 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Hypergraph Convolutional Network for No-Reference 360-degree Image Quality Assessment
May 19, 2021



In no-reference 360-degree image quality assessment (NR 360IQA), graph convolutional networks (GCNs), which model interactions between viewports through graphs, have achieved impressive performance. However, prevailing GCN-based NR 360IQA methods suffer from three main limitations. First, they only use high-level features of the distorted image to regress the quality score, while the human visual system (HVS) scores the image based on hierarchical features. Second, they simplify complex high-order interactions between viewports in a pairwise fashion through graphs. Third, in the graph construction, they only consider spatial locations of viewports, ignoring its content characteristics. Accordingly, to address these issues, we propose an adaptive hypergraph convolutional network for NR 360IQA, denoted as AHGCN. Specifically, we first design a multi-level viewport descriptor for extracting hierarchical representations from viewports. Then, we model interactions between viewports through hypergraphs, where each hyperedge connects two or more viewports. In the hypergraph construction, we build a location-based hyperedge and a content-based hyperedge for each viewport. Experimental results on two public 360IQA databases demonstrate that our proposed approach has a clear advantage over state-of-the-art full-reference and no-reference IQA models.
Image Super-Resolution Quality Assessment: Structural Fidelity Versus Statistical Naturalness
May 15, 2021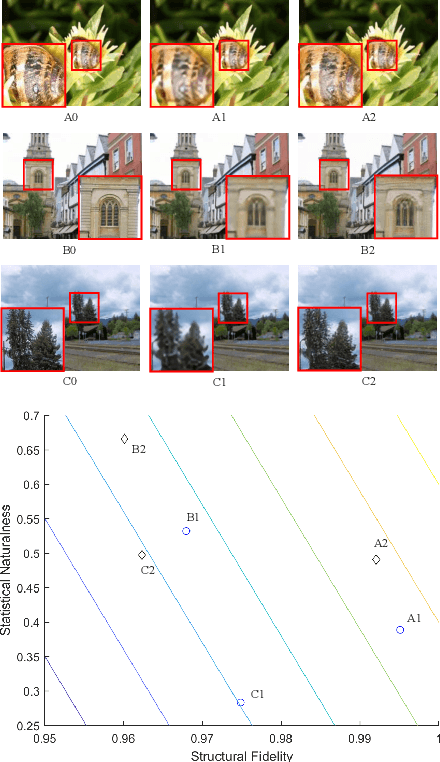
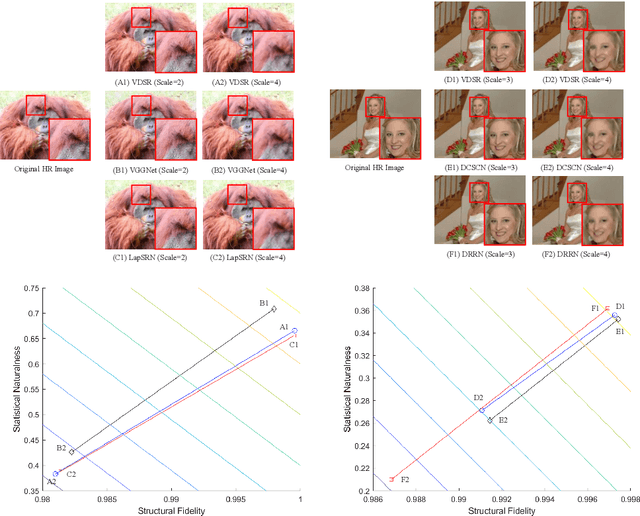
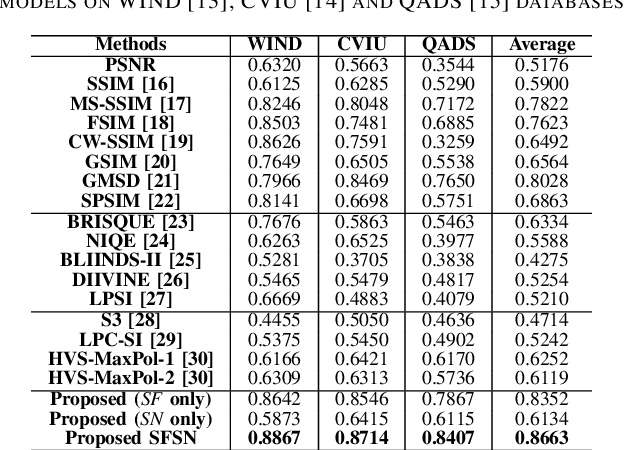
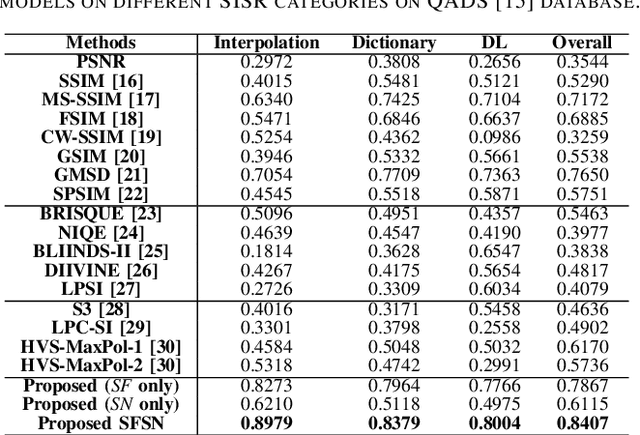
Single image super-resolution (SISR) algorithms reconstruct high-resolution (HR) images with their low-resolution (LR) counterparts. It is desirable to develop image quality assessment (IQA) methods that can not only evaluate and compare SISR algorithms, but also guide their future development. In this paper, we assess the quality of SISR generated images in a two-dimensional (2D) space of structural