 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Fine-tuning for Pre-trained 3D Point Cloud Models
Apr 25, 2024This paper presents a robust fine-tuning method designed for pre-trained 3D point cloud models, to enhance feature robustness in downstream fine-tuned models. We highlight the limitations of current fine-tuning methods and the challenges of learning robust models. The proposed method, named Weight-Space Ensembles for Fine-Tuning then Linear Probing (WiSE-FT-LP), integrates the original pre-training and fine-tuning models through weight space integration followed by Linear Probing. This approach significantly enhances the performance of downstream fine-tuned models under distribution shifts, improving feature robustness while maintaining high performance on the target distribution. We apply this robust fine-tuning method to mainstream 3D point cloud pre-trained models and evaluate the quality of model parameters and the degradation of downstream task performance. Experimental results demonstrate the effectiveness of WiSE-FT-LP in enhancing model robustness, effectively balancing downstream task performance and model feature robustness without altering the model structures.
Beamforming Optimization for Active RIS-Aided Multiuser Communications With Hardware Impairments
Feb 16, 2024



In this paper, we consider an active reconfigurable intelligent surface (RIS) to assist the multiuser downlink transmission in the presence of practical hardware impairments (HWIs), including the HWIs at the transceivers and the phase noise at the active RIS. The active RIS is deployed to amplify the incident signals to alleviate the multiplicative fading effect, which is a limitation in the conventional passive RIS-aided wireless systems. We aim to maximize the sum rate through jointly designing the transmit beamforming at the base station (BS), the amplification factors and the phase shifts at the active RIS. To tackle this challenging optimization problem effectively, we decouple it into two tractable subproblems. Subsequently, each subproblem is transformed into a second order cone programming problem. The block coordinate descent framework is applied to tackle them, where the transmit beamforming and the reflection coefficients are alternately designed. In addition, another efficient algorithm is presented to reduce the computational complexity. Specifically, by exploiting the majorization-minimization approach, each subproblem is reformulated into a tractable surrogate problem, whose closed-form solutions are obtained by Lagrange dual decomposition approach and element-wise alternating sequential optimization method. Simulation results validate the effectiveness of our developed algorithms, and reveal that the HWIs significantly limit the system performance of active RIS-empowered wireless communications. Furthermore, the active RIS noticeably boosts the sum rate under the same total power budget, compared with the passive RIS.
Data Poisoning Attacks on EEG Signal-based Risk Assessment Systems
Feb 08, 2023



Industrial insider risk assessment using electroencephalogram (EEG) signals has consistently attracted a lot of research attention. However, EEG signal-based risk assessment systems, which could evaluate the emotional states of humans, have shown several vulnerabilities to data poison attacks. In this paper, from the attackers' perspective, data poison attacks involving label-flipping occurring in the training stages of different machine learning models intrude on the EEG signal-based risk assessment systems using these machine learning models. This paper aims to propose two categories of label-flipping methods to attack different machine learning classifiers including Adaptive Boosting (AdaBoost), Multilayer Perceptron (MLP), Random Forest, and K-Nearest Neighbors (KNN) dedicated to the classification of 4 different human emotions using EEG signals. This aims to degrade the performance of the aforementioned machine learning models concerning the classification task. The experimental results show that the proposed data poison attacks are model-agnostically effective whereas different models have different resilience to the data poison attacks.
Explainable Label-flipping Attacks on Human Emotion Assessment System
Feb 08, 2023This paper's main goal is to provide an attacker's point of view on data poisoning assaults that use label-flipping during the training phase of systems that use electroencephalogram (EEG) signals to evaluate human emotion. To attack different machine learning classifiers such as Adaptive Boosting (AdaBoost) and Random Forest dedicated to the classification of 4 different human emotions using EEG signals, this paper proposes two scenarios of label-flipping methods. The results of the studies show that the proposed data poison attacksm based on label-flipping are successful regardless of the model, but different models show different degrees of resistance to the assaults. In addition, numerous Explainable Artificial Intelligence (XAI) techniques are used to explain the data poison attacks on EEG signal-based human emotion evaluation systems.
