 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgepyvene: A Library for Understanding and Improving PyTorch Models via Interventions
Mar 12, 2024


Interventions on model-internal states are fundamental operations in many areas of AI, including model editing, steering, robustness, and interpretability. To facilitate such research, we introduce $\textbf{pyvene}$, an open-source Python library that supports customizable interventions on a range of different PyTorch modules. $\textbf{pyvene}$ supports complex intervention schemes with an intuitive configuration format, and its interventions can be static or include trainable parameters. We show how $\textbf{pyvene}$ provides a unified and extensible framework for performing interventions on neural models and sharing the intervened upon models with others. We illustrate the power of the library via interpretability analyses using causal abstraction and knowledge localization. We publish our library through Python Package Index (PyPI) and provide code, documentation, and tutorials at https://github.com/stanfordnlp/pyvene.
RAVEL: Evaluating Interpretability Methods on Disentangling Language Model Representations
Feb 27, 2024



Individual neurons participate in the representation of multiple high-level concepts. To what extent can different interpretability methods successfully disentangle these roles? To help address this question, we introduce RAVEL (Resolving Attribute-Value Entanglements in Language Models), a dataset that enables tightly controlled, quantitative comparisons between a variety of existing interpretability methods. We use the resulting conceptual framework to define the new method of Multi-task Distributed Alignment Search (MDAS), which allows us to find distributed representations satisfying multiple causal criteria. With Llama2-7B as the target language model, MDAS achieves state-of-the-art results on RAVEL, demonstrating the importance of going beyond neuron-level analyses to identify features distributed across activations. We release our benchmark at https://github.com/explanare/ravel.
A Reply to Makelov et al. 's "Interpretability Illusion" Arguments
Jan 23, 2024We respond to the recent paper by Makelov et al. (2023), which reviews subspace interchange intervention methods like distributed alignment search (DAS; Geiger et al. 2023) and claims that these methods potentially cause "interpretability illusions". We first review Makelov et al. (2023)'s technical notion of what an "interpretability illusion" is, and then we show that even intuitive and desirable explanations can qualify as illusions in this sense. As a result, their method of discovering "illusions" can reject explanations they consider "non-illusory". We then argue that the illusions Makelov et al. (2023) see in practice are artifacts of their training and evaluation paradigms. We close by emphasizing that, though we disagree with their core characterization, Makelov et al. (2023)'s examples and discussion have undoubtedly pushed the field of interpretability forward.
Rigorously Assessing Natural Language Explanations of Neurons
Sep 19, 2023Natural language is an appealing medium for explaining how large language models process and store information, but evaluating the faithfulness of such explanations is challenging. To help address this, we develop two modes of evaluation for natural language explanations that claim individual neurons represent a concept in a text input. In the observational mode, we evaluate claims that a neuron $a$ activates on all and only input strings that refer to a concept picked out by the proposed explanation $E$. In the intervention mode, we construe $E$ as a claim that the neuron $a$ is a causal mediator of the concept denoted by $E$. We apply our framework to the GPT-4-generated explanations of GPT-2 XL neurons of Bills et al. (2023) and show that even the most confident explanations have high error rates and little to no causal efficacy. We close the paper by critically assessing whether natural language is a good choice for explanations and whether neurons are the best level of analysis.
MQuAKE: Assessing Knowledge Editing in Language Models via Multi-Hop Questions
May 24, 2023The information stored in large language models (LLMs) falls out of date quickly, and retraining from scratch is often not an option. This has recently given rise to a range of techniques for injecting new facts through updating model weights. Current evaluation paradigms are extremely limited, mainly validating the recall of edited facts, but changing one fact should cause rippling changes to the model's related beliefs. If we edit the UK Prime Minister to now be Rishi Sunak, then we should get a different answer to Who is married to the British Prime Minister? In this work, we present a benchmark MQuAKE (Multi-hop Question Answering for Knowledge Editing) comprising multi-hop questions that assess whether edited models correctly answer questions where the answer should change as an entailed consequence of edited facts. While we find that current knowledge-editing approaches can recall edited facts accurately, they fail catastrophically on the constructed multi-hop questions. We thus propose a simple memory-based approach, MeLLo, which stores all edited facts externally while prompting the language model iteratively to generate answers that are consistent with the edited facts. While MQuAKE remains challenging, we show that MeLLo scales well with LLMs (up to 175B) and outperforms previous model editors by a large margin.
