 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuseAnyPart: Diffusion-Driven Facial Parts Swapping via Multiple Reference Images
Oct 30, 2024Facial parts swapping aims to selectively transfer regions of interest from the source image onto the target image while maintaining the rest of the target image unchanged. Most studies on face swapping designed specifically for full-face swapping, are either unable or significantly limited when it comes to swapping individual facial parts, which hinders fine-grained and customized character designs. However, designing such an approach specifically for facial parts swapping is challenged by a reasonable multiple reference feature fusion, which needs to be both efficient and effective. To overcome this challenge, FuseAnyPart is proposed to facilitate the seamless "fuse-any-part" customization of the face. In FuseAnyPart, facial parts from different people are assembled into a complete face in latent space within the Mask-based Fusion Module. Subsequently, the consolidated feature is dispatched to the Addition-based Injection Module for fusion within the UNet of the diffusion model to create novel characters. Extensive experiments qualitatively and quantitatively validate the superiority and robustness of FuseAnyPart. Source codes are available at https://github.com/Thomas-wyh/FuseAnyPart.
How to Inverting the Leverage Score Distribution?
Apr 21, 2024Leverage score is a fundamental problem in machine learning and theoretical computer science. It has extensive applications in regression analysis, randomized algorithms, and neural network inversion. Despite leverage scores are widely used as a tool, in this paper, we study a novel problem, namely the inverting leverage score problem. We analyze to invert the leverage score distributions back to recover model parameters. Specifically, given a leverage score $\sigma \in \mathbb{R}^n$, the matrix $A \in \mathbb{R}^{n \times d}$, and the vector $b \in \mathbb{R}^n$, we analyze the non-convex optimization problem of finding $x \in \mathbb{R}^d$ to minimize $\| \mathrm{diag}( \sigma ) - I_n \circ (A(x) (A(x)^\top A(x) )^{-1} A(x)^\top ) \|_F$, where $A(x):= S(x)^{-1} A \in \mathbb{R}^{n \times d} $, $S(x) := \mathrm{diag}(s(x)) \in \mathbb{R}^{n \times n}$ and $s(x) : = Ax - b \in \mathbb{R}^n$. Our theoretical studies include computing the gradient and Hessian, demonstrating that the Hessian matrix is positive definite and Lipschitz, and constructing first-order and second-order algorithms to solve this regression problem. Our work combines iterative shrinking and the induction hypothesis to ensure global convergence rates for the Newton method, as well as the properties of Lipschitz and strong convexity to guarantee the performance of gradient descent. This important study on inverting statistical leverage opens up numerous new applications in interpretation, data recovery, and security.
VL-Mamba: Exploring State Space Models for Multimodal Learning
Mar 20, 2024



Multimodal large language models (MLLMs) have attracted widespread interest and have rich applications. However, the inherent attention mechanism in its Transformer structure requires quadratic complexity and results in expensive computational overhead. Therefore, in this work, we propose VL-Mamba, a multimodal large language model based on state space models, which have been shown to have great potential for long-sequence modeling with fast inference and linear scaling in sequence length. Specifically, we first replace the transformer-based backbone language model such as LLama or Vicuna with the pre-trained Mamba language model. Then, we empirically explore how to effectively apply the 2D vision selective scan mechanism for multimodal learning and the combinations of different vision encoders and variants of pretrained Mamba language models. The extensive experiments on diverse multimodal benchmarks with competitive performance show the effectiveness of our proposed VL-Mamba and demonstrate the great potential of applying state space models for multimodal learning tasks.
Deep Reinforcement Learning for Efficient and Fair Allocation of Health Care Resources
Sep 15, 2023



Scarcity of health care resources could result in the unavoidable consequence of rationing. For example, ventilators are often limited in supply, especially during public health emergencies or in resource-constrained health care settings, such as amid the pandemic of COVID-19. Currently, there is no universally accepted standard for health care resource allocation protocols, resulting in different governments prioritizing patients based on various criteria and heuristic-based protocols. In this study, we investigate the use of reinforcement learning for critical care resource allocation policy optimization to fairly and effectively ration resources. We propose a transformer-based deep Q-network to integrate the disease progression of individual patients and the interaction effects among patients during the critical care resource allocation. We aim to improve both fairness of allocation and overall patient outcomes. Our experiments demonstrate that our method significantly reduces excess deaths and achieves a more equitable distribution under different levels of ventilator shortage, when compared to existing severity-based and comorbidity-based methods in use by different governments. Our source code is included in the supplement and will be released on Github upon publication.