Explainable Data Poison Attacks on Human Emotion Evaluation Systems based on EEG Signals
Jan 17, 2023



The major aim of this paper is to explain the data poisoning attacks using label-flipping during the training stage of the electroencephalogram (EEG) signal-based human emotion evaluation systems deploying Machine Learning models from the attackers' perspective. Human emotion evaluation using EEG signals has consistently attracted a lot of research attention. The identification of human emotional states based on EEG signals is effective to detect potential internal threats caused by insider individuals. Nevertheless, EEG signal-based human emotion evaluation systems have shown several vulnerabilities to data poison attacks. The findings of the experiments demonstrate that the suggested data poison assaults are model-independently successful, although various models exhibit varying levels of resilience to the attacks. In addition, the data poison attacks on the EEG signal-based human emotion evaluation systems are explained with several Explainable Artificial Intelligence (XAI) methods, including Shapley Additive Explanation (SHAP) values, Local Interpretable Model-agnostic Explanations (LIME), and Generated Decision Trees. And the codes of this paper are publicly available on GitHub.
A Late Multi-Modal Fusion Model for Detecting Hybrid Spam E-mail
Oct 26, 2022In recent years, spammers are now trying to obfuscate their intents by introducing hybrid spam e-mail combining both image and text parts, which is more challenging to detect in comparison to e-mails containing text or image only. The motivation behind this research is to design an effective approach filtering out hybrid spam e-mails to avoid situations where traditional text-based or image-baesd only filters fail to detect hybrid spam e-mails. To the best of our knowledge, a few studies have been conducted with the goal of detecting hybrid spam e-mails. Ordinarily, Optical Character Recognition (OCR) technology is used to eliminate the image parts of spam by transforming images into text. However, the research questions are that although OCR scanning is a very successful technique in processing text-and-image hybrid spam, it is not an effective solution for dealing with huge quantities due to the CPU power required and the execution time it takes to scan e-mail files. And the OCR techniques are not always reliable in the transformation processes. To address such problems, we propose new late multi-modal fusion training frameworks for a text-and-image hybrid spam e-mail filtering system compared to the classical early fusion detection frameworks based on the OCR method. Convolutional Neural Network (CNN) and Continuous Bag of Words were implemented to extract features from image and text parts of hybrid spam respectively, whereas generated features were fed to sigmoid layer and Machine Learning based classifiers including Random Forest (RF), Decision Tree (DT), Naive Bayes (NB) and Support Vector Machine (SVM) to determine the e-mail ham or spam.