fidelity versus statistical naturalness. This allows us to observe the behaviors of different SISR algorithms as a tradeoff in the 2D space. Specifically, SISR methods are traditionally designed to achieve high structural fidelity but often sacrifice statistical naturalness, while recent generative adversarial network (GAN) based algorithms tend to create more natural-looking results but lose significantly on structural fidelity. Furthermore, such a 2D evaluation can be easily fused to a scalar quality prediction. Interestingly, we find that a simple linear combination of a straightforward local structural fidelity and a global statistical naturalness measures produce surprisingly accurate predictions of SISR image quality when tested using public subject-rated SISR image datasets. Code of the proposed SFSN model is publicly available at \url{https://github.com/weizhou-geek/SFSN}.
Soft then Hard: Rethinking the Quantization in Neural Image Compression
May 13, 2021

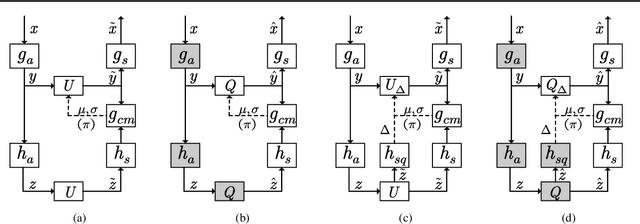

Quantization is one of the core components in lossy image compression. For neural image compression, end-to-end optimization requires differentiable approximations of quantization, which can generally be grouped into three categories: additive uniform noise, straight-through estimator and soft-to-hard annealing. Training with additive uniform noise approximates the quantization error variationally but suffers from the train-test mismatch. The other two methods do not encounter this mismatch but, as shown in this paper, hurt the rate-distortion performance since the latent representation ability is weakened. We thus propose a novel soft-then-hard quantization strategy for neural image compression that first learns an expressive latent space softly, then solves the train-test mismatch with hard quantization. In addition, beyond the fixed integer quantization, we apply scaled additive uniform noise to adaptively control the quantization granularity by deriving a new variational upper bound on actual rate. Experiments demonstrate that our proposed methods are easy to adopt, stable to train, and highly effective especially on complex compression models.