VLN-PETL: Parameter-Efficient Transfer Learning for Vision-and-Language Navigation
Aug 20, 2023The performance of the Vision-and-Language Navigation~(VLN) tasks has witnessed rapid progress recently thanks to the use of large pre-trained vision-and-language models. However, full fine-tuning the pre-trained model for every downstream VLN task is becoming costly due to the considerable model size. Recent research hotspot of Parameter-Efficient Transfer Learning (PETL) shows great potential in efficiently tuning large pre-trained models for the common CV and NLP tasks, which exploits the most of the representation knowledge implied in the pre-trained model while only tunes a minimal set of parameters. However, simply utilizing existing PETL methods for the more challenging VLN tasks may bring non-trivial degeneration to the performance. Therefore, we present the first study to explore PETL methods for VLN tasks and propose a VLN-specific PETL method named VLN-PETL. Specifically, we design two PETL modules: Historical Interaction Booster (HIB) and Cross-modal Interaction Booster (CIB). Then we combine these two modules with several existing PETL methods as the integrated VLN-PETL. Extensive experimental results on four mainstream VLN tasks (R2R, REVERIE, NDH, RxR) demonstrate the effectiveness of our proposed VLN-PETL, where VLN-PETL achieves comparable or even better performance to full fine-tuning and outperforms other PETL methods with promising margins.
March in Chat: Interactive Prompting for Remote Embodied Referring Expression
Aug 20, 2023



Many Vision-and-Language Navigation (VLN) tasks have been proposed in recent years, from room-based to object-based and indoor to outdoor. The REVERIE (Remote Embodied Referring Expression) is interesting since it only provides high-level instructions to the agent, which are closer to human commands in practice. Nevertheless, this poses more challenges than other VLN tasks since it requires agents to infer a navigation plan only based on a short instruction. Large Language Models (LLMs) show great potential in robot action planning by providing proper prompts. Still, this strategy has not been explored under the REVERIE settings. There are several new challenges. For example, the LLM should be environment-aware so that the navigation plan can be adjusted based on the current visual observation. Moreover, the LLM planned actions should be adaptable to the much larger and more complex REVERIE environment. This paper proposes a March-in-Chat (MiC) model that can talk to the LLM on the fly and plan dynamically based on a newly proposed Room-and-Object Aware Scene Perceiver (ROASP). Our MiC model outperforms the previous state-of-the-art by large margins by SPL and RGSPL metrics on the REVERIE benchmark.
Deep Reinforcement Learning for Cost-Effective Medical Diagnosis
Feb 28, 2023Dynamic diagnosis is desirable when medical tests are costly or time-consuming. In this work, we use reinforcement learning (RL) to find a dynamic policy that selects lab test panels sequentially based on previous observations, ensuring accurate testing at a low cost. Clinical diagnostic data are often highly imbalanced; therefore, we aim to maximize the $F_1$ score instead of the error rate. However, optimizing the non-concave $F_1$ score is not a classic RL problem, thus invalidates standard RL methods. To remedy this issue, we develop a reward shaping approach, leveraging properties of the $F_1$ score and duality of policy optimization, to provably find the set of all Pareto-optimal policies for budget-constrained $F_1$ score maximization. To handle the combinatorially complex state space, we propose a Semi-Model-based Deep Diagnosis Policy Optimization (SM-DDPO) framework that is compatible with end-to-end training and online learning. SM-DDPO is tested on diverse clinical tasks: ferritin abnormality detection, sepsis mortality prediction, and acute kidney injury diagnosis. Experiments with real-world data validate that SM-DDPO trains efficiently and identifies all Pareto-front solutions. Across all tasks, SM-DDPO is able to achieve state-of-the-art diagnosis accuracy (in some cases higher than conventional methods) with up to $85\%$ reduction in testing cost. The code is available at [https://github.com/Zheng321/Deep-Reinforcement-Learning-for-Cost-Effective-Medical-Diagnosis].