Explainable Artificial Intelligence to Detect Image Spam Using Convolutional Neural Network
Sep 07, 2022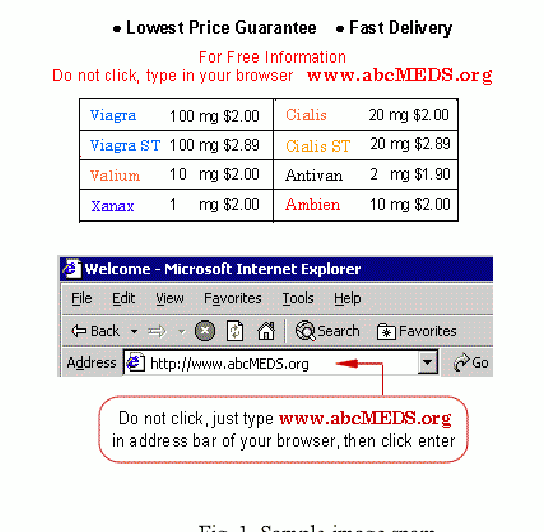
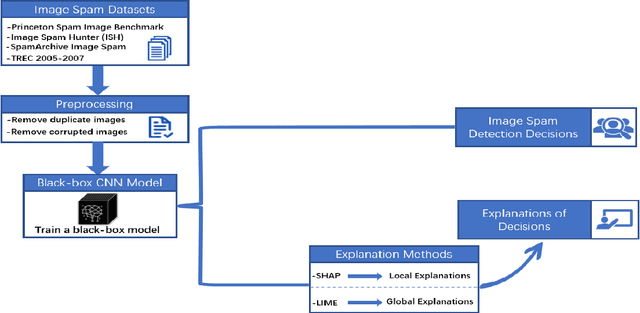
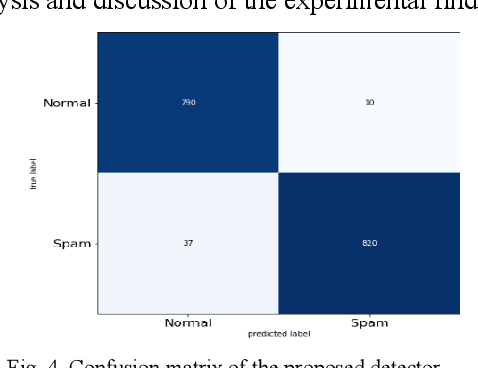

Image spam threat detection has continually been a popular area of research with the internet's phenomenal expansion. This research presents an explainable framework for detecting spam images using Convolutional Neural Network(CNN) algorithms and Explainable Artificial Intelligence (XAI) algorithms. In this work, we use CNN model to classify image spam respectively whereas the post-hoc XAI methods including Local Interpretable Model Agnostic Explanation (LIME) and Shapley Additive Explanations (SHAP) were deployed to provide explanations for the decisions that the black-box CNN models made about spam image detection. We train and then evaluate the performance of the proposed approach on a 6636 image dataset including spam images and normal images collected from three different publicly available email corpora. The experimental results show that the proposed framework achieved satisfactory detection results in terms of different performance metrics whereas the model-independent XAI algorithms could provide explanations for the decisions of different models which could be utilized for comparison for the future study.
Person Monitoring by Full Body Tracking in Uniform Crowd Environment
Sep 02, 2022

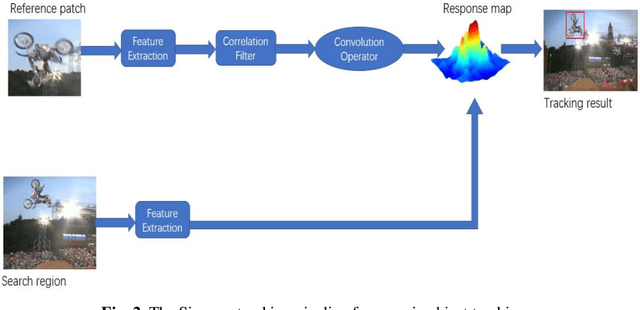
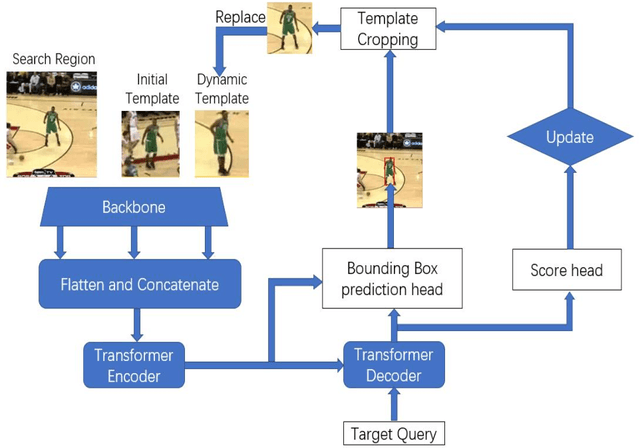
Full body trackers are utilized for surveillance and security purposes, such as person-tracking robots. In the Middle East, uniform crowd environments are the norm which challenges state-of-the-art trackers. Despite tremendous improvements in tracker technology documented in the past literature, these trackers have not been trained using a dataset that captures these environments. In this work, we develop an annotated dataset with one specific target per video in a uniform crowd environment. The dataset was generated in four different scenarios where mainly the target was moving alongside the crowd, sometimes occluding with them, and other times the camera's view of the target is blocked by the crowd for a short period. After the annotations, it was used in evaluating and fine-tuning a state-of-the-art tracker. Our results have shown that the fine-tuned tracker performed better on the evaluation dataset based on two quantitative evaluation metrics, compared to the initial pre-trained tracker.