Cloth-Changing Person Re-identification from A Single Image with Gait Prediction and Regularization
Apr 18, 2021
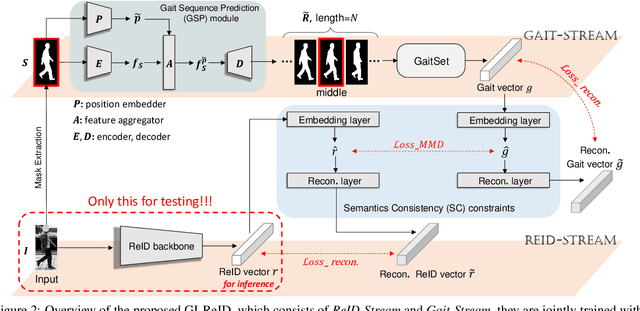
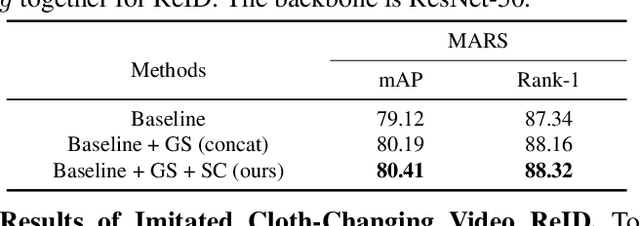
Cloth-Changing person re-identification (CC-ReID) aims at matching the same person across different locations over a long-duration, e.g., over days, and therefore inevitably meets challenge of changing clothing. In this paper, we focus on handling well the CC-ReID problem under a more challenging setting, i.e., just from a single image, which enables high-efficiency and latency-free pedestrian identify for real-time surveillance applications. Specifically, we introduce Gait recognition as an auxiliary task to drive the Image ReID model to learn cloth-agnostic representations by leveraging personal unique and cloth-independent gait information, we name this framework as GI-ReID. GI-ReID adopts a two-stream architecture that consists of a image ReID-Stream and an auxiliary gait recognition stream (Gait-Stream). The Gait-Stream, that is discarded in the inference for high computational efficiency, acts as a regulator to encourage the ReID-Stream to capture cloth-invariant biometric motion features during the training. To get temporal continuous motion cues from a single image, we design a Gait Sequence Prediction (GSP) module for Gait-Stream to enrich gait information. Finally, a high-level semantics consistency over two streams is enforced for effective knowledge regularization. Experiments on multiple image-based Cloth-Changing ReID benchmarks, e.g., LTCC, PRCC, Real28, and VC-Clothes, demonstrate that GI-ReID performs favorably against the state-of-the-arts. Codes are available at https://github.com/jinx-USTC/GI-ReID.
Bayesian Graph Convolutional Network for Traffic Prediction
