 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Fair Face Representation With Progressive Cross Transformer
Aug 11, 2021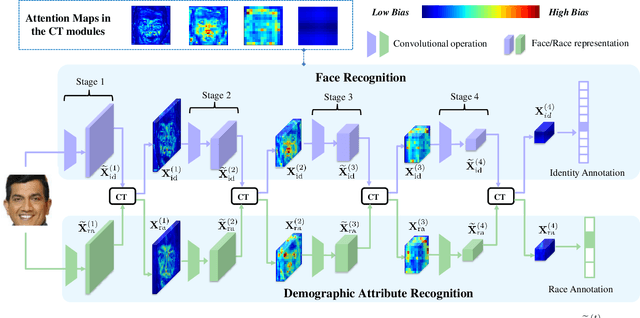
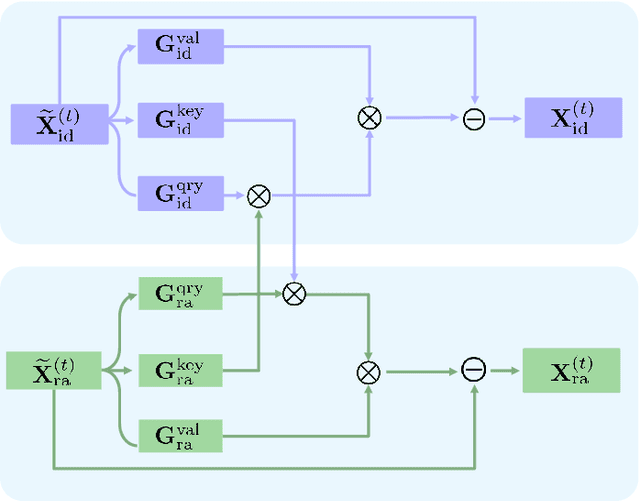
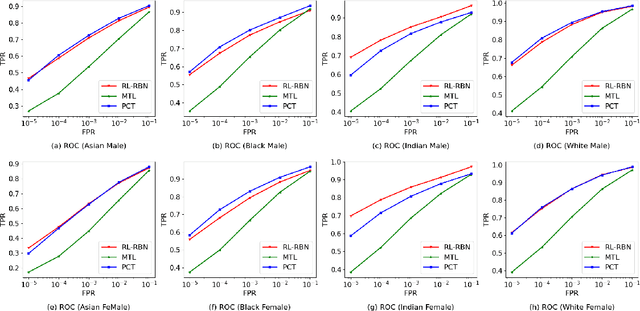
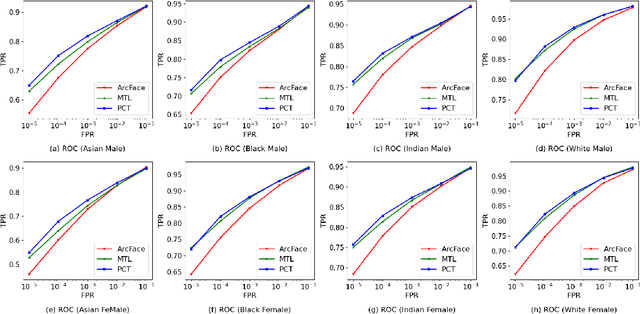
Face recognition (FR) has made extraordinary progress owing to the advancement of deep convolutional neural networks. However, demographic bias among different racial cohorts still challenges the practical face recognition system. The race factor has been proven to be a dilemma for fair FR (FFR) as the subject-related specific attributes induce the classification bias whilst carrying some useful cues for FR. To mitigate racial bias and meantime preserve robust FR, we abstract face identity-related representation as a signal denoising problem and propose a progressive cross transformer (PCT) method for fair face recognition. Originating from the signal decomposition theory, we attempt to decouple face representation into i) identity-related components and ii) noisy/identity-unrelated components induced by race. As an extension of signal subspace decomposition, we formulate face decoupling as a generalized functional expression model to cross-predict face identity and race information. The face expression model is further concretized by designing dual cross-transformers to distill identity-related components and suppress racial noises. In order to refine face representation, we take a progressive face decoupling way to learn identity/race-specific transformations, so that identity-unrelated components induced by race could be better disentangled. We evaluate the proposed PCT on the public fair face recognition benchmarks (BFW, RFW) and verify that PCT is capable of mitigating bias in face recognition while achieving state-of-the-art FR performance. Besides, visualization results also show that the attention maps in PCT can well reveal the race-related/biased facial regions.
