 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Dialogue State Tracking via Cross-Task Transfer
Sep 10, 2021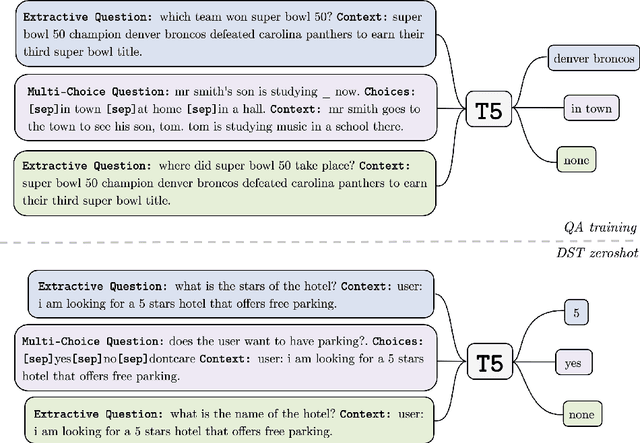
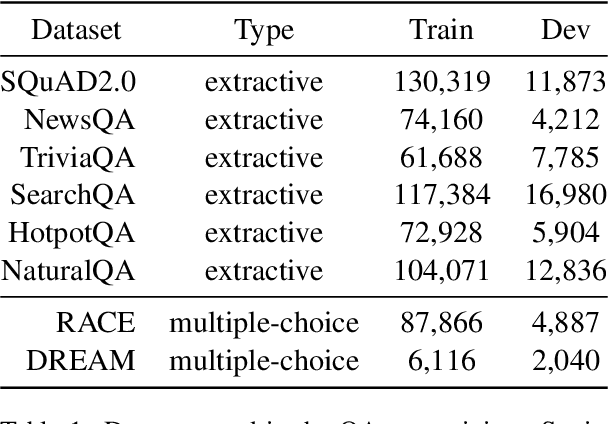
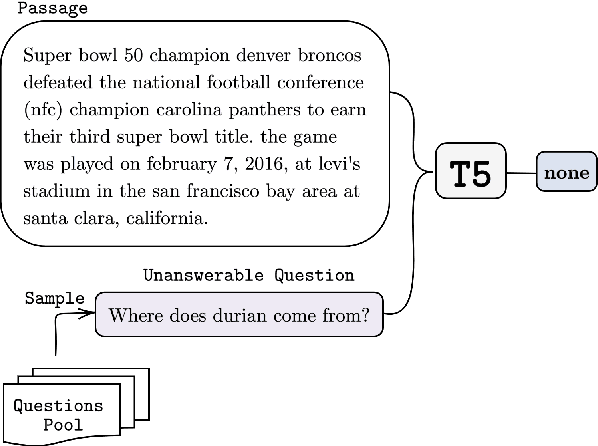
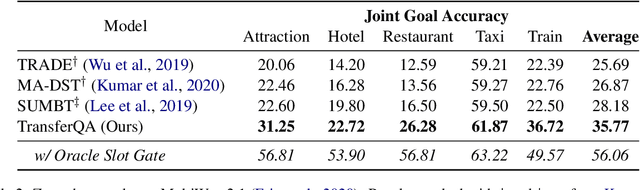
Zero-shot transfer learning for dialogue state tracking (DST) enables us to handle a variety of task-oriented dialogue domains without the expense of collecting in-domain data. In this work, we propose to transfer the \textit{cross-task} knowledge from general question answering (QA) corpora for the zero-shot DST task. Specifically, we propose TransferQA, a transferable generative QA model that seamlessly combines extractive QA and multi-choice QA via a text-to-text transformer framework, and tracks both categorical slots and non-categorical slots in DST. In addition, we introduce two effective ways to construct unanswerable questions, namely, negative question sampling and context truncation, which enable our model to handle "none" value slots in the zero-shot DST setting. The extensive experiments show that our approaches substantially improve the existing zero-shot and few-shot results on MultiWoz. Moreover, compared to the fully trained baseline on the Schema-Guided Dialogue dataset, our approach shows better generalization ability in unseen domains.
