 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLipschitz Generative Adversarial Nets
Mar 14, 2019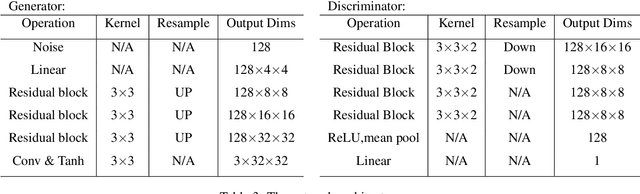
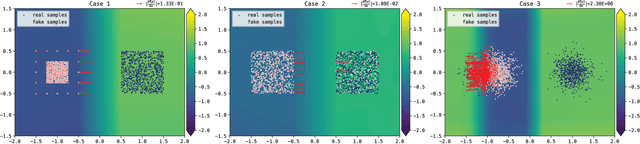
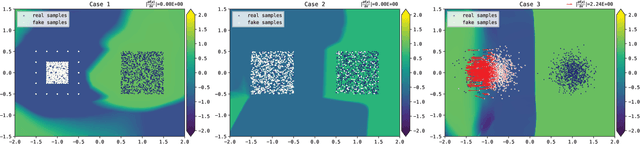
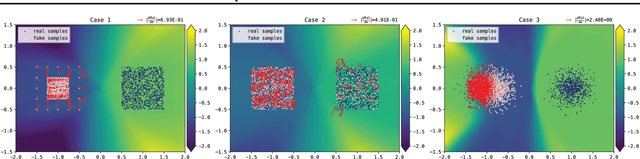
In this paper, we study the convergence of generative adversarial networks (GANs) from the perspective of the informativeness of the gradient of the optimal discriminative function. We show that GANs without restriction on the discriminative function space commonly suffer from the problem that the gradient produced by the discriminator is uninformative to guide the generator. By contrast, Wasserstein GAN (WGAN), where the discriminative function is restricted to $1$-Lipschitz, does not suffer from such a gradient uninformativeness problem. We further show in the paper that the model with a compact dual form of Wasserstein distance, where the Lipschitz condition is relaxed, may also suffer from this issue. This implies the importance of Lipschitz condition and motivates us to study the general formulation of GANs with Lipschitz constraint, which leads to a new family of GANs that we call Lipschitz GANs (LGANs). We show that LGANs guarantee the existence and uniqueness of the optimal discriminative function as well as the existence of a unique Nash equilibrium. We prove that LGANs are generally capable of eliminating the gradient uninformativeness problem. According to our empirical analysis, LGANs are more stable and generate consistently higher quality samples compared with WGAN.
Guiding the One-to-one Mapping in CycleGAN via Optimal Transport
Nov 15, 2018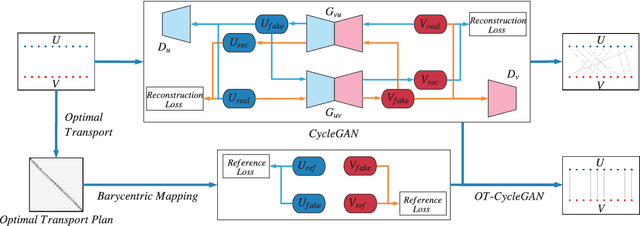
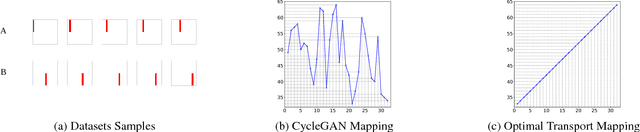

CycleGAN is capable of learning a one-to-one mapping between two data distributions without paired examples, achieving the task of unsupervised data translation. However, there is no theoretical guarantee on the property of the learned one-to-one mapping in CycleGAN. In this paper, we experimentally find that, under some circumstances, the one-to-one mapping learned by CycleGAN is just a random one within the large feasible solution space. Based on this observation, we explore to add extra constraints such that the one-to-one mapping is controllable and satisfies more properties related to specific tasks. We propose to solve an optimal transport mapping restrained by a task-specific cost function that reflects the desired properties, and use the barycenters of optimal transport mapping to serve as references for CycleGAN. Our experiments indicate that the proposed algorithm is capable of learning a one-to-one mapping with the desired properties.
