 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents of Chaos
Feb 23, 2026We report an exploratory red-teaming study of autonomous language-model-powered agents deployed in a live laboratory environment with persistent memory, email accounts, Discord access, file systems, and shell execution. Over a two-week period, twenty AI researchers interacted with the agents under benign and adversarial conditions. Focusing on failures emerging from the integration of language models with autonomy, tool use, and multi-party communication, we document eleven representative case studies. Observed behaviors include unauthorized compliance with non-owners, disclosure of sensitive information, execution of destructive system-level actions, denial-of-service conditions, uncontrolled resource consumption, identity spoofing vulnerabilities, cross-agent propagation of unsafe practices, and partial system takeover. In several cases, agents reported task completion while the underlying system state contradicted those reports. We also report on some of the failed attempts. Our findings establish the existence of security-, privacy-, and governance-relevant vulnerabilities in realistic deployment settings. These behaviors raise unresolved questions regarding accountability, delegated authority, and responsibility for downstream harms, and warrant urgent attention from legal scholars, policymakers, and researchers across disciplines. This report serves as an initial empirical contribution to that broader conversation.
Surgical Activation Steering via Generative Causal Mediation
Feb 17, 2026Where should we intervene in a language model (LM) to control behaviors that are diffused across many tokens of a long-form response? We introduce Generative Causal Mediation (GCM), a procedure for selecting model components, e.g., attention heads, to steer a binary concept (e.g., talk in verse vs. talk in prose) from contrastive long-form responses. In GCM, we first construct a dataset of contrasting inputs and responses. Then, we quantify how individual model components mediate the contrastive concept and select the strongest mediators for steering. We evaluate GCM on three tasks--refusal, sycophancy, and style transfer--across three language models. GCM successfully localizes concepts expressed in long-form responses and consistently outperforms correlational probe-based baselines when steering with a sparse set of attention heads. Together, these results demonstrate that GCM provides an effective approach for localizing and controlling the long-form responses of LMs.
Are language models aware of the road not taken? Token-level uncertainty and hidden state dynamics
Nov 06, 2025When a language model generates text, the selection of individual tokens might lead it down very different reasoning paths, making uncertainty difficult to quantify. In this work, we consider whether reasoning language models represent the alternate paths that they could take during generation. To test this hypothesis, we use hidden activations to control and predict a language model's uncertainty during chain-of-thought reasoning. In our experiments, we find a clear correlation between how uncertain a model is at different tokens, and how easily the model can be steered by controlling its activations. This suggests that activation interventions are most effective when there are alternate paths available to the model -- in other words, when it has not yet committed to a particular final answer. We also find that hidden activations can predict a model's future outcome distribution, demonstrating that models implicitly represent the space of possible paths.
MIB: A Mechanistic Interpretability Benchmark
Apr 17, 2025



How can we know whether new mechanistic interpretability methods achieve real improvements? In pursuit of meaningful and lasting evaluation standards, we propose MIB, a benchmark with two tracks spanning four tasks and five models. MIB favors methods that precisely and concisely recover relevant causal pathways or specific causal variables in neural language models. The circuit localization track compares methods that locate the model components - and connections between them - most important for performing a task (e.g., attribution patching or information flow routes). The causal variable localization track compares methods that featurize a hidden vector, e.g., sparse autoencoders (SAEs) or distributed alignment search (DAS), and locate model features for a causal variable relevant to the task. Using MIB, we find that attribution and mask optimization methods perform best on circuit localization. For causal variable localization, we find that the supervised DAS method performs best, while SAE features are not better than neurons, i.e., standard dimensions of hidden vectors. These findings illustrate that MIB enables meaningful comparisons of methods, and increases our confidence that there has been real progress in the field.
Updating CLIP to Prefer Descriptions Over Captions
Jun 12, 2024Although CLIPScore is a powerful generic metric that captures the similarity between a text and an image, it fails to distinguish between a caption that is meant to complement the information in an image and a description that is meant to replace an image entirely, e.g., for accessibility. We address this shortcoming by updating the CLIP model with the Concadia dataset to assign higher scores to descriptions than captions using parameter efficient fine-tuning and a loss objective derived from work on causal interpretability. This model correlates with the judgements of blind and low-vision people while preserving transfer capabilities and has interpretable structure that sheds light on the caption--description distinction.
Causal Proxy Models for Concept-Based Model Explanations
Sep 28, 2022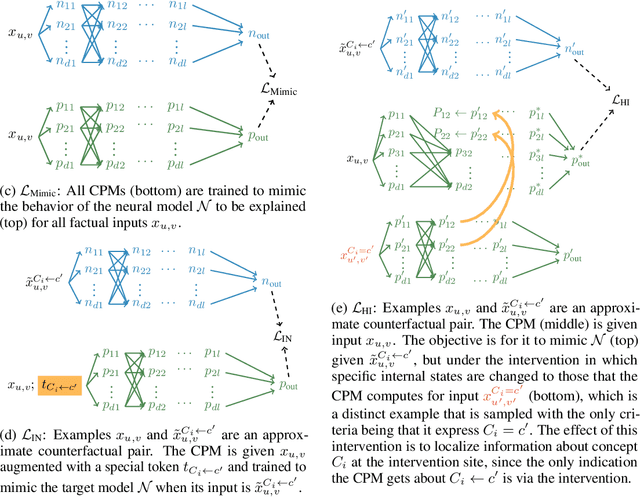
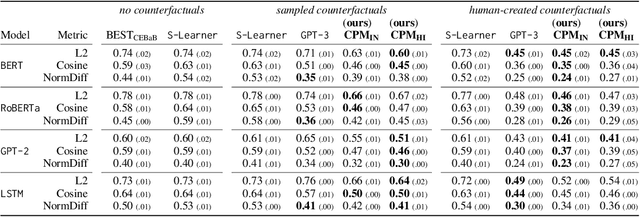

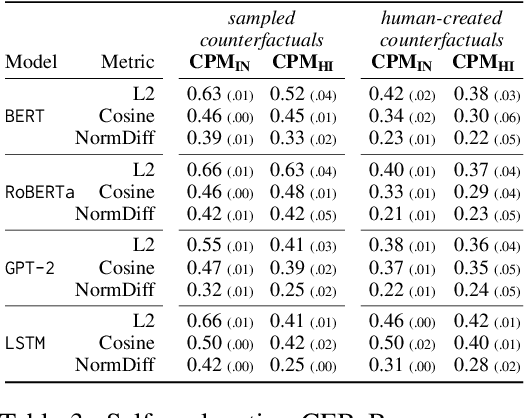
Explainability methods for NLP systems encounter a version of the fundamental problem of causal inference: for a given ground-truth input text, we never truly observe the counterfactual texts necessary for isolating the causal effects of model representations on outputs. In response, many explainability methods make no use of counterfactual texts, assuming they will be unavailable. In this paper, we show that robust causal explainability methods can be created using approximate counterfactuals, which can be written by humans to approximate a specific counterfactual or simply sampled using metadata-guided heuristics. The core of our proposal is the Causal Proxy Model (CPM). A CPM explains a black-box model $\mathcal{N}$ because it is trained to have the same actual input/output behavior as $\mathcal{N}$ while creating neural representations that can be intervened upon to simulate the counterfactual input/output behavior of $\mathcal{N}$. Furthermore, we show that the best CPM for $\mathcal{N}$ performs comparably to $\mathcal{N}$ in making factual predictions, which means that the CPM can simply replace $\mathcal{N}$, leading to more explainable deployed models. Our code is available at https://github.com/frankaging/Causal-Proxy-Model.