Sketching for First Order Method: Efficient Algorithm for Low-Bandwidth Channel and Vulnerability
Oct 15, 2022
Sketching is one of the most fundamental tools in large-scale machine learning. It enables runtime and memory saving via randomly compressing the original large problem onto lower dimensions. In this paper, we propose a novel sketching scheme for the first order method in large-scale distributed learning setting, such that the communication costs between distributed agents are saved while the convergence of the algorithms is still guaranteed. Given gradient information in a high dimension $d$, the agent passes the compressed information processed by a sketching matrix $R\in \R^{s\times d}$ with $s\ll d$, and the receiver de-compressed via the de-sketching matrix $R^\top$ to ``recover'' the information in original dimension. Using such a framework, we develop algorithms for federated learning with lower communication costs. However, such random sketching does not protect the privacy of local data directly. We show that the gradient leakage problem still exists after applying the sketching technique by showing a specific gradient attack method. As a remedy, we prove rigorously that the algorithm will be differentially private by adding additional random noises in gradient information, which results in a both communication-efficient and differentially private first order approach for federated learning tasks. Our sketching scheme can be further generalized to other learning settings and might be of independent interest itself.
HOP: History-and-Order Aware Pre-training for Vision-and-Language Navigation
Mar 22, 2022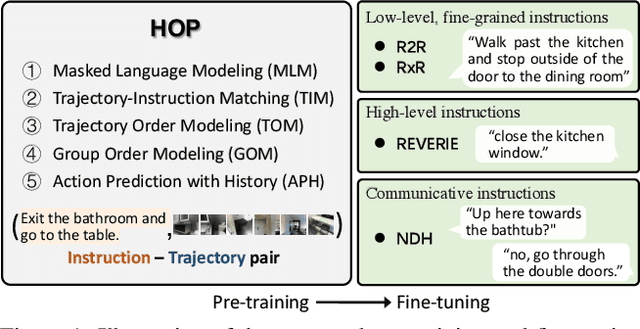
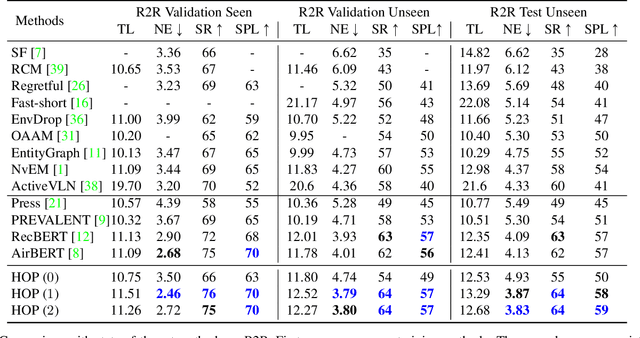
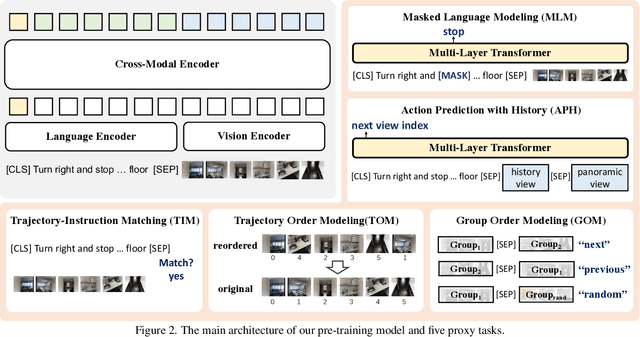
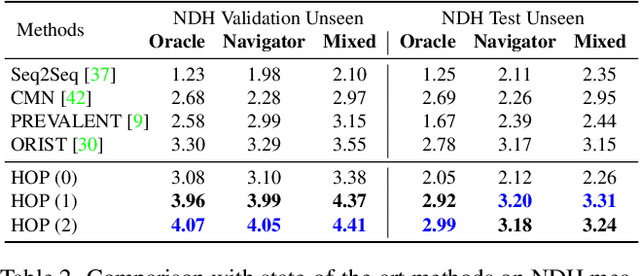
Pre-training has been adopted in a few of recent works for Vision-and-Language Navigation (VLN). However, previous pre-training methods for VLN either lack the ability to predict future actions or ignore the trajectory contexts, which are essential for a greedy navigation process. In this work, to promote the learning of spatio-temporal visual-textual correspondence as well as the agent's capability of decision making, we propose a novel history-and-order aware pre-training paradigm (HOP) with VLN-specific objectives that exploit the past observations and support future action prediction. Specifically, in addition to the commonly used Masked Language Modeling (MLM) and Trajectory-Instruction Matching (TIM), we design two proxy tasks to model temporal order information: Trajectory Order Modeling (TOM) and Group Order Modeling (GOM). Moreover, our navigation action prediction is also enhanced by introducing the task of Action Prediction with History (APH), which takes into account the history visual perceptions. Extensive experimental results on four downstream VLN tasks (R2R, REVERIE, NDH, RxR) demonstrate the effectiveness of our proposed method compared against several state-of-the-art agents.