Apr 01, 2021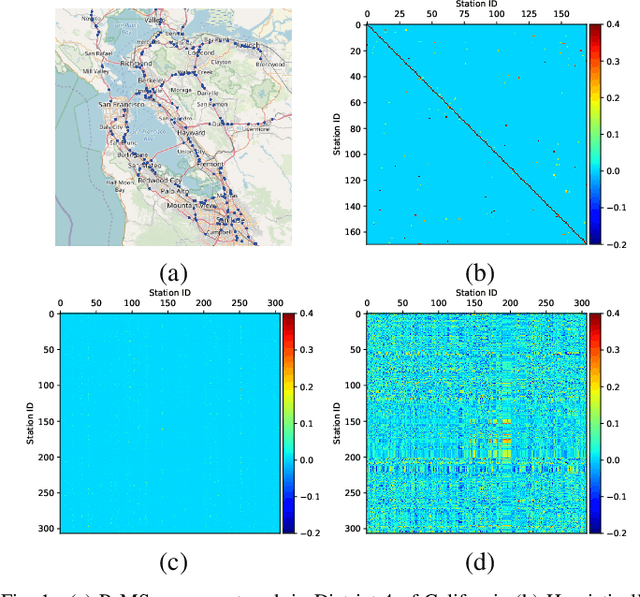
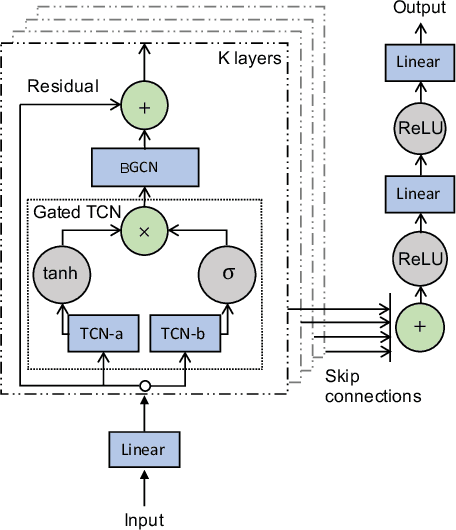
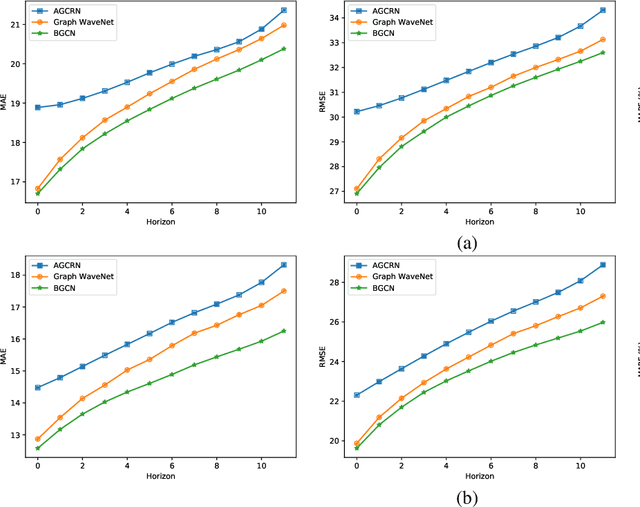
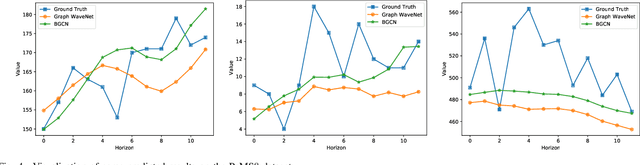
Recently, adaptive graph convolutional network based traffic prediction methods, learning a latent graph structure from traffic data via various attention-based mechanisms, have achieved impressive performance. However, they are still limited to find a better description of spatial relationships between traffic conditions due to: (1) ignoring the prior of the observed topology of the road network; (2) neglecting the presence of negative spatial relationships; and (3) lacking investigation on uncertainty of the graph structure. In this paper, we propose a Bayesian Graph Convolutional Network (BGCN) framework to alleviate these issues. Under this framework, the graph structure is viewed as a random realization from a parametric generative model, and its posterior is inferred using the observed topology of the road network and traffic data. Specifically, the parametric generative model is comprised of two parts: (1) a constant adjacency matrix which discovers potential spatial relationships from the observed physical connections between roads using a Bayesian approach; (2) a learnable adjacency matrix that learns a global shared spatial correlations from traffic data in an end-to-end fashion and can model negative spatial correlations. The posterior of the graph structure is then approximated by performing Monte Carlo dropout on the parametric graph structure. We verify the effectiveness of our method on five real-world datasets, and the experimental results demonstrate that BGCN attains superior performance compared with state-of-the-art methods.