Interpretability at Scale: Identifying Causal Mechanisms in Alpaca
May 15, 2023



Obtaining human-interpretable explanations of large, general-purpose language models is an urgent goal for AI safety. However, it is just as important that our interpretability methods are faithful to the causal dynamics underlying model behavior and able to robustly generalize to unseen inputs. Distributed Alignment Search (DAS) is a powerful gradient descent method grounded in a theory of causal abstraction that uncovered perfect alignments between interpretable symbolic algorithms and small deep learning models fine-tuned for specific tasks. In the present paper, we scale DAS significantly by replacing the remaining brute-force search steps with learned parameters -- an approach we call DAS. This enables us to efficiently search for interpretable causal structure in large language models while they follow instructions. We apply DAS to the Alpaca model (7B parameters), which, off the shelf, solves a simple numerical reasoning problem. With DAS, we discover that Alpaca does this by implementing a causal model with two interpretable boolean variables. Furthermore, we find that the alignment of neural representations with these variables is robust to changes in inputs and instructions. These findings mark a first step toward deeply understanding the inner-workings of our largest and most widely deployed language models.
ReCOGS: How Incidental Details of a Logical Form Overshadow an Evaluation of Semantic Interpretation
Mar 24, 2023Compositional generalization benchmarks seek to assess whether models can accurately compute meanings for novel sentences, but operationalize this in terms of logical form (LF) prediction. This raises the concern that semantically irrelevant details of the chosen LFs could shape model performance. We argue that this concern is realized for the COGS benchmark (Kim and Linzen, 2020). COGS poses generalization splits that appear impossible for present-day models, which could be taken as an indictment of those models. However, we show that the negative results trace to incidental features of COGS LFs. Converting these LFs to semantically equivalent ones and factoring out capabilities unrelated to semantic interpretation, we find that even baseline models get traction. A recent variable-free translation of COGS LFs suggests similar conclusions, but we observe this format is not semantically equivalent; it is incapable of accurately representing some COGS meanings. These findings inform our proposal for ReCOGS, a modified version of COGS that comes closer to assessing the target semantic capabilities while remaining very challenging. Overall, our results reaffirm the importance of compositional generalization and careful benchmark task design.
Finding Alignments Between Interpretable Causal Variables and Distributed Neural Representations
Mar 05, 2023Causal abstraction is a promising theoretical framework for explainable artificial intelligence that defines when an interpretable high-level causal model is a faithful simplification of a low-level deep learning system. However, existing causal abstraction methods have two major limitations: they require a brute-force search over alignments between the high-level model and the low-level one, and they presuppose that variables in the high-level model will align with disjoint sets of neurons in the low-level one. In this paper, we present distributed alignment search (DAS), which overcomes these limitations. In DAS, we find the alignment between high-level and low-level models using gradient descent rather than conducting a brute-force search, and we allow individual neurons to play multiple distinct roles by analyzing representations in non-standard bases-distributed representations. Our experiments show that DAS can discover internal structure that prior approaches miss. Overall, DAS removes previous obstacles to conducting causal abstraction analyses and allows us to find conceptual structure in trained neural nets.