CAiRE in DialDoc21: Data Augmentation for Information-Seeking Dialogue System
Jun 08, 2021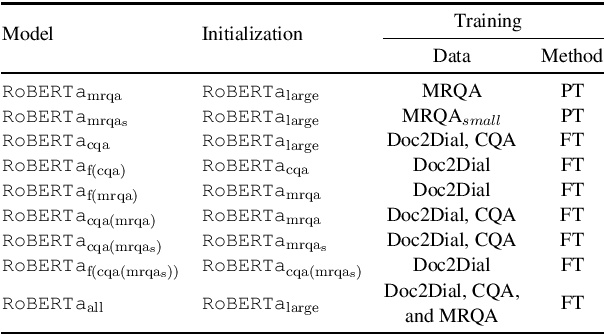
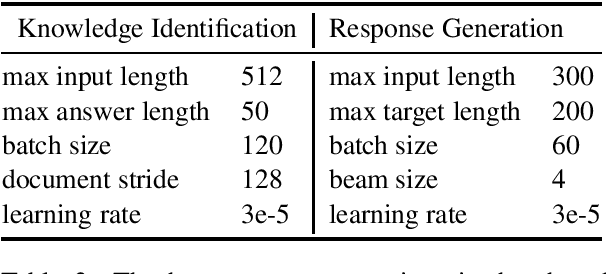
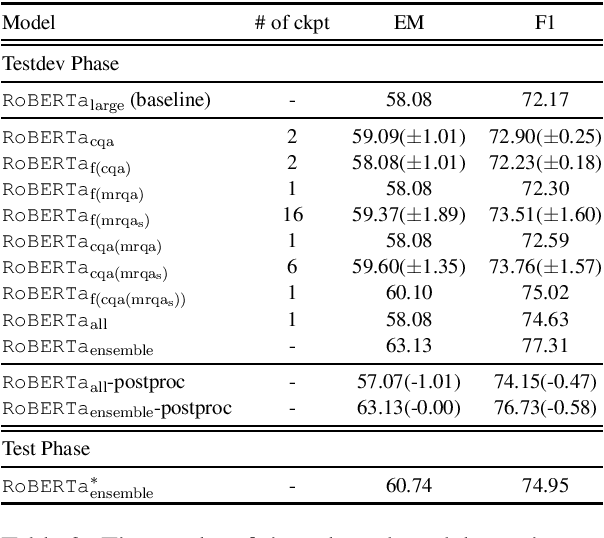
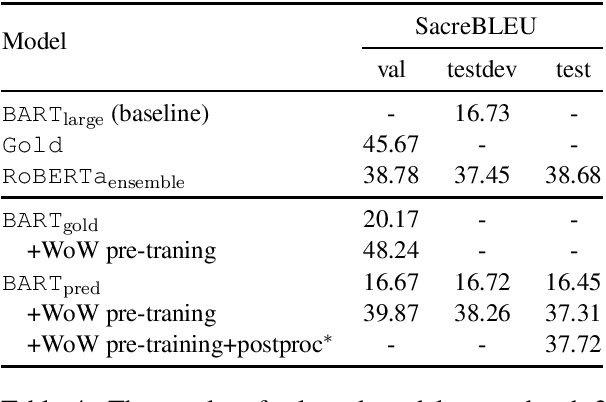
Information-seeking dialogue systems, including knowledge identification and response generation, aim to respond to users with fluent, coherent, and informative responses based on users' needs, which. To tackle this challenge, we utilize data augmentation methods and several training techniques with the pre-trained language models to learn a general pattern of the task and thus achieve promising performance. In DialDoc21 competition, our system achieved 74.95 F1 score and 60.74 Exact Match score in subtask 1, and 37.72 SacreBLEU score in subtask 2. Empirical analysis is provided to explain the effectiveness of our approaches.