Understanding the Effectiveness of Lipschitz-Continuity in Generative Adversarial Nets
Oct 05, 2018
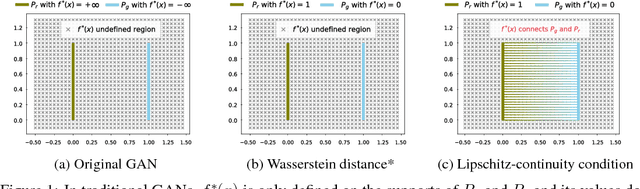
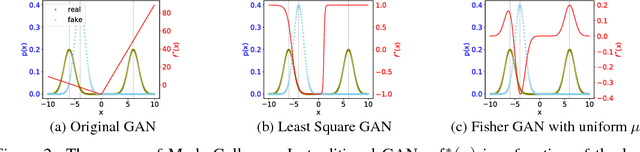
In this paper, we investigate the underlying factor that leads to the failure and success in training of GANs. Specifically, we study the property of the optimal discriminative function $f^*(x)$ and show that $f^*(x)$ in most GANs can only reflect the local densities at $x$, which means the value of $f^*(x)$ for points in the fake distribution ($P_g$) does not contain any information useful about the location of other points in the real distribution ($P_r$). Given that the supports of the real and fake distributions are usually disjoint, we argue that such a $f^*(x)$ and its gradient tell nothing about "how to pull $P_g$ to $P_r$", which turns out to be the fundamental cause of failure in training of GANs. We further demonstrate that a well-defined distance metric (including Wasserstein distance) does not necessarily ensure the convergence of GANs. Finally, we propose Lipschitz-continuity condition as a general solution and show that in a large family of GAN objectives, Lipschitz condition is capable of connecting $P_g$ and $P_r$ through $f^*(x)$ such that the gradient $\nabla_{\!x} f^*(x)$ at each sample $x \sim P_g$ points towards some real sample $y \sim P_r$.
AdaShift: Decorrelation and Convergence of Adaptive Learning Rate Methods
Oct 05, 2018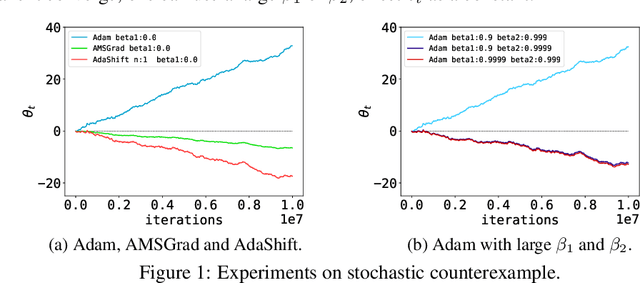

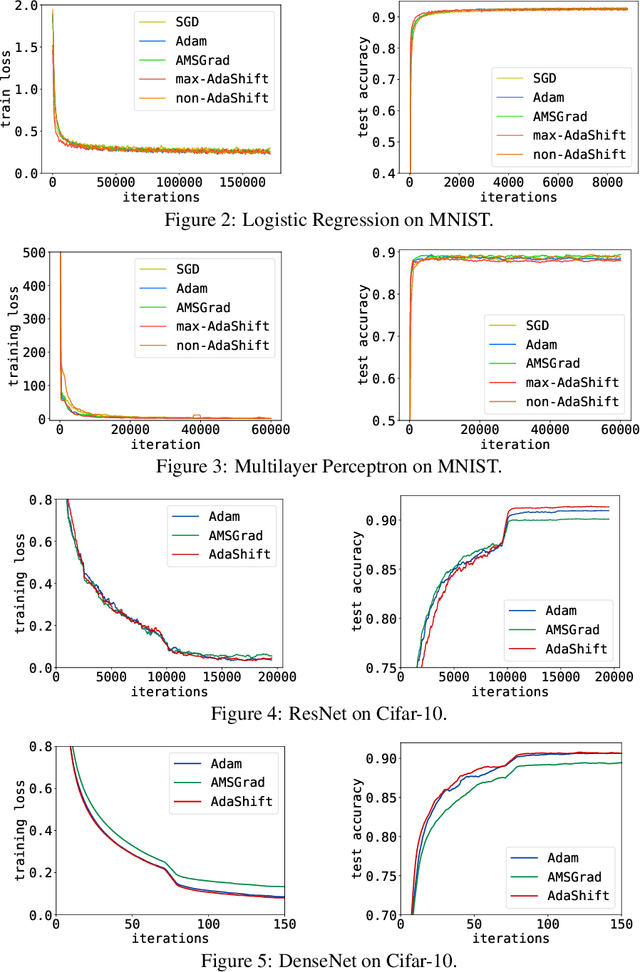
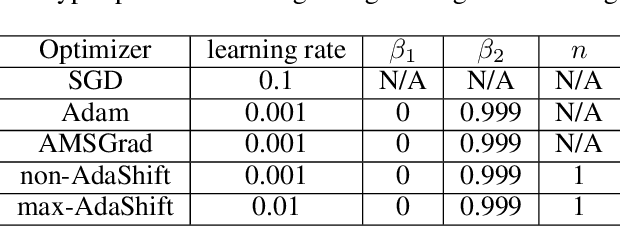
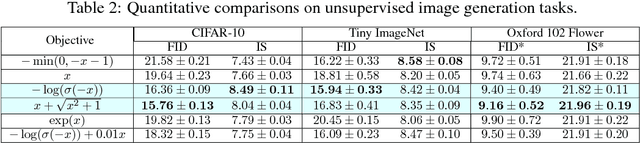
Adam is shown not being able to converge to the optimal solution in certain cases. Researchers recently propose several algorithms to avoid the issue of non-convergence of Adam, but their efficiency turns out to be unsatisfactory in practice. In this paper, we provide a new insight into the non-convergence issue of Adam as well as other adaptive learning rate methods. We argue that there exists an inappropriate correlation between gradient $g_t$ and the second moment term $v_t$ in Adam ($t$ is the timestep), which results in that a large gradient is likely to have small step size while a small gradient may have a large step size. We demonstrate that such unbalanced step sizes are the fundamental cause of non-convergence of Adam, and we further prove that decorrelating $v_t$ and $g_t$ will lead to unbiased step size for each gradient, thus solving the non-convergence problem of Adam. Finally, we propose AdaShift, a novel adaptive learning rate method that decorrelates $v_t$ and $g_t$ by temporal shifting, i.e., using temporally shifted gradient $g_{t-n}$ to calculate $v_t$. The experiment results demonstrate that AdaShift is able to address the non-convergence issue of Adam, while still maintaining a competitive performance with Adam in terms of both training speed and generalization.
AM-GAN: Improved Usage of Class-Labels in Generative Adversarial Nets
Jul 11, 2018
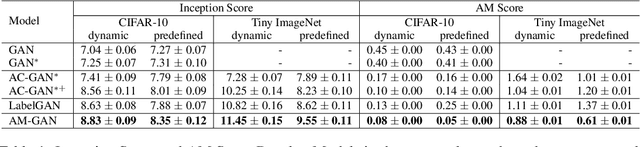
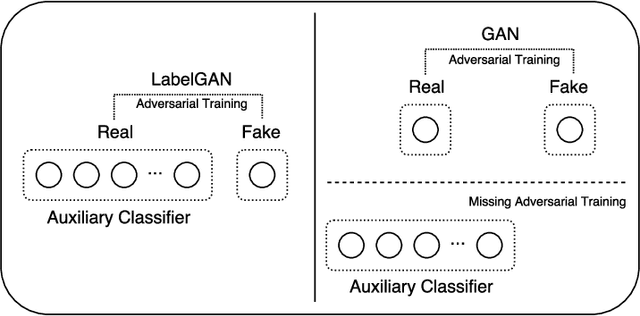

Class labels have been empirically shown useful in improving the sample quality of generative adversarial nets (GANs). In this paper, we mathematically study the properties of the current variants of GANs that make use of class label information. With class aware gradient and cross-entropy decomposition, we reveal how class labels and associated losses influence GAN's training. Based on that, we propose Activation Maximization Generative Adversarial Networks (AM-GAN) as an advanced solution. Comprehensive experiments have been conducted to validate our analysis and evaluate the effectiveness of our solution, where AM-GAN outperforms other strong baselines and achieves state-of-the-art Inception Score (8.91) on CIFAR-10. In addition, we demonstrate that, with the Inception ImageNet classifier, Inception Score mainly tracks the diversity of the generator, and there is, however, no reliable evidence that it can reflect the true sample quality. We thus propose a new metric, called AM Score, to provide a more accurate estimation of the sample quality. Our proposed model also outperforms the baseline methods in the new metric.