Graph Jigsaw Learning for Cartoon Face Recognition
Jul 14, 2021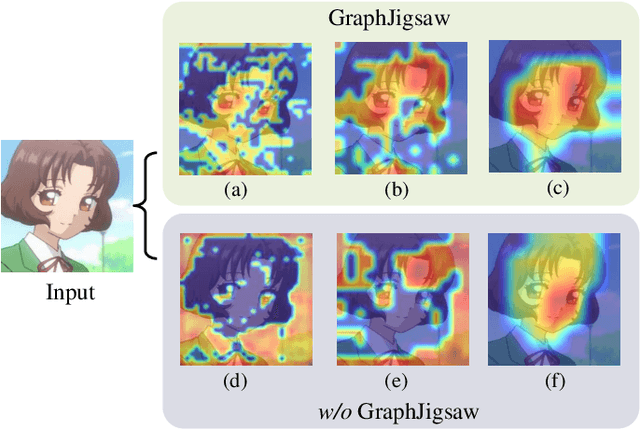
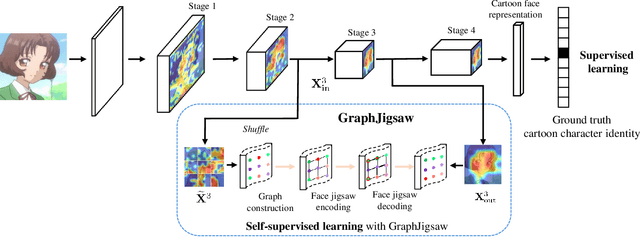
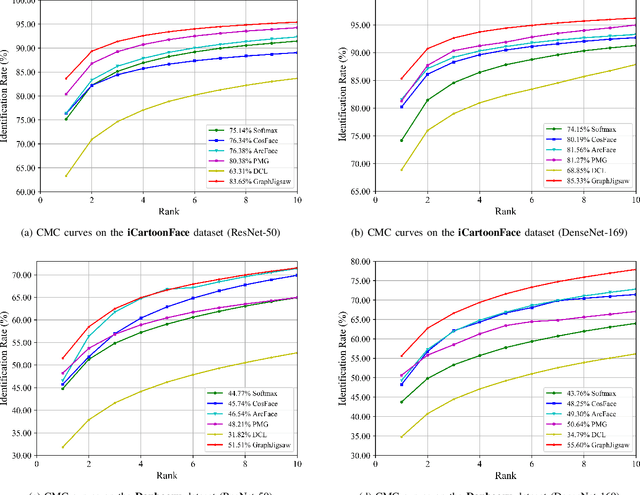

Cartoon face recognition is challenging as they typically have smooth color regions and emphasized edges, the key to recognize cartoon faces is to precisely perceive their sparse and critical shape patterns. However, it is quite difficult to learn a shape-oriented representation for cartoon face recognition with convolutional neural networks (CNNs). To mitigate this issue, we propose the GraphJigsaw that constructs jigsaw puzzles at various stages in the classification network and solves the puzzles with the graph convolutional network (GCN) in a progressive manner. Solving the puzzles requires the model to spot the shape patterns of the cartoon faces as the texture information is quite limited. The key idea of GraphJigsaw is constructing a jigsaw puzzle by randomly shuffling the intermediate convolutional feature maps in the spatial dimension and exploiting the GCN to reason and recover the correct layout of the jigsaw fragments in a self-supervised manner. The proposed GraphJigsaw avoids training the classification model with the deconstructed images that would introduce noisy patterns and are harmful for the final classification. Specially, GraphJigsaw can be incorporated at various stages in a top-down manner within the classification model, which facilitates propagating the learned shape patterns gradually. GraphJigsaw does not rely on any extra manual annotation during the training process and incorporates no extra computation burden at inference time. Both quantitative and qualitative experimental results have verified the feasibility of our proposed GraphJigsaw, which consistently outperforms other face recognition or jigsaw-based methods on two popular cartoon face datasets with considerable improvements.