BiToD: A Bilingual Multi-Domain Dataset For Task-Oriented Dialogue Modeling
Jun 05, 2021
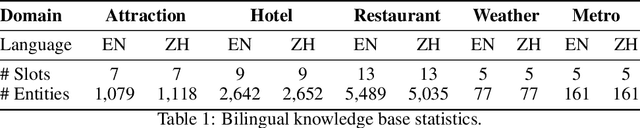
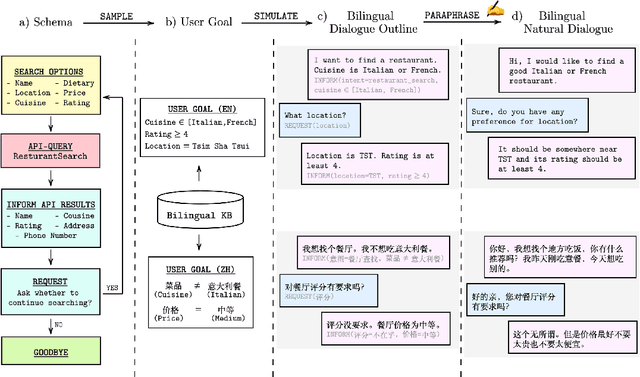
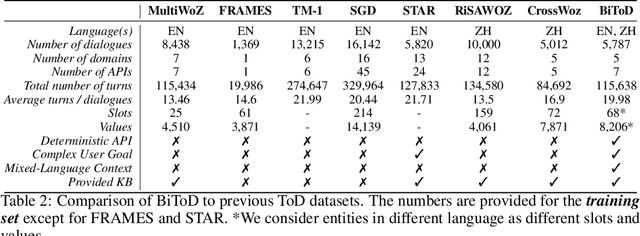
Task-oriented dialogue (ToD) benchmarks provide an important avenue to measure progress and develop better conversational agents. However, existing datasets for end-to-end ToD modeling are limited to a single language, hindering the development of robust end-to-end ToD systems for multilingual countries and regions. Here we introduce BiToD, the first bilingual multi-domain dataset for end-to-end task-oriented dialogue modeling. BiToD contains over 7k multi-domain dialogues (144k utterances) with a large and realistic bilingual knowledge base. It serves as an effective benchmark for evaluating bilingual ToD systems and cross-lingual transfer learning approaches. We provide state-of-the-art baselines under three evaluation settings (monolingual, bilingual, and cross-lingual). The analysis of our baselines in different settings highlights 1) the effectiveness of training a bilingual ToD system compared to two independent monolingual ToD systems, and 2) the potential of leveraging a bilingual knowledge base and cross-lingual transfer learning to improve the system performance under low resource condition.
Leveraging Slot Descriptions for Zero-Shot Cross-Domain Dialogue State Tracking
May 10, 2021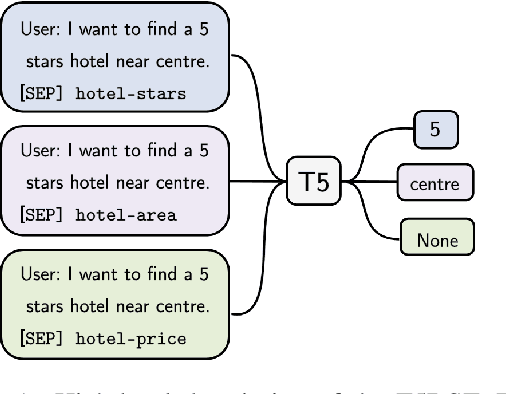
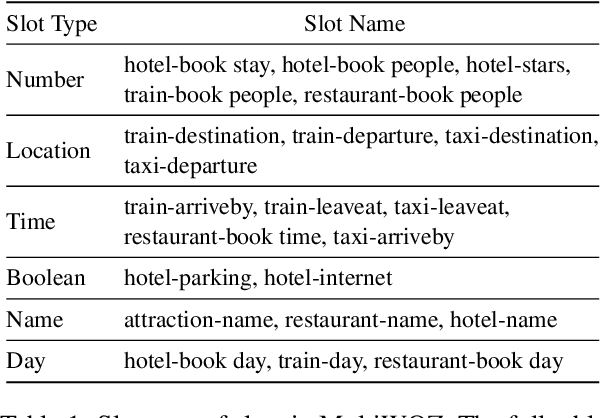

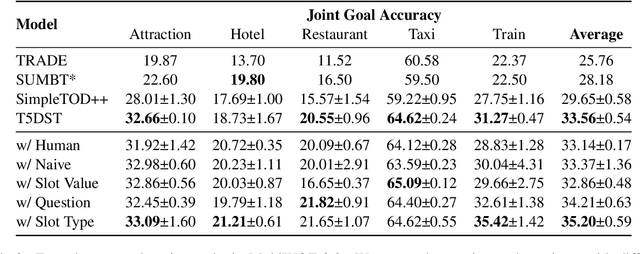