Fast Graph Neural Tangent Kernel via Kronecker Sketching
Dec 04, 2021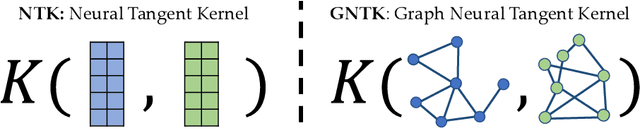

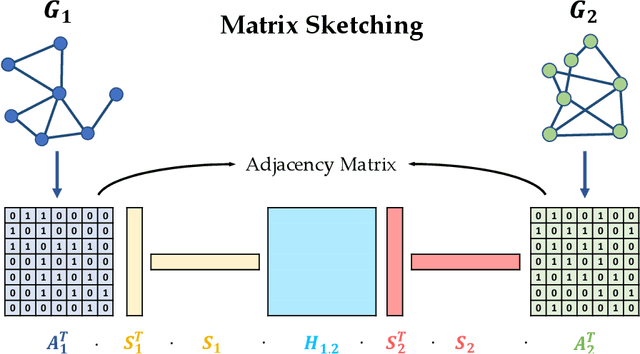
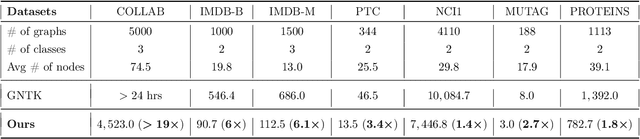
Many deep learning tasks have to deal with graphs (e.g., protein structures, social networks, source code abstract syntax trees). Due to the importance of these tasks, people turned to Graph Neural Networks (GNNs) as the de facto method for learning on graphs. GNNs have become widely applied due to their convincing performance. Unfortunately, one major barrier to using GNNs is that GNNs require substantial time and resources to train. Recently, a new method for learning on graph data is Graph Neural Tangent Kernel (GNTK) [Du, Hou, Salakhutdinov, Poczos, Wang and Xu 19]. GNTK is an application of Neural Tangent Kernel (NTK) [Jacot, Gabriel and Hongler 18] (a kernel method) on graph data, and solving NTK regression is equivalent to using gradient descent to train an infinite-wide neural network. The key benefit of using GNTK is that, similar to any kernel method, GNTK's parameters can be solved directly in a single step. This can avoid time-consuming gradient descent. Meanwhile, sketching has become increasingly used in speeding up various optimization problems, including solving kernel regression. Given a kernel matrix of $n$ graphs, using sketching in solving kernel regression can reduce the running time to $o(n^3)$. But unfortunately such methods usually require extensive knowledge about the kernel matrix beforehand, while in the case of GNTK we find that the construction of the kernel matrix is already $O(n^2N^4)$, assuming each graph has $N$ nodes. The kernel matrix construction time can be a major performance bottleneck when the size of graphs $N$ increases. A natural question to ask is thus whether we can speed up the kernel matrix construction to improve GNTK regression's end-to-end running time. This paper provides the first algorithm to construct the kernel matrix in $o(n^2N^3)$ running time.