Consistent Instance False Positive Improves Fairness in Face Recognition
Jun 10, 2021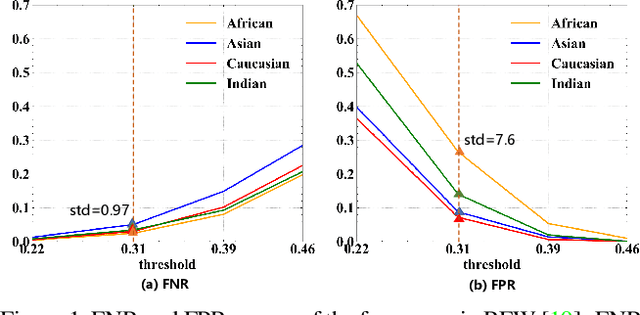
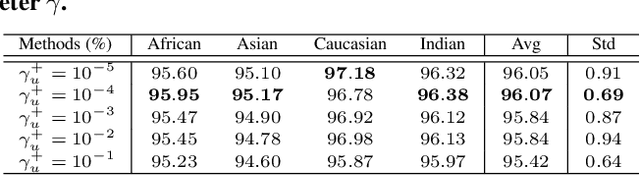
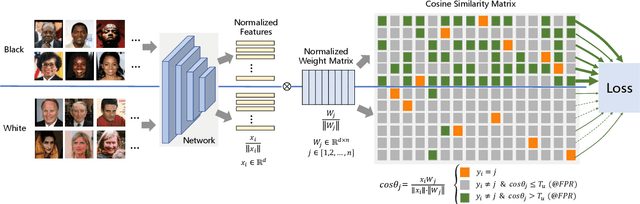
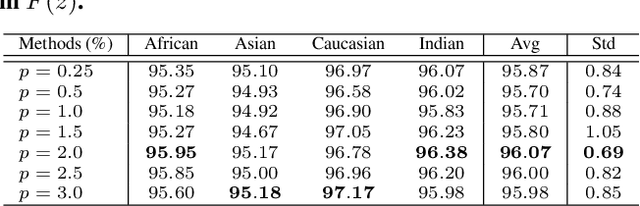
Demographic bias is a significant challenge in practical face recognition systems. Existing methods heavily rely on accurate demographic annotations. However, such annotations are usually unavailable in real scenarios. Moreover, these methods are typically designed for a specific demographic group and are not general enough. In this paper, we propose a false positive rate penalty loss, which mitigates face recognition bias by increasing the consistency of instance False Positive Rate (FPR). Specifically, we first define the instance FPR as the ratio between the number of the non-target similarities above a unified threshold and the total number of the non-target similarities. The unified threshold is estimated for a given total FPR. Then, an additional penalty term, which is in proportion to the ratio of instance FPR overall FPR, is introduced into the denominator of the softmax-based loss. The larger the instance FPR, the larger the penalty. By such unequal penalties, the instance FPRs are supposed to be consistent. Compared with the previous debiasing methods, our method requires no demographic annotations. Thus, it can mitigate the bias among demographic groups divided by various attributes, and these attributes are not needed to be previously predefined during training. Extensive experimental results on popular benchmarks demonstrate the superiority of our method over state-of-the-art competitors. Code and trained models are available at https://github.com/Tencent/TFace.