Zero-shot cross-domain dialogue state tracking (DST) enables us to handle task-oriented dialogue in unseen domains without the expense of collecting in-domain data. In this paper, we propose a slot description enhanced generative approach for zero-shot cross-domain DST. Specifically, our model first encodes dialogue context and slots with a pre-trained self-attentive encoder, and generates slot values in an auto-regressive manner. In addition, we incorporate Slot Type Informed Descriptions that capture the shared information across slots to facilitate cross-domain knowledge transfer. Experimental results on the MultiWOZ dataset show that our proposed method significantly improves existing state-of-the-art results in the zero-shot cross-domain setting.
Are Multilingual Models Effective in Code-Switching?
Mar 24, 2021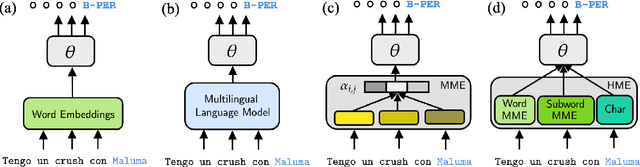
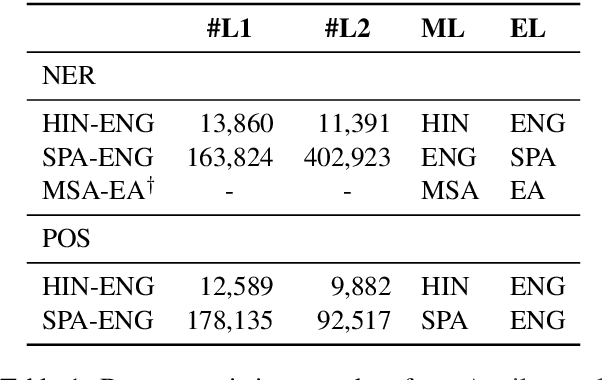
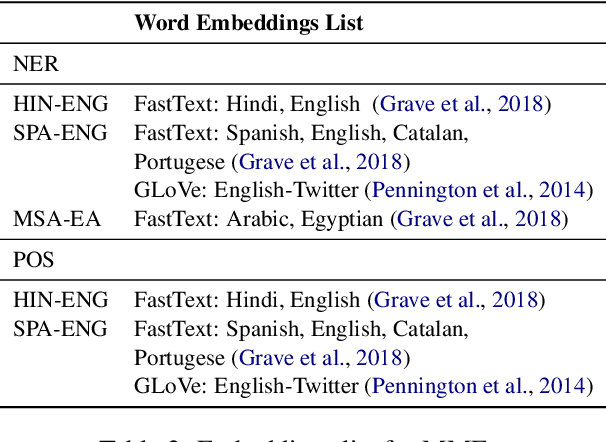
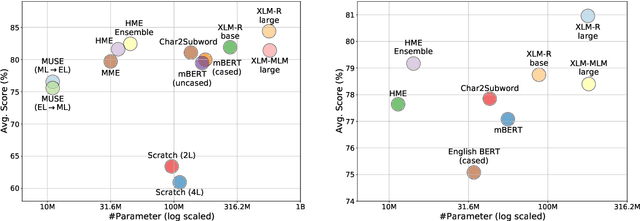
Multilingual language models have shown decent performance in multilingual and cross-lingual natural language understanding tasks. However, the power of these multilingual models in code-switching tasks has not been fully explored. In this paper, we study the effectiveness of multilingual language models to understand their capability and adaptability to the mixed-language setting by considering the inference speed, performance, and number of parameters to measure their practicality. We conduct experiments in three language pairs on named entity recognition and part-of-speech tagging and compare them with existing methods, such as using bilingual embeddings and multilingual meta-embeddings. Our findings suggest that pre-trained multilingual models do not necessarily guarantee high-quality representations on code-switching, while using meta-embeddings achieves similar results with significantly fewer parameters.
