 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed stochastic optimization with large delays
Jul 06, 2021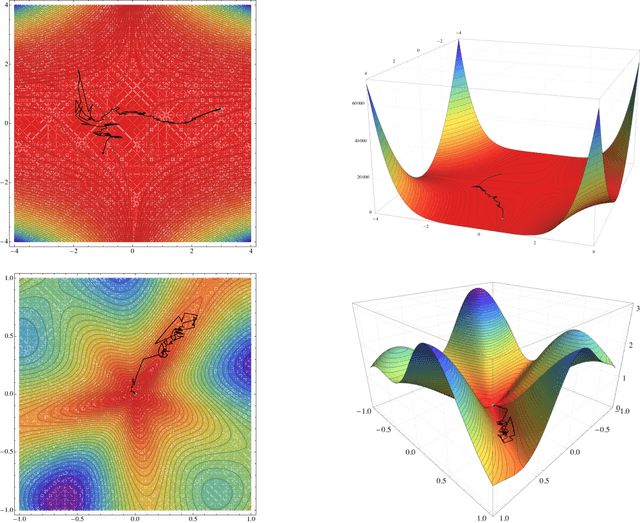
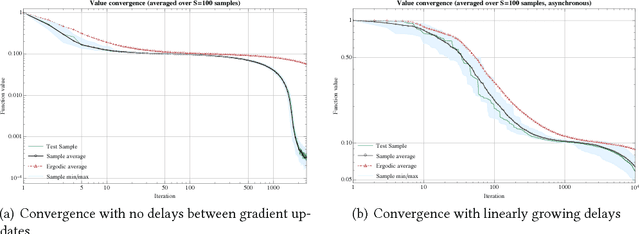
One of the most widely used methods for solving large-scale stochastic optimization problems is distributed asynchronous stochastic gradient descent (DASGD), a family of algorithms that result from parallelizing stochastic gradient descent on distributed computing architectures (possibly) asychronously. However, a key obstacle in the efficient implementation of DASGD is the issue of delays: when a computing node contributes a gradient update, the global model parameter may have already been updated by other nodes several times over, thereby rendering this gradient information stale. These delays can quickly add up if the computational throughput of a node is saturated, so the convergence of DASGD may be compromised in the presence of large delays. Our first contribution is that, by carefully tuning the algorithm's step-size, convergence to the critical set is still achieved in mean square, even if the delays grow unbounded at a polynomial rate. We also establish finer results in a broad class of structured optimization problems (called variationally coherent), where we show that DASGD converges to a global optimum with probability $1$ under the same delay assumptions. Together, these results contribute to the broad landscape of large-scale non-convex stochastic optimization by offering state-of-the-art theoretical guarantees and providing insights for algorithm design.
Policy Learning with Adaptively Collected Data
May 05, 2021


Learning optimal policies from historical data enables the gains from personalization to be realized in a wide variety of applications. The growing policy learning literature focuses on a setting where the treatment assignment policy does not adapt to the data. However, adaptive data collection is becoming more common in practice, from two primary sources: 1) data collected from adaptive experiments that are designed to improve inferential efficiency; 2) data collected from production systems that are adaptively evolving an operational policy to improve performance over time (e.g. contextual bandits). In this paper, we aim to address the challenge of learning the optimal policy with adaptively collected data and provide one of the first theoretical inquiries into this problem. We propose an algorithm based on generalized augmented inverse propensity weighted estimators and establish its finite-sample regret bound. We complement this regret upper bound with a lower bound that characterizes the fundamental difficulty of policy learning with adaptive data. Finally, we demonstrate our algorithm's effectiveness using both synthetic data and public benchmark datasets.
Simple Agent, Complex Environment: Efficient Reinforcement Learning with Agent State
Mar 08, 2021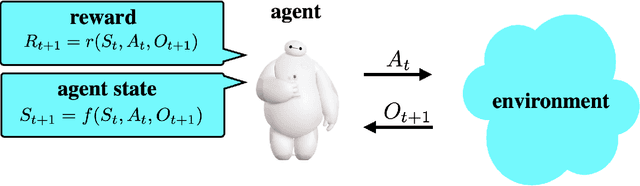
We design a simple reinforcement learning agent that, with a specification only of agent state dynamics and a reward function, can operate with some degree of competence in any environment. The agent maintains only visitation counts and value estimates for each agent-state-action pair. The value function is updated incrementally in response to temporal differences and optimistic boosts that encourage exploration. The agent executes actions that are greedy with respect to this value function. We establish a regret bound demonstrating convergence to near-optimal per-period performance, where the time taken to achieve near-optimality is polynomial in the number of agent states and actions, as well as the reward mixing time of the best policy within the reference policy class, which is comprised of those that depend on history only through agent state. Notably, there is no further dependence on the number of environment states or mixing times associated with other policies or statistics of history. Our result sheds light on the potential benefits of (deep) representation learning, which has demonstrated the capability to extract compact and relevant features from high-dimensional interaction histories.