Disentanglement-based Cross-Domain Feature Augmentation for Effective Unsupervised Domain Adaptive Person Re-identification
Mar 25, 2021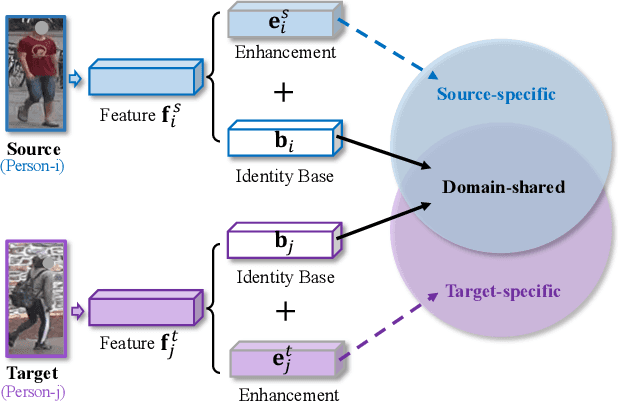
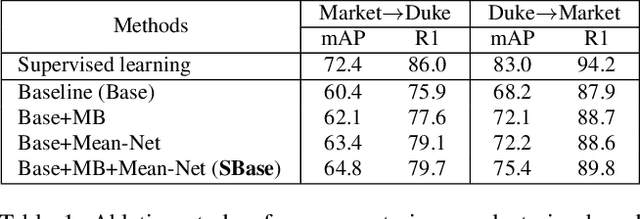
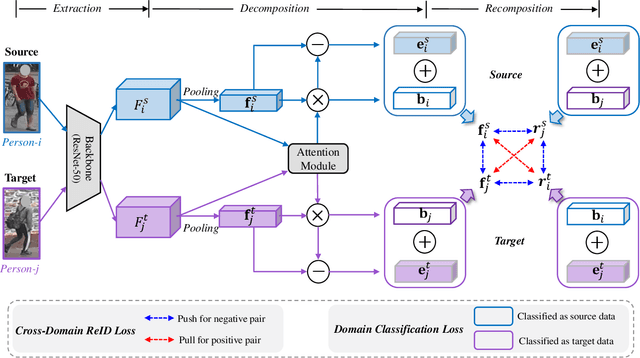
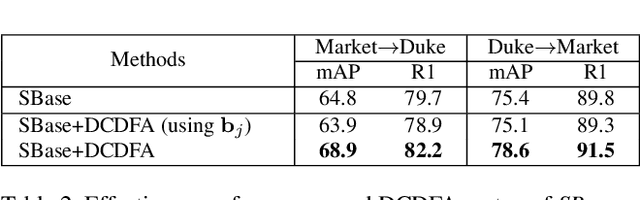
Unsupervised domain adaptive (UDA) person re-identification (ReID) aims to transfer the knowledge from the labeled source domain to the unlabeled target domain for person matching. One challenge is how to generate target domain samples with reliable labels for training. To address this problem, we propose a Disentanglement-based Cross-Domain Feature Augmentation (DCDFA) strategy, where the augmented features characterize well the target and source domain data distributions while inheriting reliable identity labels. Particularly, we disentangle each sample feature into a robust domain-invariant/shared feature and a domain-specific feature, and perform cross-domain feature recomposition to enhance the diversity of samples used in the training, with the constraints of cross-domain ReID loss and domain classification loss. Each recomposed feature, obtained based on the domain-invariant feature (which enables a reliable inheritance of identity) and an enhancement from a domain specific feature (which enables the approximation of real distributions), is thus an "ideal" augmentation. Extensive experimental results demonstrate the effectiveness of our method, which achieves the state-of-the-art performance.