Inception Score, Label Smoothing, Gradient Vanishing and -log(D(x)) Alternative
Jun 30, 2018
In this article, we mathematically study several GAN related topics, including Inception score, label smoothing, gradient vanishing and the -log(D(x)) alternative. --- An advanced version is included in arXiv:1703.02000 "Activation Maximization Generative Adversarial Nets". Please refer Section 6 in 1703.02000 for detailed analysis on Inception Score, and refer its appendix for the discussions on Label Smoothing, Gradient Vanishing and -log(D(x)) Alternative.
Learning to Design Games: Strategic Environments in Reinforcement Learning
May 23, 2018
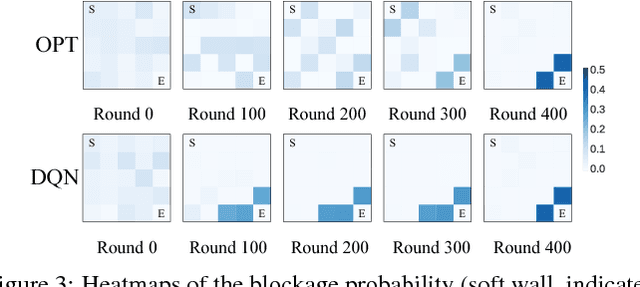
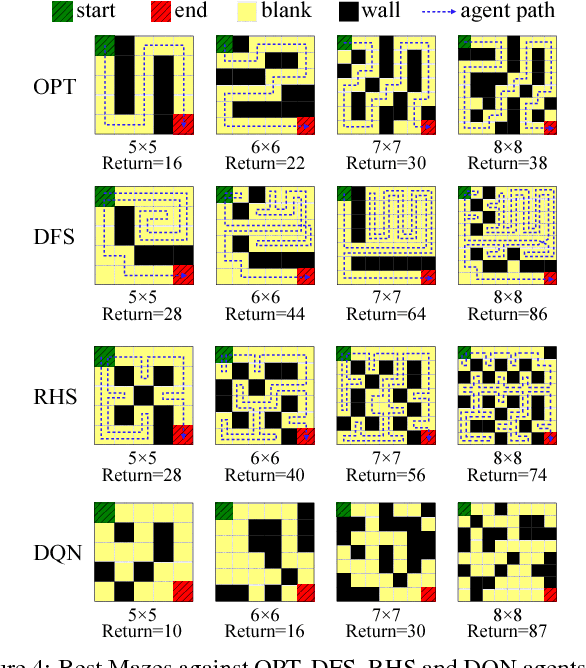
In typical reinforcement learning (RL), the environment is assumed given and the goal of the learning is to identify an optimal policy for the agent taking actions through its interactions with the environment. In this paper, we extend this setting by considering the environment is not given, but controllable and learnable through its interaction with the agent at the same time. This extension is motivated by environment design scenarios in the real-world, including game design, shopping space design and traffic signal design. Theoretically, we find a dual Markov decision process (MDP) w.r.t. the environment to that w.r.t. the agent, and derive a policy gradient solution to optimizing the parametrized environment. Furthermore, discontinuous environments are addressed by a proposed general generative framework. Our experiments on a Maze game design task show the effectiveness of the proposed algorithms in generating diverse and challenging Mazes against various agent settings.