No Discounted-Regret Learning in Adversarial Bandits with Delays
Mar 08, 2021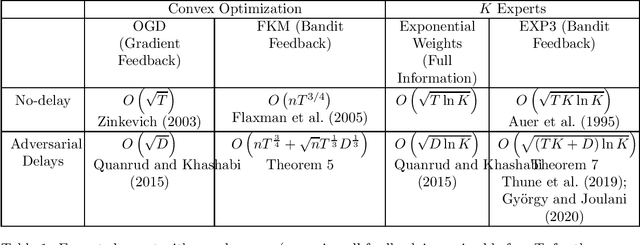

Consider a player that in each round $t$ out of $T$ rounds chooses an action and observes the incurred cost after a delay of $d_{t}$ rounds. The cost functions and the delay sequence are chosen by an adversary. We show that even if the players' algorithms lose their "no regret" property due to too large delays, the expected discounted ergodic distribution of play converges to the set of coarse correlated equilibrium (CCE) if the algorithms have "no discounted-regret". For a zero-sum game, we show that no discounted-regret is sufficient for the discounted ergodic average of play to converge to the set of Nash equilibria. We prove that the FKM algorithm with $n$ dimensions achieves a regret of $O\left(nT^{\frac{3}{4}}+\sqrt{n}T^{\frac{1}{3}}D^{\frac{1}{3}}\right)$ and the EXP3 algorithm with $K$ arms achieves a regret of $O\left(\sqrt{\ln K\left(KT+D\right)}\right)$ even when $D=\sum_{t=1}^{T}d_{t}$ and $T$ are unknown. These bounds use a novel doubling trick that provably retains the regret bound for when $D$ and $T$ are known. Using these bounds, we show that EXP3 and FKM have no discounted-regret even for $d_{t}=O\left(t\log t\right)$. Therefore, the CCE of a finite or convex unknown game can be approximated even when only delayed bandit feedback is available via simulation.
Doubly-Adaptive Thompson Sampling for Multi-Armed and Contextual Bandits
Feb 25, 2021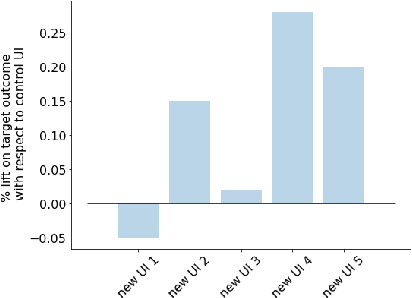
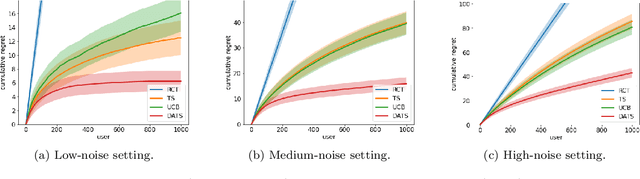
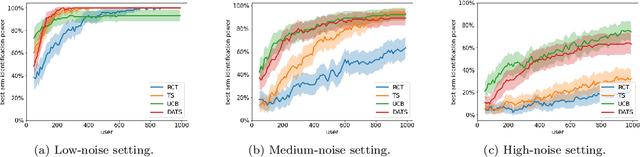
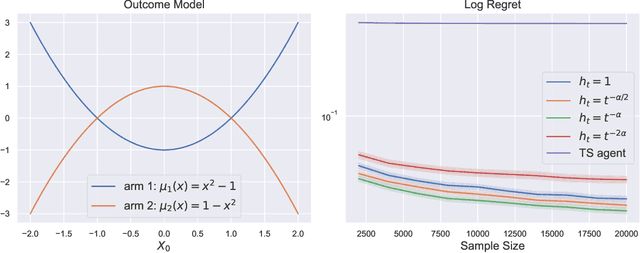
To balance exploration and exploitation, multi-armed bandit algorithms need to conduct inference on the true mean reward of each arm in every time step using the data collected so far. However, the history of arms and rewards observed up to that time step is adaptively collected and there are known challenges in conducting inference with non-iid data. In particular, sample averages, which play a prominent role in traditional upper confidence bound algorithms and traditional Thompson sampling algorithms, are neither unbiased nor asymptotically normal. We propose a variant of a Thompson sampling based algorithm that