 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerahertz Channels in Atmospheric Conditions: Propagation Characteristics and Security Performance
Aug 28, 2024



With the growing demand for higher wireless data rates, the interest in extending the carrier frequency of wireless links to the terahertz (THz) range has significantly increased. For long-distance outdoor wireless communications, THz channels may suffer substantial power loss and security issues due to atmospheric weather effects. It is crucial to assess the impact of weather on high-capacity data transmission to evaluate wireless system link budgets and performance accurately. In this article, we provide an insight into the propagation characteristics of THz channels under atmospheric conditions and the security aspects of THz communication systems in future applications. We conduct a comprehensive survey of our recent research and experimental findings on THz channel transmission and physical layer security, synthesizing and categorizing the state-of-the-art research in this domain. Our analysis encompasses various atmospheric phenomena, including molecular absorption, scattering effects, and turbulence, elucidating their intricate interactions with THz waves and the resultant implications for channel modeling and system design. Furthermore, we investigate the unique security challenges posed by THz communications, examining potential vulnerabilities and proposing novel countermeasures to enhance the resilience of these high-frequency systems against eavesdropping and other security threats. Finally, we discuss the challenges and limitations of such high-frequency wireless communications and provide insights into future research prospects for realizing the 6G vision, emphasizing the need for innovative solutions to overcome the atmospheric hurdles and security concerns in THz communications.
Terahertz channel modeling based on surface sensing characteristics
Apr 03, 2024



The dielectric properties of environmental surfaces, including walls, floors and the ground, etc., play a crucial role in shaping the accuracy of terahertz (THz) channel modeling, thereby directly impacting the effectiveness of communication systems. Traditionally, acquiring these properties has relied on methods such as terahertz time-domain spectroscopy (THz-TDS) or vector network analyzers (VNA), demanding rigorous sample preparation and entailing a significant expenditure of time. However, such measurements are not always feasible, particularly in novel and uncharacterized scenarios. In this work, we propose a new approach for channel modeling that leverages the inherent sensing capabilities of THz channels. By comparing the results obtained through channel sensing with that derived from THz-TDS measurements, we demonstrate the method's ability to yield dependable surface property information. The application of this approach in both a miniaturized cityscape scenario and an indoor environment has shown consistency with experimental measurements, thereby verifying its effectiveness in real-world settings.
Ground-to-UAV 140 GHz channel measurement and modeling
Apr 03, 2024



Unmanned Aerial Vehicle (UAV) assisted terahertz (THz) wireless communications have been expected to play a vital role in the next generation of wireless networks. UAVs can serve as either repeaters or data collectors within the communication link, thereby potentially augmenting the efficacy of communication systems. Despite their promise, the channel analysis and modeling specific to THz wireless channels leveraging UAVs remain under explored. This work delves into a ground-to-UAV channel at 140 GHz, with a specific focus on the influence of UAV hovering behavior on channel performance. Employing experimental measurements through an unmodulated channel setup and a geometry-based stochastic model (GBSM) that integrates three-dimensional positional coordinates and beamwidth, this work evaluates the impact of UAV dynamic movements and antenna orientation on channel performance. Our findings highlight the minimal impact of UAV orientation adjustments on channel performance and underscore the diminishing necessity for precise alignment between UAVs and ground stations as beamwidth increases.
Driving Scene Perception Network: Real-time Joint Detection, Depth Estimation and Semantic Segmentation
Mar 10, 2018

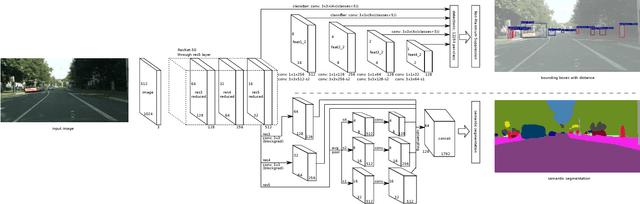

As the demand for enabling high-level autonomous driving has increased in recent years and visual perception is one of the critical features to enable fully autonomous driving, in this paper, we introduce an efficient approach for simultaneous object detection, depth estimation and pixel-level semantic segmentation using a shared convolutional architecture. The proposed network model, which we named Driving Scene Perception Network (DSPNet), uses multi-level feature maps and multi-task learning to improve the accuracy and efficiency of object detection, depth estimation and image segmentation tasks from a single input image. Hence, the resulting network model uses less than 850 MiB of GPU memory and achieves 14.0 fps on NVIDIA GeForce GTX 1080 with a 1024x512 input image, and both precision and efficiency have been improved over combination of single tasks.