Learning Normal Dynamics in Videos with Meta Prototype Network
May 10, 2021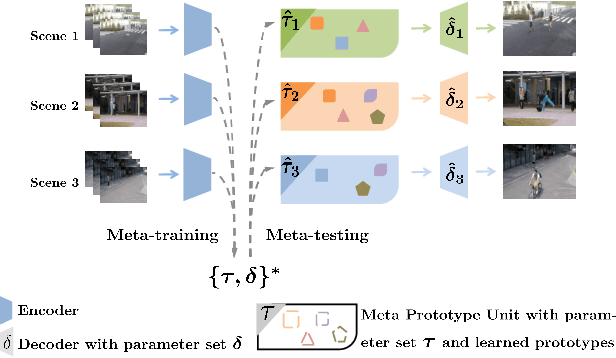
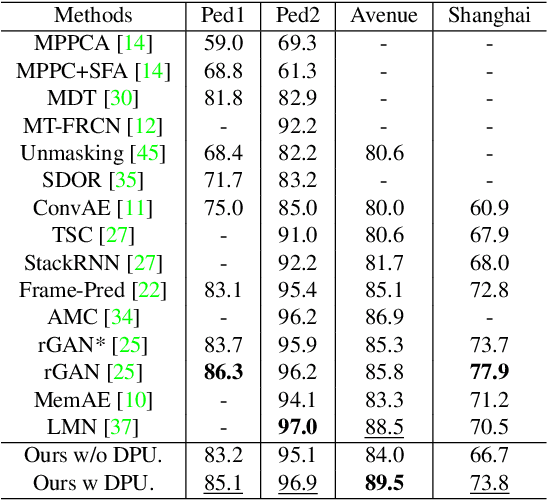
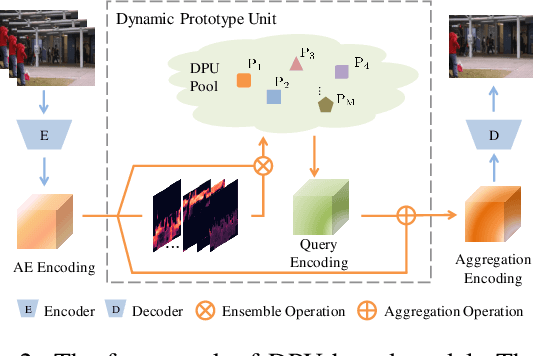
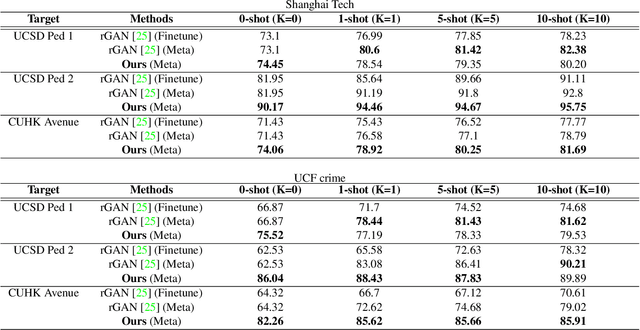
Frame reconstruction (current or future frame) based on Auto-Encoder (AE) is a popular method for video anomaly detection. With models trained on the normal data, the reconstruction errors of anomalous scenes are usually much larger than those of normal ones. Previous methods introduced the memory bank into AE, for encoding diverse normal patterns across the training videos. However, they are memory-consuming and cannot cope with unseen new scenarios in the testing data. In this work, we propose a dynamic prototype unit (DPU) to encode the normal dynamics as prototypes in real time, free from extra memory cost. In addition, we introduce meta-learning to our DPU to form a novel few-shot normalcy learner, namely Meta-Prototype Unit (MPU). It enables the fast adaption capability on new scenes by only consuming a few iterations of update. Extensive experiments are conducted on various benchmarks. The superior performance over the state-of-the-art demonstrates the effectiveness of our method.