leverages recent advances in the causal inference literature and adaptively re-weighs the terms of a doubly robust estimator on the true mean reward of each arm -- hence its name doubly-adaptive Thompson sampling. The regret of the proposed algorithm matches the optimal (minimax) regret rate and its empirical evaluation in a semi-synthetic experiment based on data from a randomized control trial of a web service is performed: we see that the proposed doubly-adaptive Thompson sampling has superior empirical performance to existing baselines in terms of cumulative regret and statistical power in identifying the best arm. Further, we extend this approach to contextual bandits, where there are more sources of bias present apart from the adaptive data collection -- such as the mismatch between the true data generating process and the reward model assumptions or the unequal representations of certain regions of the context space in initial stages of learning -- and propose the linear contextual doubly-adaptive Thompson sampling and the non-parametric contextual doubly-adaptive Thompson sampling extensions of our approach.
Federated LQR: Learning through Sharing
Nov 03, 2020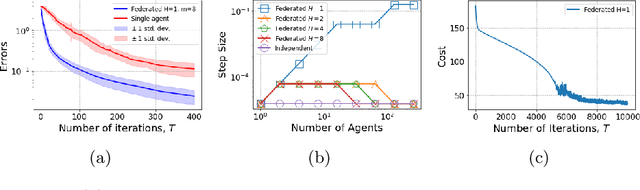
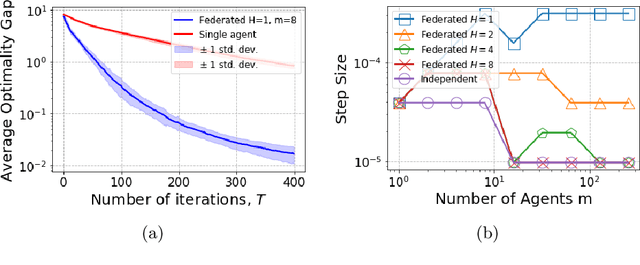
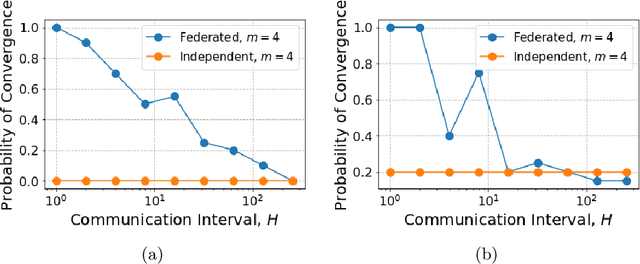
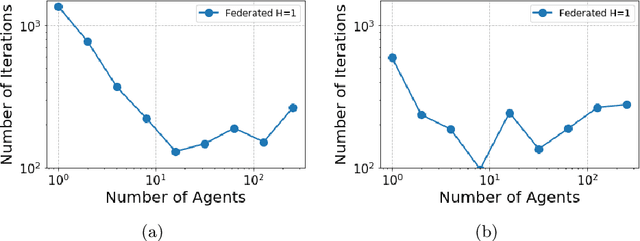
In many multi-agent reinforcement learning applications such as flocking, multi-robot applications and smart manufacturing, distinct agents share similar dynamics but face different objectives. In these applications, an important question is how the similarities amongst the agents can accelerate learning in spite of the agents' differing goals. We study a distributed LQR (Linear Quadratic Regulator) tracking problem which models this setting, where the agents, acting independently, share identical (unknown) dynamics and cost structure but need to track different targets. In this paper, we propose a communication-efficient, federated model-free zeroth-order algorithm that provably achieves a convergence speedup linear in the number of agents compared with the communication-free setup where each agent's problem is treated independently. We support our arguments with numerical simulations of both linear and nonlinear systems.