MetaAlign: Coordinating Domain Alignment and Classification for Unsupervised Domain Adaptation
Mar 25, 2021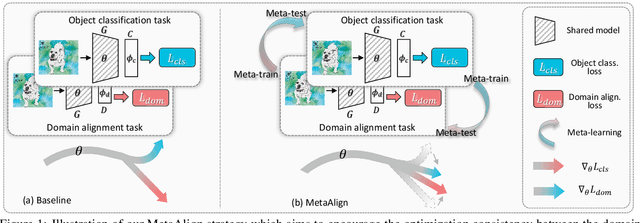
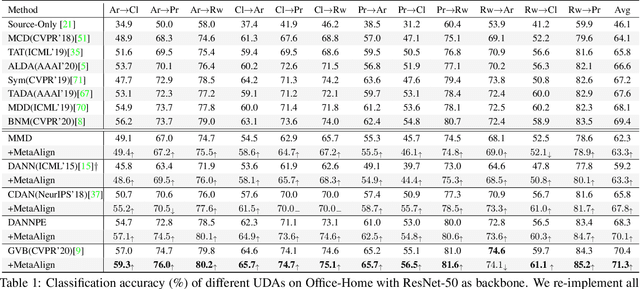
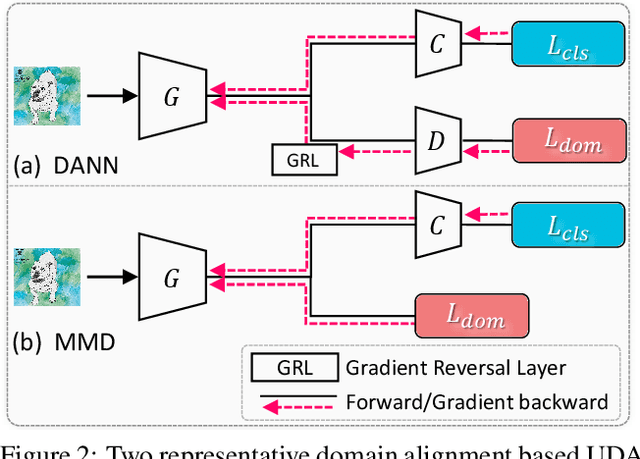
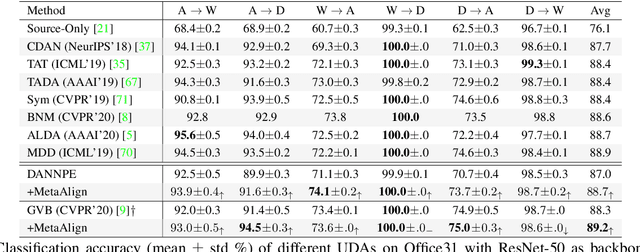
For unsupervised domain adaptation (UDA), to alleviate the effect of domain shift, many approaches align the source and target domains in the feature space by adversarial learning or by explicitly aligning their statistics. However, the optimization objective of such domain alignment is generally not coordinated with that of the object classification task itself such that their descent directions for optimization may be inconsistent. This will reduce the effectiveness of domain alignment in improving the performance of UDA. In this paper, we aim to study and alleviate the optimization inconsistency problem between the domain alignment and classification tasks. We address this by proposing an effective meta-optimization based strategy dubbed MetaAlign, where we treat the domain alignment objective and the classification objective as the meta-train and meta-test tasks in a meta-learning scheme. MetaAlign encourages both tasks to be optimized in a coordinated way, which maximizes the inner product of the gradients of the two tasks during training. Experimental results demonstrate the effectiveness of our proposed method on top of various alignment-based baseline approaches, for tasks of object classification and object detection. MetaAlign helps achieve the state-of-the-art performance.
Re-energizing Domain Discriminator with Sample Relabeling for Adversarial Domain Adaptation
Mar 22, 2021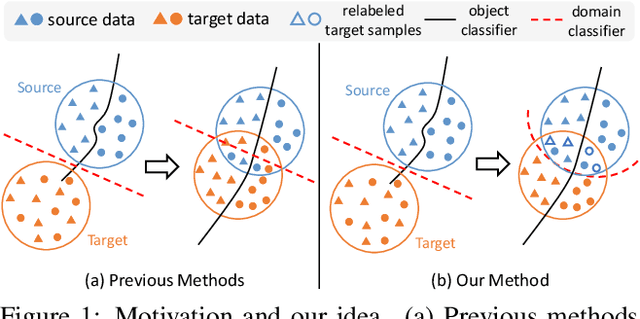
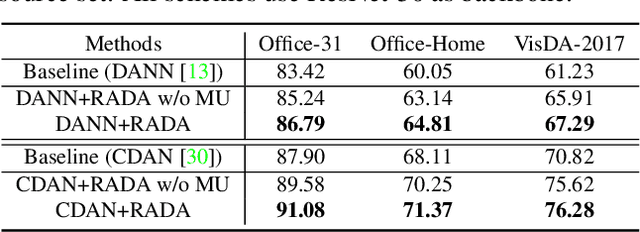
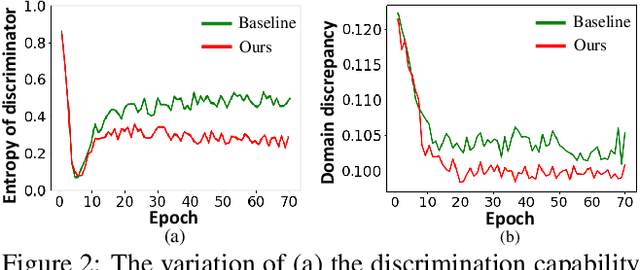
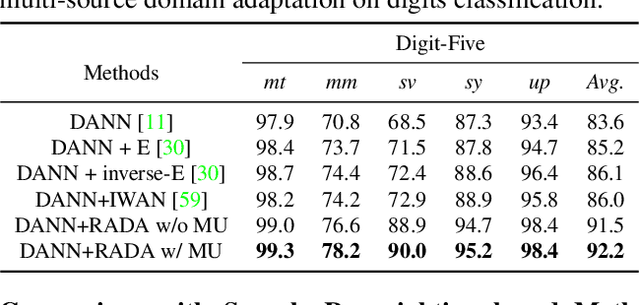
Many unsupervised domain adaptation (UDA) methods exploit domain adversarial training to align the features to reduce domain gap, where a feature extractor is trained to fool a domain discriminator in order to have aligned feature distributions. The discrimination capability of the domain classifier w.r.t the increasingly aligned feature distributions