Global Information Guided Video Anomaly Detection
Apr 14, 2021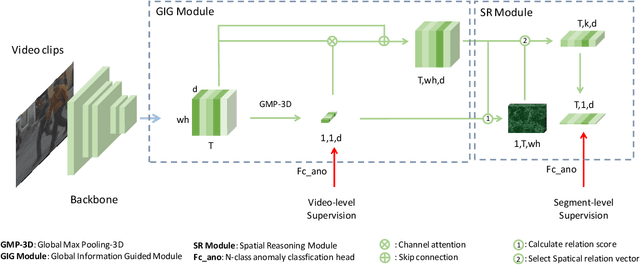
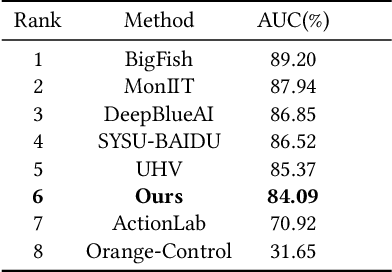
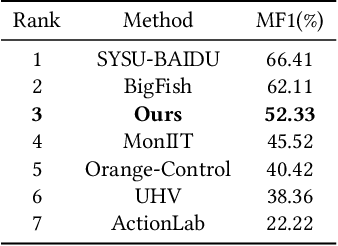
Video anomaly detection (VAD) is currently a challenging task due to the complexity of anomaly as well as the lack of labor-intensive temporal annotations. In this paper, we propose an end-to-end Global Information Guided (GIG) anomaly detection framework for anomaly detection using the video-level annotations (i.e., weak labels). We propose to first mine the global pattern cues by leveraging the weak labels in a GIG module. Then we build a spatial reasoning module to measure the relevance between vectors in spatial domain with the global cue vectors, and select the most related feature vectors for temporal anomaly detection. The experimental results on the CityScene challenge demonstrate the effectiveness of our model.
Spatial-Temporal Tensor Graph Convolutional Network for Traffic Prediction
Mar 10, 2021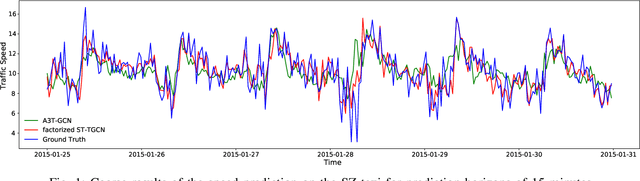
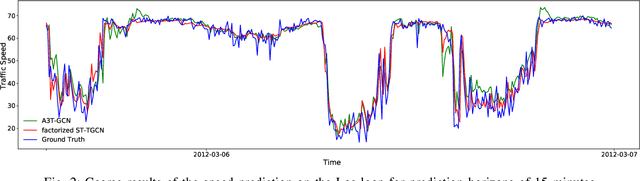
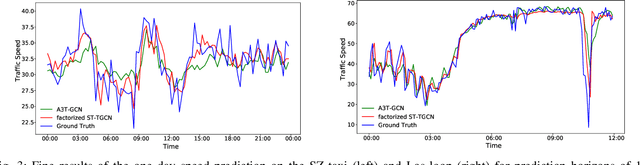
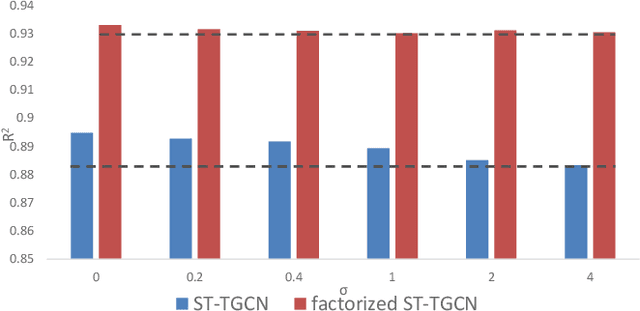
Accurate traffic prediction is crucial to the guidance and management of urban traffics. However, most of the existing traffic prediction models do not consider the computational burden and memory space when they capture spatial-temporal dependence among traffic data. In this work, we propose a factorized Spatial-Temporal Tensor Graph Convolutional Network to deal with traffic speed prediction. Traffic networks are modeled and unified into a graph that integrates spatial and temporal information simultaneously. We further extend graph convolution into tensor space and propose a tensor graph convolution network to extract more discriminating features from spatial-temporal graph data. To reduce the computational burden, we take Tucker tensor decomposition and derive factorized a tensor convolution, which performs separate filtering in small-scale space, time, and feature modes. Besides, we can benefit from noise suppression of traffic data when discarding those trivial components in the process of tensor decomposition. Extensive experiments on two real-world traffic speed datasets demonstrate our method is more effective than those traditional traffic prediction methods, and meantime achieves state-of-the-art performance.