Dynamic Batch Learning in High-Dimensional Sparse Linear Contextual Bandits
Aug 28, 2020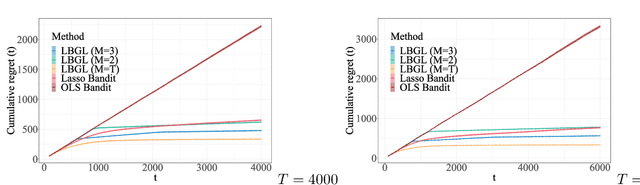
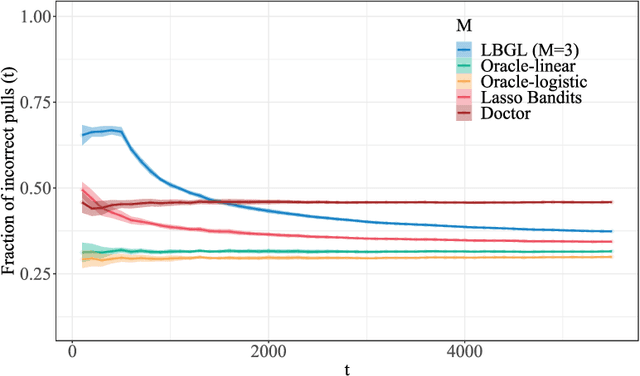
We study the problem of dynamic batch learning in high-dimensional sparse linear contextual bandits, where a decision maker, under a given maximum-number-of-batch constraint and only able to observe rewards at the end of each batch, can dynamically decide how many individuals to include in the next batch (at the end of the current batch) and what personalized action-selection scheme to adopt within each batch. Such batch constraints are ubiquitous in a variety of practical contexts, including personalized product offerings in marketing and medical treatment selection in clinical trials. We characterize the fundamental learning limit in this problem via a regret lower bound and provide a matching upper bound (up to log factors), thus prescribing an optimal scheme for this problem. To the best of our knowledge, our work provides the first inroad into a theoretical understanding of dynamic batch learning in high-dimensional sparse linear contextual bandits. Notably, even a special case of our result (when no batch constraint is present) yields the first minimax optimal $\tilde{O}(\sqrt{s_0T})$ regret bound for standard online learning in high-dimensional linear contextual bandits (for the no-margin case), where $s_0$ is the sparsity parameter (or an upper bound thereof) and $T$ is the learning horizon. This result (both that $\tilde{O}(\sqrt{s_0 T})$ is achievable and that $\Omega(\sqrt{s_0 T})$ is a lower bound) appears to be unknown in the emerging literature of high-dimensional contextual bandits.
Federated Learning's Blessing: FedAvg has Linear Speedup
Jul 11, 2020
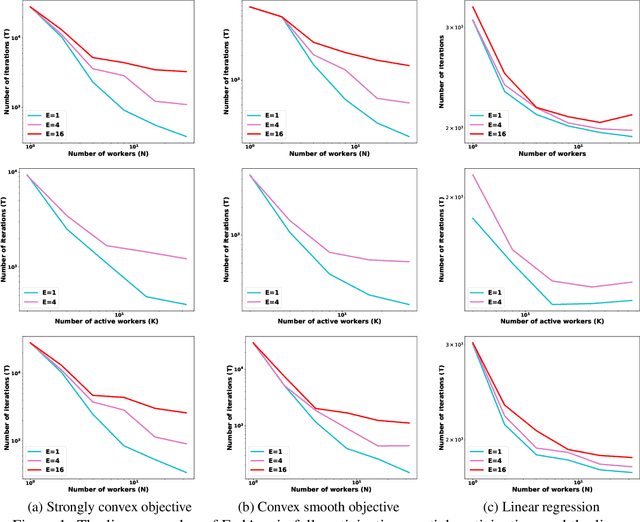
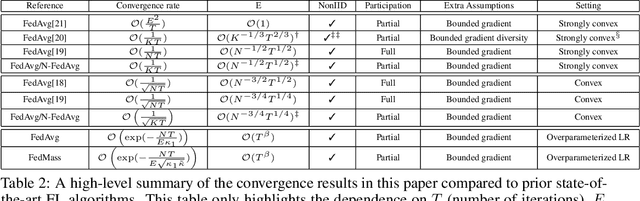
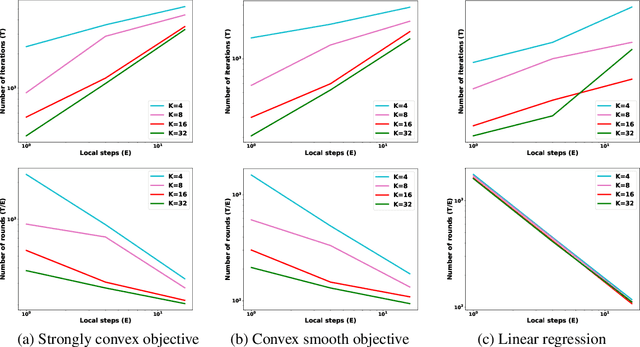
Federated learning (FL) learns a model jointly from a set of participating devices without sharing each other's privately held data. The characteristics of non-iid data across the network, low device participation, and the mandate that data remain private bring challenges in understanding the convergence of FL algorithms, particularly in regards to how convergence scales with the number of participating devices. In this paper, we focus on Federated Averaging (FedAvg)--the most widely used and effective FL algorithm in use today--and provide a comprehensive study of its convergence rate. Although FedAvg has recently been studied by an emerging line of literature, it remains open as to how FedAvg's convergence scales with the number of participating devices in the FL setting--a crucial question whose answer would shed light on the performance of FedAvg in large FL systems. We fill this gap by establishing convergence guarantees