Deep Reinforcement Learning for RIS-aided Multiuser Full-Duplex Secure Communications with Hardware Impairments
Aug 16, 2022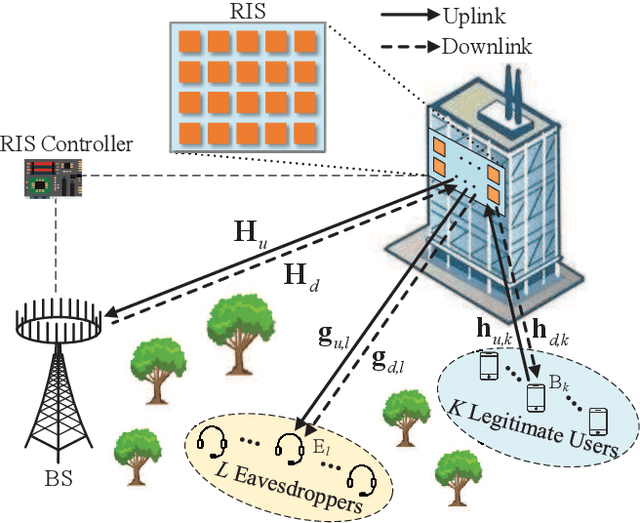
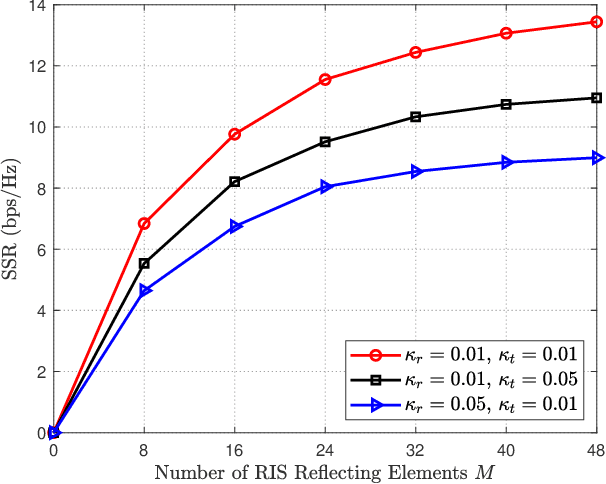
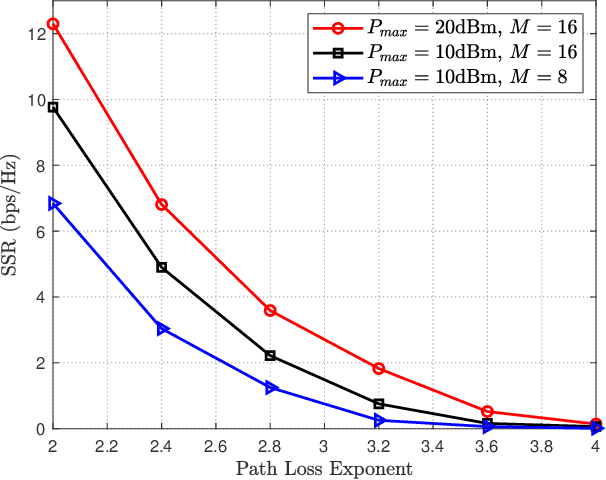
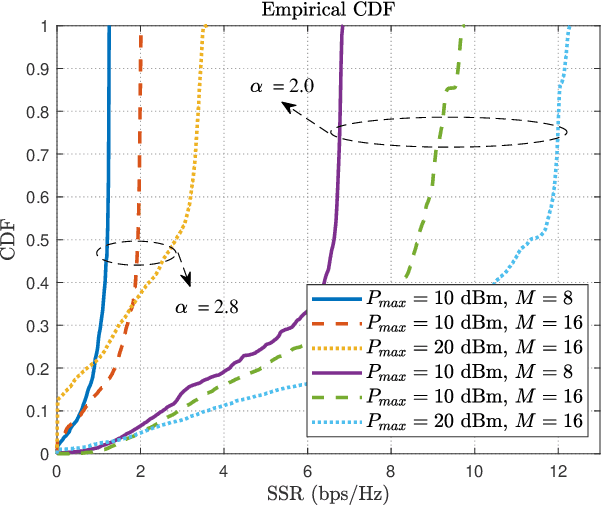
In this paper, we investigate a reconfigurable intelligent surface (RIS)-aided multiuser full-duplex secure communication system with hardware impairments at transceivers and RIS, where multiple eavesdroppers overhear the two-way transmitted signals simultaneously, and an RIS is applied to enhance the secrecy performance. Aiming at maximizing the sum secrecy rate (SSR), a joint optimization problem of the transmit beamforming at the base station (BS) and the reflecting beamforming at the RIS is formulated under the transmit power constraint of the BS and the unit modulus constraint of the phase shifters. As the environment is time-varying and the system is high-dimensional, this non-convex optimization problem is mathematically intractable. A deep reinforcement learning (DRL)-based algorithm is explored to obtain the satisfactory solution by repeatedly interacting with and learning from the dynamic environment. Extensive simulation results illustrate that the DRL-based secure beamforming algorithm is proved to be significantly effective in improving the SSR. It is also found that the performance of the DRL-based method can be greatly improved and the convergence speed of neural network can be accelerated with appropriate neural network parameters.