deteriorates as training goes on, thus cannot effectively further drive the training of feature extractor. In this work, we propose an efficient optimization strategy named Re-enforceable Adversarial Domain Adaptation (RADA) which aims to re-energize the domain discriminator during the training by using dynamic domain labels. Particularly, we relabel the well aligned target domain samples as source domain samples on the fly. Such relabeling makes the less separable distributions more separable, and thus leads to a more powerful domain classifier w.r.t. the new data distributions, which in turn further drives feature alignment. Extensive experiments on multiple UDA benchmarks demonstrate the effectiveness and superiority of our RADA.
Patch AutoAugment
Mar 20, 2021
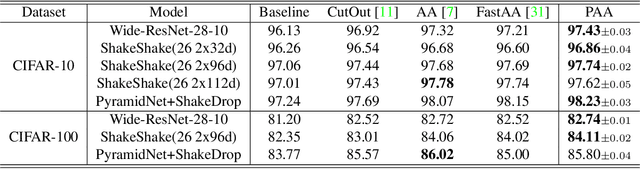
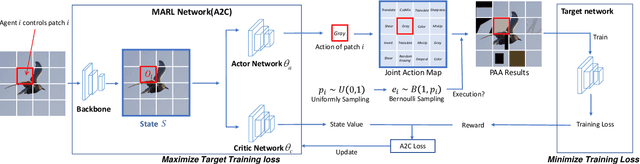
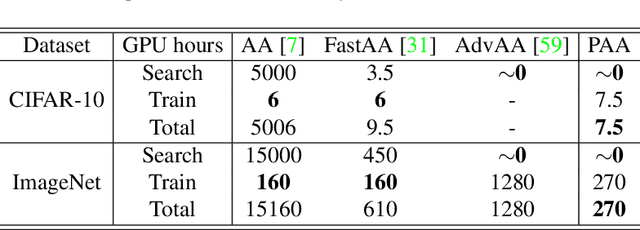
Data augmentation (DA) plays a critical role in training deep neural networks for improving the generalization of models. Recent work has shown that automatic DA policy, such as AutoAugment (AA), significantly improves model performance. However, most automatic DA methods search for DA policies at the image-level without considering that the optimal policies for different regions in an image may be diverse. In this paper, we propose a patch-level automatic DA algorithm called Patch AutoAugment (PAA). PAA divides an image into a grid of patches and searches for the optimal DA policy of each patch. Specifically, PAA allows each patch DA operation to be controlled by an agent and models it as a Multi-Agent Reinforcement Learning (MARL) problem. At each step, PAA samples the most effective operation for each patch based on its content and the semantics of the whole image. The agents cooperate as a team and share a unified team reward for achieving the joint optimal DA policy of the whole image. The experiment shows that PAA consistently improves the target network performance on many benchmark datasets of image classification and fine-grained image recognition. PAA also achieves remarkable computational efficiency, i.e 2.3x faster than FastAA and 56.1x faster than AA on ImageNet.