for FedAvg under three classes of problems: strongly convex smooth, convex smooth, and overparameterized strongly convex smooth problems. We show that FedAvg enjoys linear speedup in each case, although with different convergence rates. For each class, we also characterize the corresponding convergence rates for the Nesterov accelerated FedAvg algorithm in the FL setting: to the best of our knowledge, these are the first linear speedup guarantees for FedAvg when Nesterov acceleration is used. To accelerate FedAvg, we also design a new momentum-based FL algorithm that further improves the convergence rate in overparameterized linear regression problems. Empirical studies of the algorithms in various settings have supported our theoretical results.
Learning to Bid Optimally and Efficiently in Adversarial First-price Auctions
Jul 09, 2020
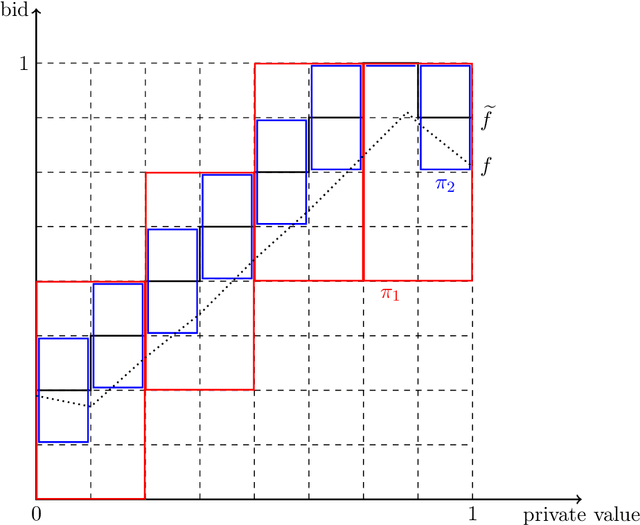
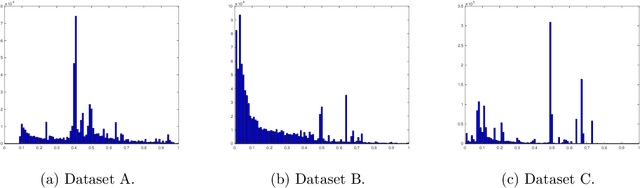
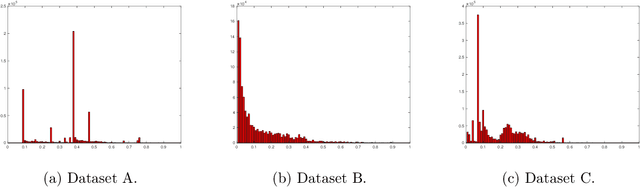
First-price auctions have very recently swept the online advertising industry, replacing second-price auctions as the predominant auction mechanism on many platforms. This shift has brought forth important challenges for a bidder: how should one bid in a first-price auction, where unlike in second-price auctions, it is no longer optimal to bid one's private value truthfully and hard to know the others' bidding behaviors? In this paper, we take an online learning angle and address the fundamental problem of learning to bid in repeated first-price auctions, where both the bidder's private valuations and other bidders' bids can be arbitrary. We develop the first minimax optimal online bidding algorithm that achieves an $\widetilde{O}(\sqrt{T})$ regret when competing with the set of all Lipschitz bidding policies, a strong oracle that contains a rich set of bidding strategies. This novel algorithm is built on the insight that the presence of a good expert can be leveraged to improve performance, as well as an original hierarchical expert-chaining structure, both of which could be of independent interest in online learning. Further, by exploiting the product structure that exists in the problem, we modify this algorithm--in its vanilla form statistically optimal but computationally infeasible--to a computationally efficient and space efficient algorithm that also retains the same $\widetilde{O}(\sqrt{T})$ minimax optimal regret guarantee. Additionally, through an impossibility result, we highlight that one is unlikely to compete this favorably with a stronger oracle (than the considered Lipschitz bidding policies). Finally, we test our algorithm on three real-world first-price auction datasets obtained from Verizon Media and demonstrate our algorithm's superior performance compared to several existing bidding algorithms.
