 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Prototype Learning for Zero-Shot Recognition
Oct 24, 2019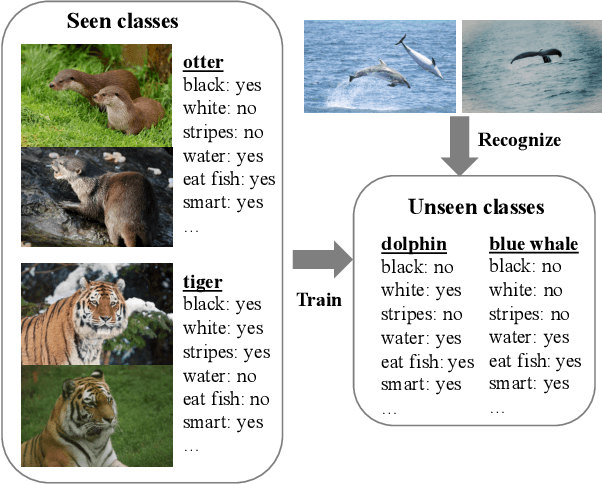

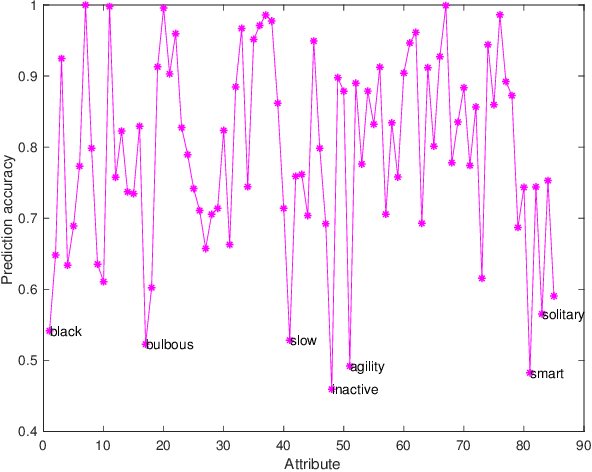
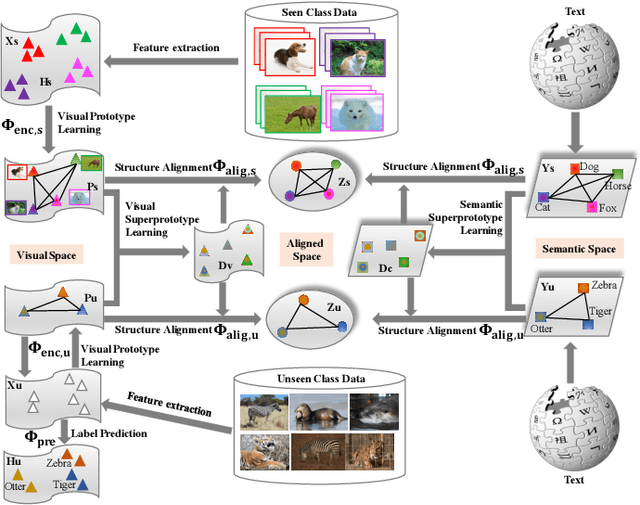
Zero-Shot Learning (ZSL) has received extensive attention and successes in recent years especially in areas of fine-grained object recognition, retrieval, and image captioning. Key to ZSL is to transfer knowledge from the seen to the unseen classes via auxiliary semantic prototypes (e.g., word or attribute vectors). However, the popularly learned projection functions in previous works cannot generalize well due to non-visual components included in semantic prototypes. Besides, the incompleteness of provided prototypes and captured images has less been considered by the state-of-the-art approaches in ZSL. In this paper, we propose a hierarchical prototype learning formulation to provide a systematical solution (named HPL) for zero-shot recognition. Specifically, HPL is able to obtain discriminability on both seen and unseen class domains by learning visual prototypes respectively under the transductive setting. To narrow the gap of two domains, we further learn the interpretable super-prototypes in both visual and semantic spaces. Meanwhile, the two spaces are further bridged by maximizing their structural consistency. This not only facilitates the representativeness of visual prototypes, but also alleviates the loss of information of semantic prototypes. An extensive group of experiments are then carefully designed and presented, demonstrating that HPL obtains remarkably more favorable efficiency and effectiveness, over currently available alternatives under various settings.