Interest-Behaviour Multiplicative Network for Resource-limited Recommendation
Oct 10, 2020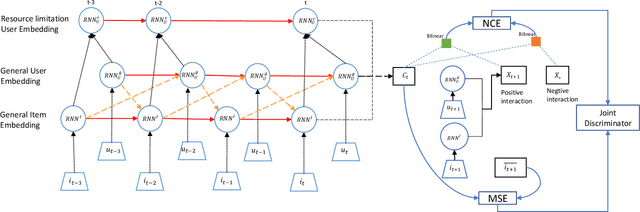

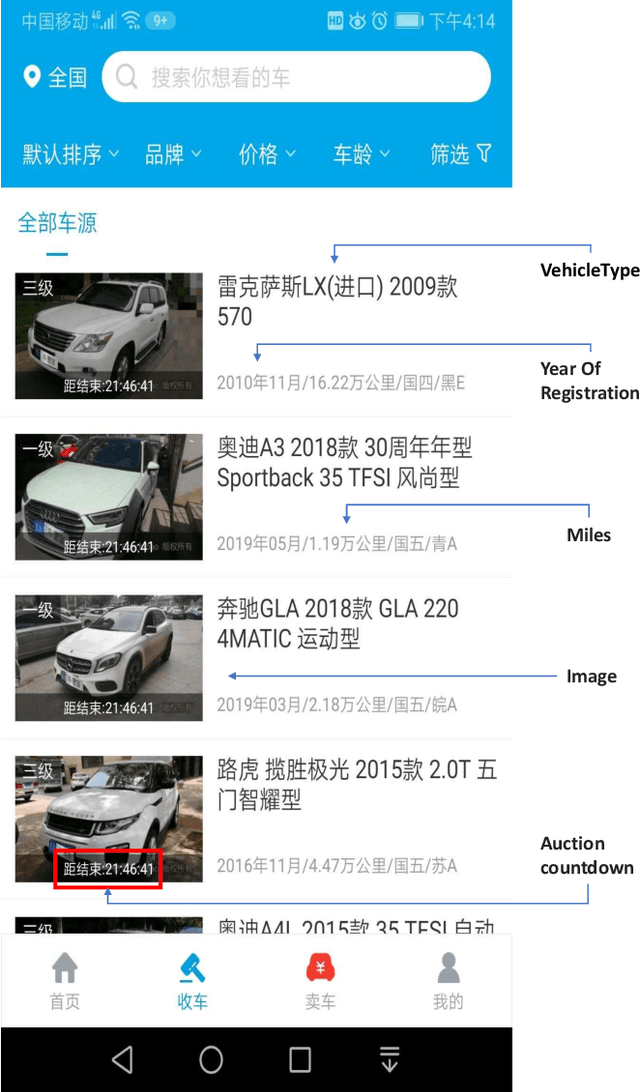

Resource constraints, e.g. limited product inventory or product categories, may affect consumers' choices or preferences in some recommendation tasks, but are usually ignored in previous recommendation methods. In this paper, we aim to mine the cue of user preferences in resource-limited recommendation tasks, for which purpose we specifically build a largely used car transaction dataset possessing resource-limitation characteristics. Accordingly, we propose an interest-behaviour multiplicative network to predict the user's future interaction based on dynamic connections between users and items. To describe the user-item connection dynamically, mutually-recursive recurrent neural networks (MRRNNs) are introduced to capture interactive long-term dependencies, and meantime effective representations of users and items are obtained. To further take the resource limitation into consideration, a resource-limited branch is built to specifically explore the influence of resource variation caused by user behaviour for user preferences. Finally, mutual information is introduced to measure the similarity between the user action and fused features to predict future interaction, where the fused features come from both MRRNNs and resource-limited branches. We test the performance on the built used car transaction dataset as well as the Tmall dataset, and the experimental results verify the effectiveness of our framework.