Dense Interaction Learning for Video-based Person Re-identification
Mar 18, 2021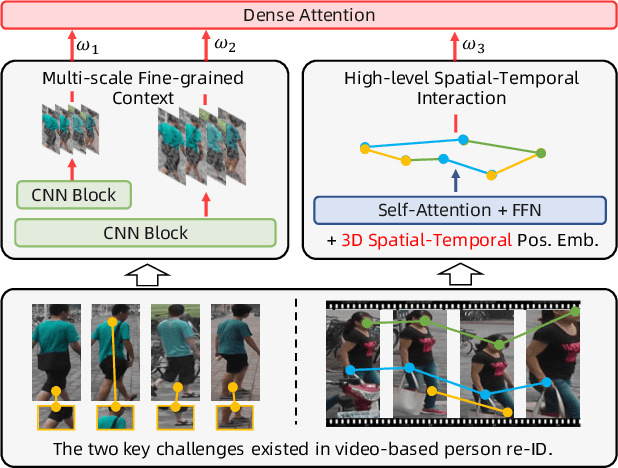
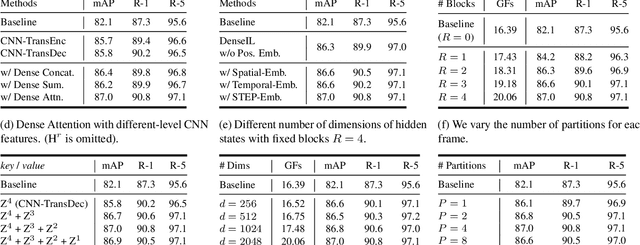
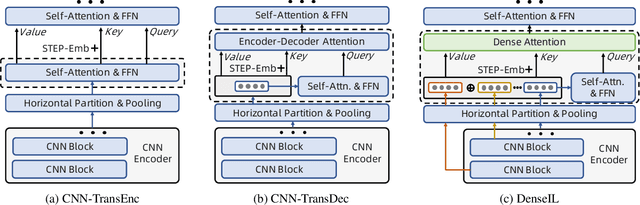
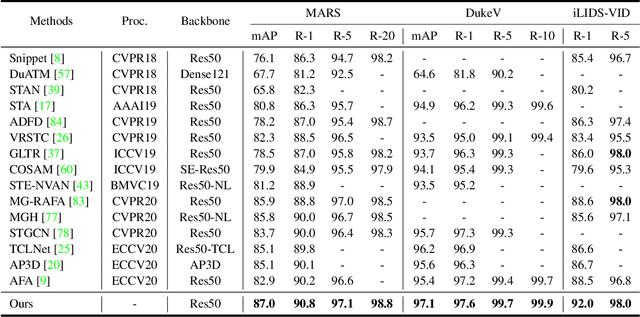
Video-based person re-identification (re-ID) aims at matching the same person across video clips. Efficiently exploiting multi-scale fine-grained features while building the structural interaction among them is pivotal for its success. In this paper, we propose a hybrid framework, Dense Interaction Learning (DenseIL), that takes the principal advantages of both CNN-based and Attention-based architectures to tackle video-based person re-ID difficulties. DenseIL contains a CNN encoder and a Dense Interaction (DI) decoder. The CNN encoder is responsible for efficiently extracting discriminative spatial features while the DI decoder is designed to densely model spatial-temporal inherent interaction across frames. Different from previous works, we additionally let the DI decoder densely attends to intermediate fine-grained CNN features and that naturally yields multi-grained spatial-temporal representation for each video clip. Moreover, we introduce Spatio-TEmporal Positional Embedding (STEP-Emb) into the DI decoder to investigate the positional relation among the spatial-temporal inputs. Our experiments consistently and significantly outperform all the state-of-the-art methods on multiple standard video-based re-ID datasets.