Inducing Character-level Structure in Subword-based Language Models with Type-level Interchange Intervention Training
Dec 19, 2022Language tasks involving character-level manipulations (e.g., spelling correction, many word games) are challenging for models based in subword tokenization. To address this, we adapt the interchange intervention training method of Geiger et al. (2021) to operate on type-level variables over characters. This allows us to encode robust, position-independent character-level information in the internal representations of subword-based models. We additionally introduce a suite of character-level tasks that systematically vary in their dependence on meaning and sequence-level context. While simple character-level tokenization approaches still perform best on purely form-based tasks like string reversal, our method is superior for more complex tasks that blend form, meaning, and context, such as spelling correction in context and word search games. Our approach also leads to subword-based models with human-intepretable internal representations of characters.
Causal Proxy Models for Concept-Based Model Explanations
Sep 28, 2022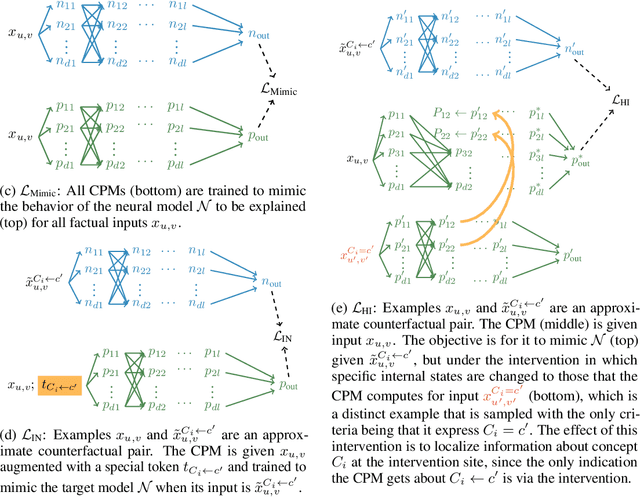
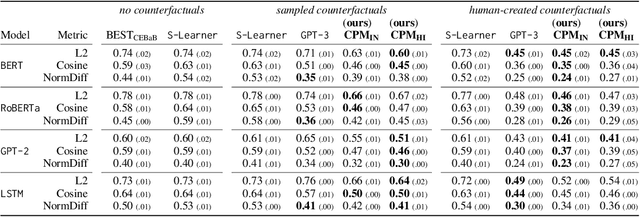

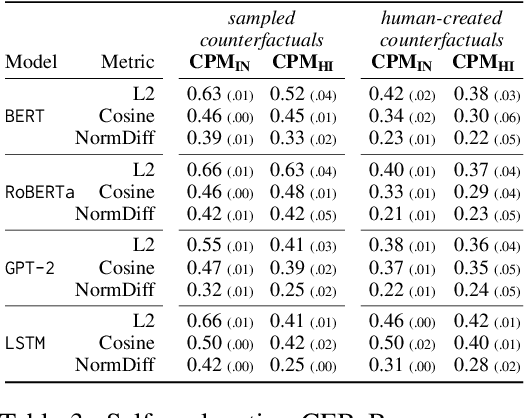
Explainability methods for NLP systems encounter a version of the fundamental problem of causal inference: for a given ground-truth input text, we never truly observe the counterfactual texts necessary for isolating the causal effects of model representations on outputs. In response, many explainability methods make no use of counterfactual texts, assuming they will be unavailable. In this paper, we show that robust causal explainability methods can be created using approximate counterfactuals, which can be written by humans to approximate a specific counterfactual or simply sampled using metadata-guided heuristics. The core of our proposal is the Causal Proxy Model (CPM). A CPM explains a black-box model $\mathcal{N}$ because it is trained to have the same actual input/output behavior as $\mathcal{N}$ while creating neural representations that can be intervened upon to simulate the counterfactual input/output behavior of $\mathcal{N}$. Furthermore, we show that the best CPM for $\mathcal{N}$ performs comparably to $\mathcal{N}$ in making factual predictions, which means that the CPM can simply replace $\mathcal{N}$, leading to more explainable deployed models. Our code is available at https://github.com/frankaging/Causal-Proxy-Model.