Spatial Transformer Point Convolution
Sep 03, 2020



Point clouds are unstructured and unordered in the embedded 3D space. In order to produce consistent responses under different permutation layouts, most existing methods aggregate local spatial points through maximum or summation operation. But such an aggregation essentially belongs to the isotropic filtering on all operated points therein, which tends to lose the information of geometric structures. In this paper, we propose a spatial transformer point convolution (STPC) method to achieve anisotropic convolution filtering on point clouds. To capture and represent implicit geometric structures, we specifically introduce spatial direction dictionary to learn those latent geometric components. To better encode unordered neighbor points, we design sparse deformer to transform them into the canonical ordered dictionary space by using direction dictionary learning. In the transformed space, the standard image-like convolution can be leveraged to generate anisotropic filtering, which is more robust to express those finer variances of local regions. Dictionary learning and encoding processes are encapsulated into a network module and jointly learnt in an end-to-end manner. Extensive experiments on several public datasets (including S3DIS, Semantic3D, SemanticKITTI) demonstrate the effectiveness of our proposed method in point clouds semantic segmentation task.
Localizing Anomalies from Weakly-Labeled Videos
Aug 20, 2020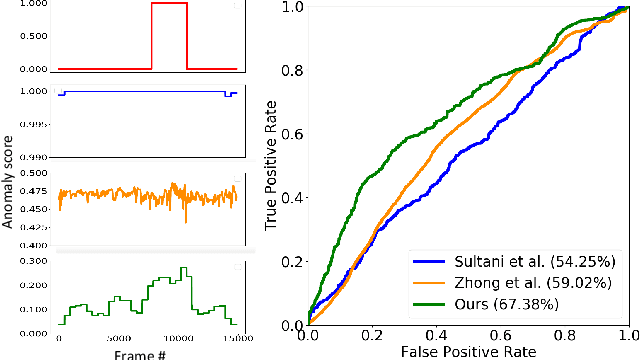
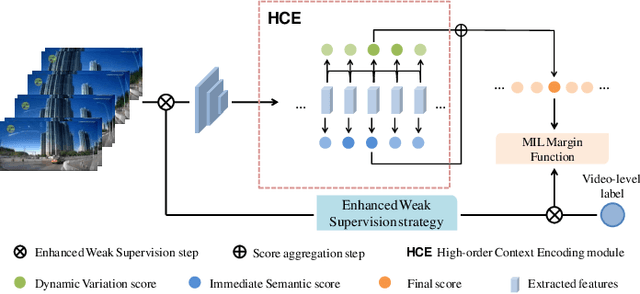

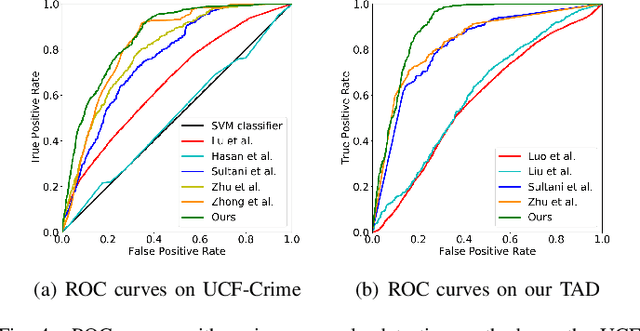
Video anomaly detection under video-level labels is currently a challenging task. Previous works have made progresses on discriminating whether a video sequencecontains anomalies. However, most of them fail to accurately localize the anomalous events within videos in the temporal domain. In this paper, we propose a Weakly Supervised Anomaly Localization (WSAL) method focusing on temporally localizing anomalous segments within anomalous videos. Inspired by the appearance difference in anomalous videos, the evolution of adjacent temporal segments is evaluated for the localization of anomalous segments. To this end, a high-order context encoding model is proposed to not only extract semantic representations but also measure the dynamic variations so that the temporal context could be effectively utilized. In addition, in order to fully utilize the spatial context information, the immediate semantics are directly derived from the segment representations. The dynamic variations as well as the immediate semantics, are efficiently aggregated to obtain the final anomaly scores. An enhancement strategy is further proposed to deal with noise interference and the absence of localization guidance in anomaly detection. Moreover, to facilitate the diversity requirement for anomaly detection benchmarks, we also collect a new traffic anomaly (TAD) dataset which specifies in the traffic conditions, differing greatly from the current popular anomaly detection evaluation benchmarks.Extensive experiments are conducted to verify the effectiveness of different components, and our proposed method achieves new state-of-the-art performance on the UCF-Crime and TAD datasets.