Convolutional Prototype Learning for Zero-Shot Recognition
Oct 24, 2019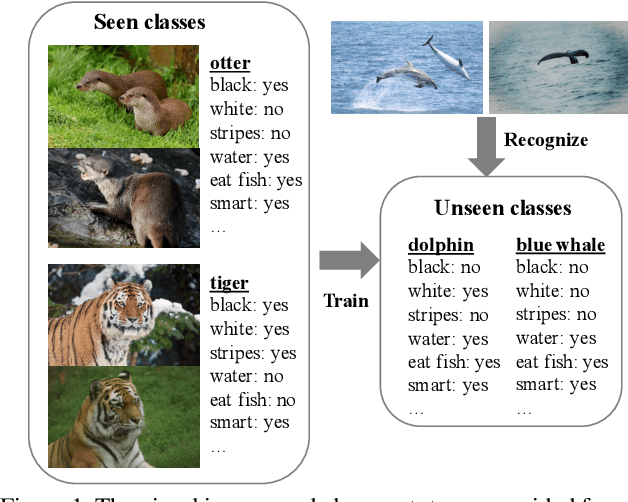


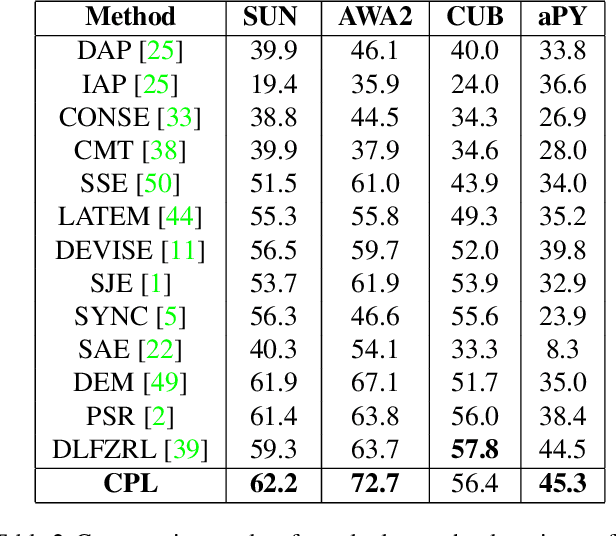
Zero-shot learning (ZSL) has received increasing attention in recent years especially in areas of fine-grained object recognition, retrieval, and image captioning. The key to ZSL is to transfer knowledge from the seen to the unseen classes via auxiliary class attribute vectors. However, the popularly learned projection functions in previous works cannot generalize well since they assume the distribution consistency between seen and unseen domains at sample-level.Besides, the provided non-visual and unique class attributes can significantly degrade the recognition performance in semantic space. In this paper, we propose a simple yet effective convolutional prototype learning (CPL) framework for zero-shot recognition. By assuming distribution consistency at task-level, our CPL is capable of transferring knowledge smoothly to recognize unseen samples.Furthermore, inside each task, discriminative visual prototypes are learned via a distance based training mechanism. Consequently, we can perform recognition in visual space, instead of semantic space. An extensive group of experiments are then carefully designed and presented, demonstrating that CPL obtains more favorable effectiveness, over currently available alternatives under various settings.
Edge Heuristic GAN for Non-uniform Blind Deblurring
Jul 11, 2019


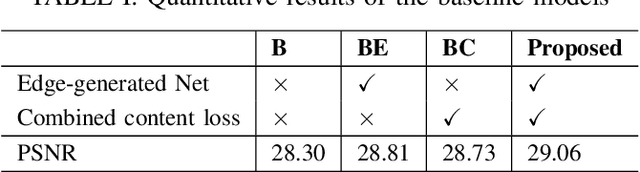
Non-uniform blur, mainly caused by camera shake and motions of multiple objects, is one of the most common causes of image quality degradation. However, the traditional blind deblurring methods based on blur kernel estimation do not perform well on complicated non-uniform motion blurs. Recent studies show that GAN-based approaches achieve impressive performance on deblurring tasks. In this letter, to further improve the performance of GAN-based methods on deblurring tasks, we propose an edge heuristic multi-scale generative adversarial network(GAN), which uses the "coarse-to-fine" scheme to restore clear images in an end-to-end manner. In particular, an edge-enhanced network is designed to generate sharp edges as auxiliary information to guide the deblurring process. Furthermore, We propose a hierarchical content loss function for deblurring tasks. Extensive experiments on different datasets show that our method achieves state-of-the-art performance in dynamic scene deblurring.