A new database of Houma Alliance Book ancient handwritten characters and its baseline algorithm
Jul 17, 2022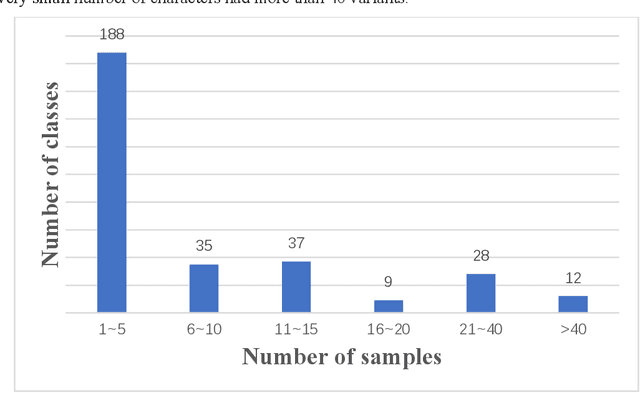

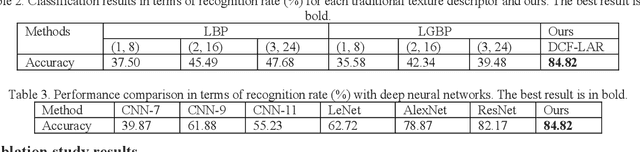

The Houma Alliance Book is one of the national treasures of the Museum in Shanxi Museum Town in China. It has great historical significance in researching ancient history. To date, the research on the Houma Alliance Book has been staying in the identification of paper documents, which is inefficient to identify and difficult to display, study and publicize. Therefore, the digitization of the recognized ancient characters of Houma League can effectively improve the efficiency of recognizing ancient characters and provide more reliable technical support and text data. This paper proposes a new database of Houma Alliance Book ancient handwritten characters and a multi-modal fusion method to recognize ancient handwritten characters. In the database, 297 classes and 3,547 samples of Houma Alliance ancient handwritten characters are collected from the original book collection and by human imitative writing. Furthermore, the decision-level classifier fusion strategy is applied to fuse three well-known deep neural network architectures for ancient handwritten character recognition. Experiments are performed on our new database. The experimental results first provide the baseline result of the new database to the research community and then demonstrate the efficiency of our proposed method.