Instance-Aware Graph Convolutional Network for Multi-Label Classification
Aug 19, 2020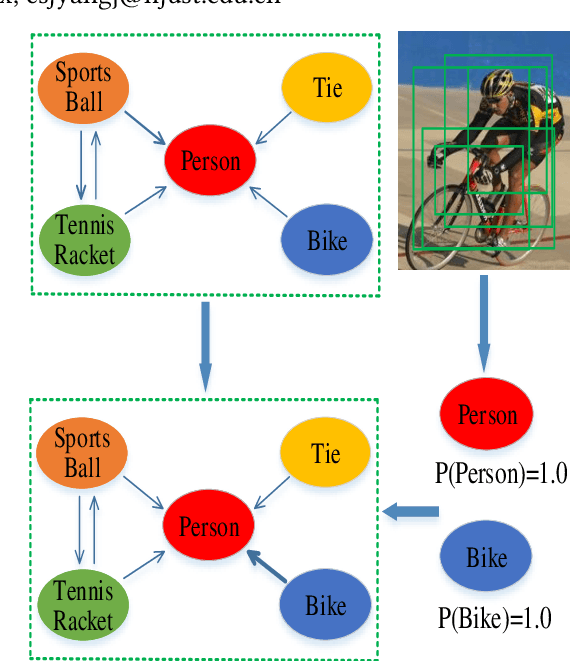
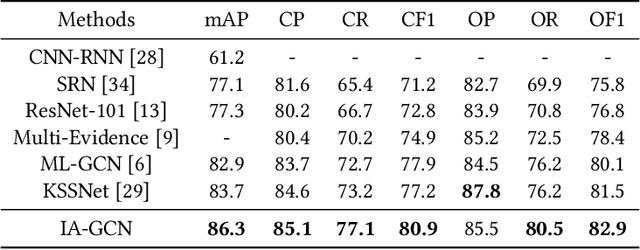
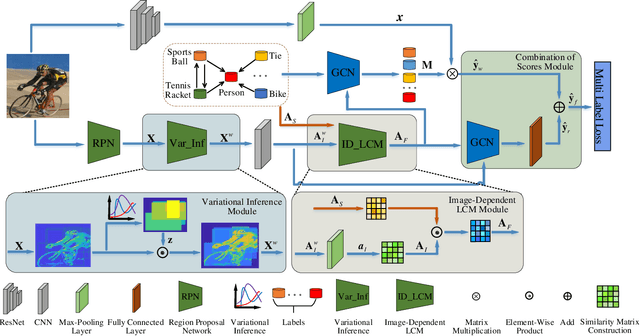
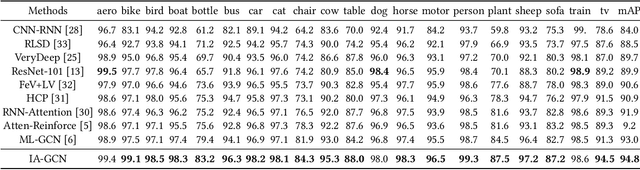
Graph convolutional neural network (GCN) has effectively boosted the multi-label image recognition task by introducing label dependencies based on statistical label co-occurrence of data. However, in previous methods, label correlation is computed based on statistical information of data and therefore the same for all samples, and this makes graph inference on labels insufficient to handle huge variations among numerous image instances. In this paper, we propose an instance-aware graph convolutional neural network (IA-GCN) framework for multi-label classification. As a whole, two fused branches of sub-networks are involved in the framework: a global branch modeling the whole image and a region-based branch exploring dependencies among regions of interests (ROIs). For label diffusion of instance-awareness in graph convolution, rather than using the statistical label correlation alone, an image-dependent label correlation matrix (LCM), fusing both the statistical LCM and an individual one of each image instance, is constructed for graph inference on labels to inject adaptive information of label-awareness into the learned features of the model. Specifically, the individual LCM of each image is obtained by mining the label dependencies based on the scores of labels about detected ROIs. In this process, considering the contribution differences of ROIs to multi-label classification, variational inference is introduced to learn adaptive scaling factors for those ROIs by considering their complex distribution. Finally, extensive experiments on MS-COCO and VOC datasets show that our proposed approach outperforms existing state-of-the-art methods.