Distributional Robust Batch Contextual Bandits
Jun 10, 2020
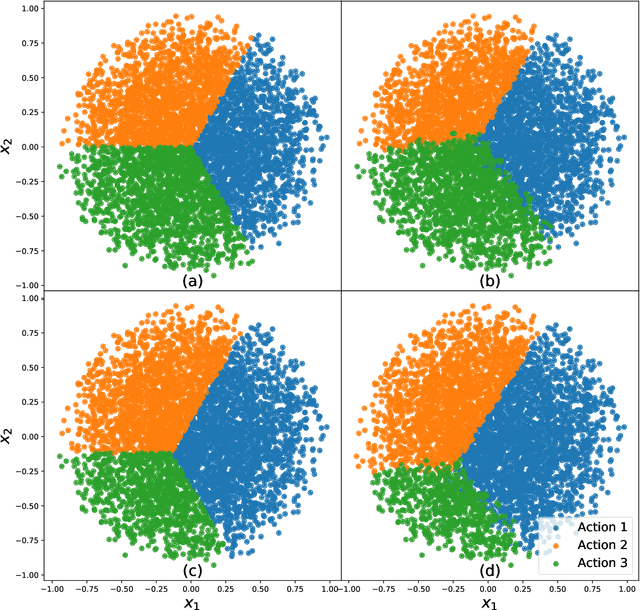
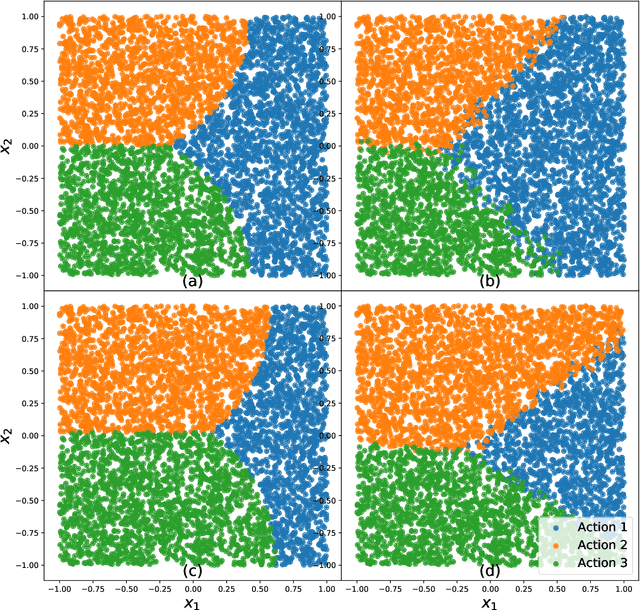
Policy learning using historical observational data is an important problem that has found widespread applications. Examples include selecting offers, prices, advertisements to send to customers, as well as selecting which medication to prescribe to a patient. However, existing literature rests on the crucial assumption that the future environment where the learned policy will be deployed is the same as the past environment that has generated the data--an assumption that is often false or too coarse an approximation. In this paper, we lift this assumption and aim to learn a distributional robust policy with incomplete (bandit) observational data. We propose a novel learning algorithm that is able to learn a robust policy to adversarial perturbations and unknown covariate shifts. We first present a policy evaluation procedure in the ambiguous environment and then give a performance guarantee based on the theory of uniform convergence. Additionally, we also give a heuristic algorithm to solve the distributional robust policy learning problems efficiently.