EA-LSTM: Evolutionary Attention-based LSTM for Time Series Prediction
Nov 09, 2018

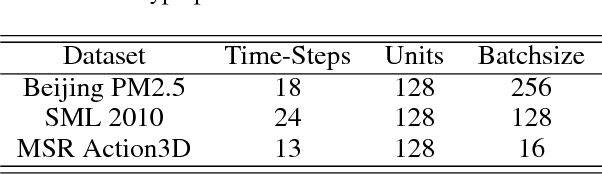
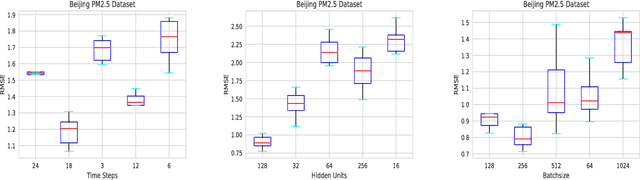
Time series prediction with deep learning methods, especially long short-term memory neural networks (LSTMs), have scored significant achievements in recent years. Despite the fact that the LSTMs can help to capture long-term dependencies, its ability to pay different degree of attention on sub-window feature within multiple time-steps is insufficient. To address this issue, an evolutionary attention-based LSTM training with competitive random search is proposed for multivariate time series prediction. By transferring shared parameters, an evolutionary attention learning approach is introduced to the LSTMs model. Thus, like that for biological evolution, the pattern for importance-based attention sampling can be confirmed during temporal relationship mining. To refrain from being trapped into partial optimization like traditional gradient-based methods, an evolutionary computation inspired competitive random search method is proposed, which can well configure the parameters in the attention layer. Experimental results have illustrated that the proposed model can achieve competetive prediction performance compared with other baseline methods.
Modality-dependent Cross-media Retrieval
Jun 23, 2015
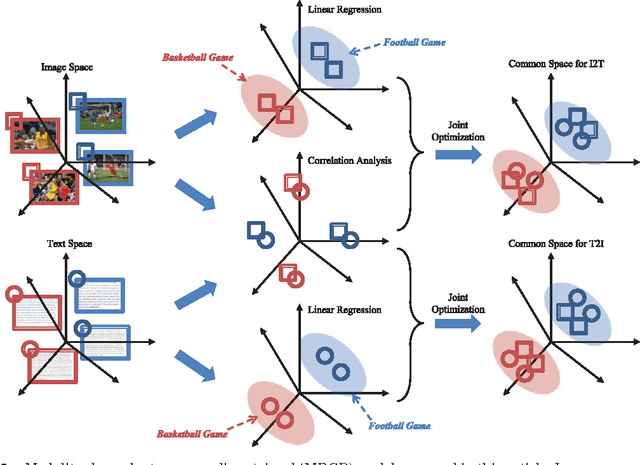
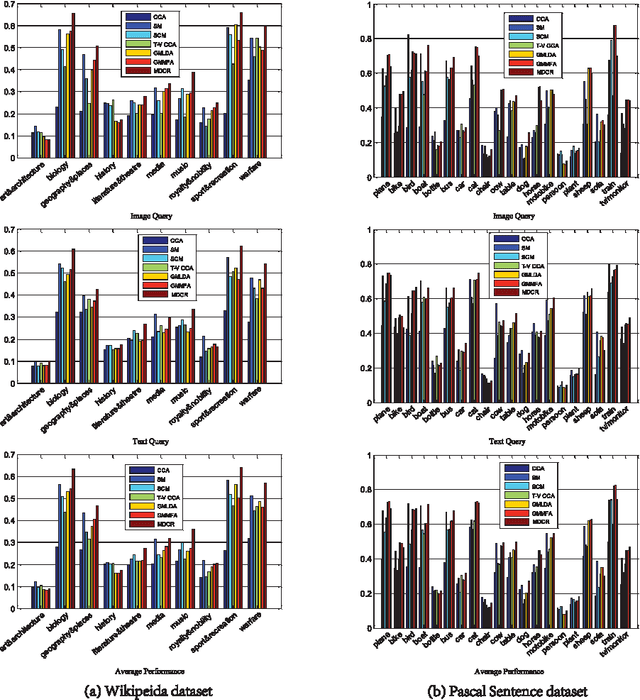

In this paper, we investigate the cross-media retrieval between images and text, i.e., using image to search text (I2T) and using text to search images (T2I). Existing cross-media retrieval methods usually learn one couple of projections, by which the original features of images and text can be projected into a common latent space to measure the content similarity. However, using the same projections for the two different retrieval tasks (I2T and T2I) may lead to a tradeoff between their respective performances, rather than their best performances. Different from previous works, we propose a modality-dependent cross-media retrieval (MDCR) model, where two couples of projections are learned for different cross-media retrieval tasks instead of one couple of projections. Specifically, by jointly optimizing the correlation between images and text and the linear regression from one modal space (image or text) to the semantic space, two couples of mappings are learned to project images and text from their original feature spaces into two common latent subspaces (one for I2T and the other for T2I). Extensive experiments show the superiority of the proposed MDCR compared with other methods. In particular, based the 4,096 dimensional convolutional neural network (CNN) visual feature and 100 dimensional LDA textual feature, the mAP of the proposed method achieves 41.5\%, which is a new state-of-the-art performance on the Wikipedia dataset.