Face Transfer with Generative Adversarial Network
Oct 17, 2017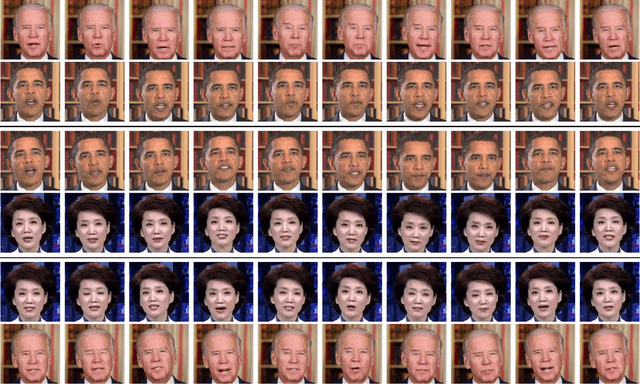



Face transfer animates the facial performances of the character in the target video by a source actor. Traditional methods are typically based on face modeling. We propose an end-to-end face transfer method based on Generative Adversarial Network. Specifically, we leverage CycleGAN to generate the face image of the target character with the corresponding head pose and facial expression of the source. In order to improve the quality of generated videos, we adopt PatchGAN and explore the effect of different receptive field sizes on generated images.
Unsupervised Diverse Colorization via Generative Adversarial Networks
Jul 01, 2017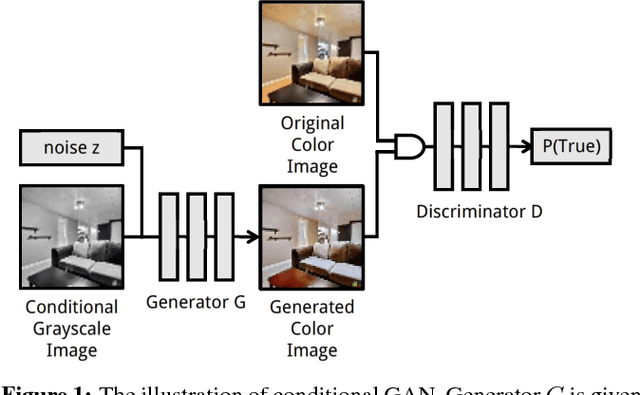
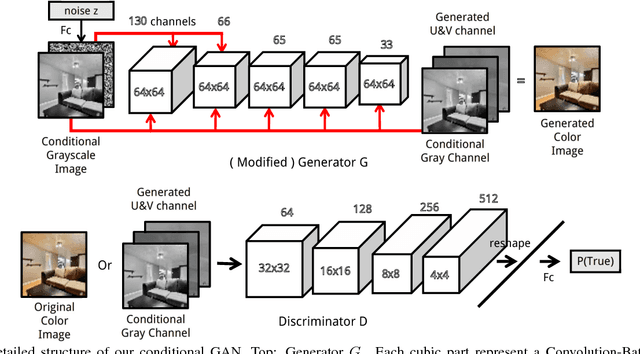


Colorization of grayscale images has been a hot topic in computer vision. Previous research mainly focuses on producing a colored image to match the original one. However, since many colors share the same gray value, an input grayscale image could be diversely colored while maintaining its reality. In this paper, we design a novel solution for unsupervised diverse colorization. Specifically, we leverage conditional generative adversarial networks to model the distribution of real-world item colors, in which we develop a fully convolutional generator with multi-layer noise to enhance diversity, with multi-layer condition concatenation to maintain reality, and with stride 1 to keep spatial information. With such a novel network architecture, the model yields highly competitive performance on the open LSUN bedroom dataset. The Turing test of 80 humans further indicates our generated color schemes are highly convincible.