct cognitive skills: (1) abstract logical reasoning "how-to-think") and (2) strategic visual perception ("when-to-look"). This creates a foundational cold-start deficiency -- weakening abstract reasoning -- and a strategic perception deficit, as models lack a policy for when to perceive. In this paper, we propose a novel curriculum-based framework to disentangle these skills. First, we introduce a disentangled Supervised Fine-Tuning (SFT) curriculum that builds a robust abstract reasoning backbone on text-only data before anchoring it to vision with a novel Perception-Grounded Chain-of-Thought (PG-CoT) paradigm. Second, we resolve the strategic perception deficit by formulating timing as a reinforcement learning problem. We design a Pivotal Perception Reward that teaches the model when to look by coupling perceptual actions to linguistic markers of cognitive uncertainty (e.g., "wait", "verify"), thereby learning an autonomous grounding policy. Our contributions include the formalization of these two deficiencies and the development of a principled, two-stage framework to address them, transforming the model from a heuristic-driven observer to a strategic, grounded reasoner. \textbf{Code}: \url{https://github.com/gaozilve-max/learning-when-to-look}.
UItron: Foundational GUI Agent with Advanced Perception and Planning
Aug 29, 2025GUI agent aims to enable automated operations on Mobile/PC devices, which is an important task toward achieving artificial general intelligence. The rapid advancement of VLMs accelerates the development of GUI agents, owing to their powerful capabilities in visual understanding and task planning. However, building a GUI agent remains a challenging task due to the scarcity of operation trajectories, the availability of interactive infrastructure, and the limitation of initial capabilities in foundation models. In this work, we introduce UItron, an open-source foundational model for automatic GUI agents, featuring advanced GUI perception, grounding, and planning capabilities. UItron highlights the necessity of systemic data engineering and interactive infrastructure as foundational components for advancing GUI agent development. It not only systematically studies a series of data engineering strategies to enhance training effects, but also establishes an interactive environment connecting both Mobile and PC devices. In training, UItron adopts supervised finetuning over perception and planning tasks in various GUI scenarios, and then develop a curriculum reinforcement learning framework to enable complex reasoning and exploration for online environments. As a result, UItron achieves superior performance in benchmarks of GUI perception, grounding, and planning. In particular, UItron highlights the interaction proficiency with top-tier Chinese mobile APPs, as we identified a general lack of Chinese capabilities even in state-of-the-art solutions. To this end, we manually collect over one million steps of operation trajectories across the top 100 most popular apps, and build the offline and online agent evaluation environments. Experimental results demonstrate that UItron achieves significant progress in Chinese app scenarios, propelling GUI agents one step closer to real-world application.
DocTron-Formula: Generalized Formula Recognition in Complex and Structured Scenarios
Aug 01, 2025

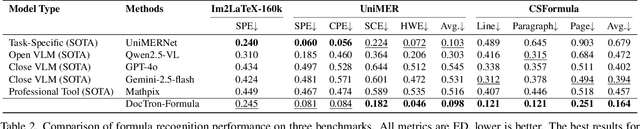
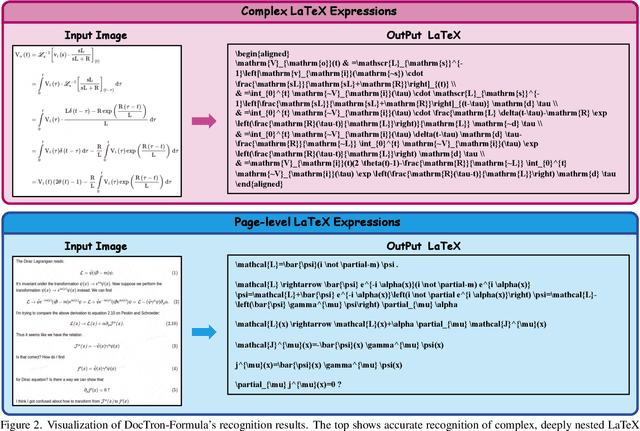
Optical Character Recognition (OCR) for mathematical formula is essential for the intelligent analysis of scientific literature. However, both task-specific and general vision-language models often struggle to handle the structural diversity, complexity, and real-world variability inherent in mathematical content. In this work, we present DocTron-Formula, a unified framework built upon general vision-language models, thereby eliminating the need for specialized architectures. Furthermore, we introduce CSFormula, a large-scale and challenging dataset that encompasses multidisciplinary and structurally complex formulas at the line, paragraph, and page levels. Through straightforward supervised fine-tuning, our approach achieves state-of-the-art performance across a variety of styles, scientific domains, and complex layouts. Experimental results demonstrate that our method not only surpasses specialized models in terms of accuracy and robustness, but also establishes a new paradigm for the automated understanding of complex scientific documents.
ScaleTrack: Scaling and back-tracking Automated GUI Agents
May 01, 2025Automated GUI agents aims to facilitate user interaction by automatically performing complex tasks in digital environments, such as web, mobile, desktop devices. It receives textual task instruction and GUI description to generate executable actions (\emph{e.g.}, click) and operation boxes step by step. Training a GUI agent mainly involves grounding and planning stages, in which the GUI grounding focuses on finding the execution coordinates according to the task, while the planning stage aims to predict the next action based on historical actions. However, previous work suffers from the limitations of insufficient training data for GUI grounding, as well as the ignorance of backtracking historical behaviors for GUI planning. To handle the above challenges, we propose ScaleTrack, a training framework by scaling grounding and backtracking planning for automated GUI agents. We carefully collected GUI samples of different synthesis criterions from a wide range of sources, and unified them into the same template for training GUI grounding models. Moreover, we design a novel training strategy that predicts the next action from the current GUI image, while also backtracking the historical actions that led to the GUI image. In this way, ScaleTrack explains the correspondence between GUI images and actions, which effectively describes the evolution rules of the GUI environment. Extensive experimental results demonstrate the effectiveness of ScaleTrack. Data and code will be available at url.