Kernel Reconstruction ICA for Sparse Representation
Apr 09, 2013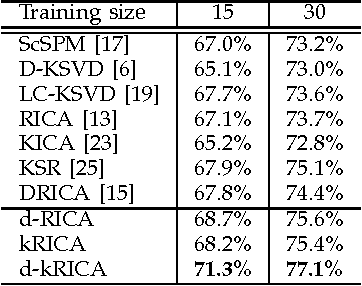
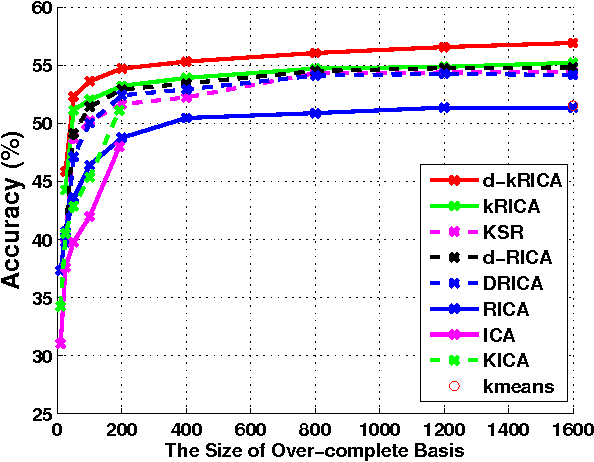
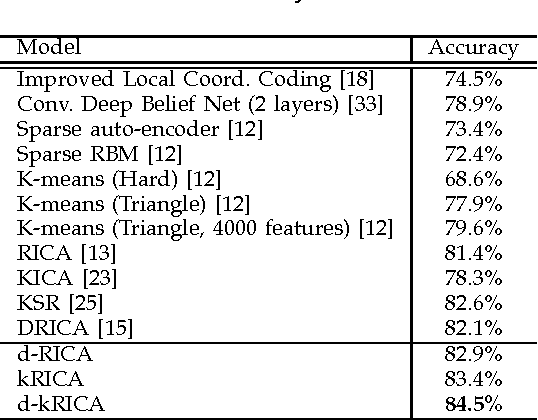
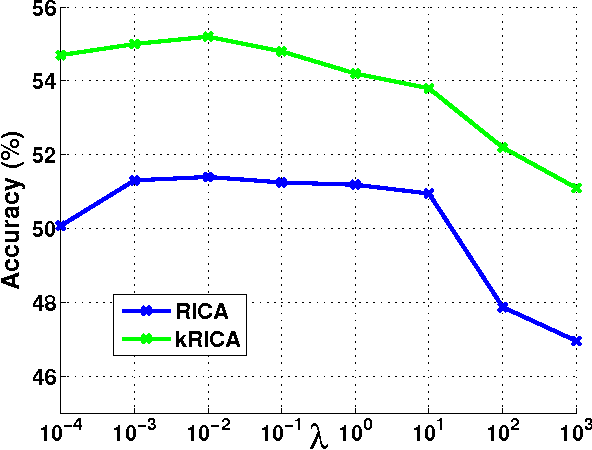
Independent Component Analysis (ICA) is an effective unsupervised tool to learn statistically independent representation. However, ICA is not only sensitive to whitening but also difficult to learn an over-complete basis. Consequently, ICA with soft Reconstruction cost(RICA) was presented to learn sparse representations with over-complete basis even on unwhitened data. Whereas RICA is infeasible to represent the data with nonlinear structure due to its intrinsic linearity. In addition, RICA is essentially an unsupervised method and can not utilize the class information. In this paper, we propose a kernel ICA model with reconstruction constraint (kRICA) to capture the nonlinear features. To bring in the class information, we further extend the unsupervised kRICA to a supervised one by introducing a discrimination constraint, namely d-kRICA. This constraint leads to learn a structured basis consisted of basis vectors from different basis subsets corresponding to different class labels. Then each subset will sparsely represent well for its own class but not for the others. Furthermore, data samples belonging to the same class will have similar representations, and thereby the learned sparse representations can take more discriminative power. Experimental results validate the effectiveness of kRICA and d-kRICA for image classification.