Continual Learning in Task-Oriented Dialogue Systems
Dec 31, 2020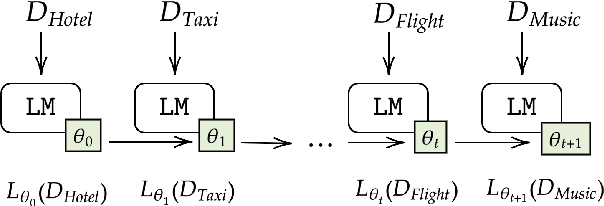
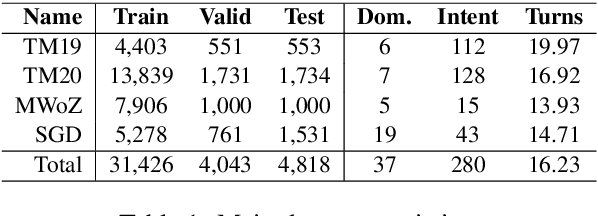

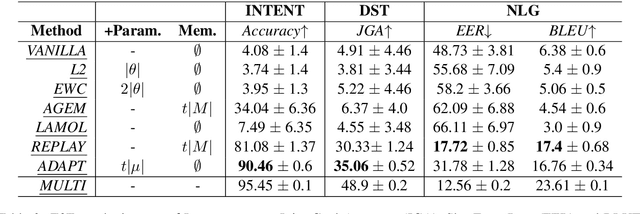
Continual learning in task-oriented dialogue systems can allow us to add new domains and functionalities through time without incurring the high cost of a whole system retraining. In this paper, we propose a continual learning benchmark for task-oriented dialogue systems with 37 domains to be learned continuously in four settings, such as intent recognition, state tracking, natural language generation, and end-to-end. Moreover, we implement and compare multiple existing continual learning baselines, and we propose a simple yet effective architectural method based on residual adapters. Our experiments demonstrate that the proposed architectural method and a simple replay-based strategy perform comparably well but they both achieve inferior performance to the multi-task learning baseline, in where all the data are shown at once, showing that continual learning in task-oriented dialogue systems is a challenging task. Furthermore, we reveal several trade-offs between different continual learning methods in term of parameter usage and memory size, which are important in the design of a task-oriented dialogue system. The proposed benchmark is released together with several baselines to promote more research in this direction.
Plug-and-Play Conversational Models
Oct 09, 2020
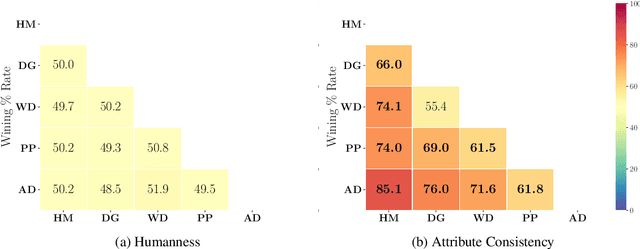

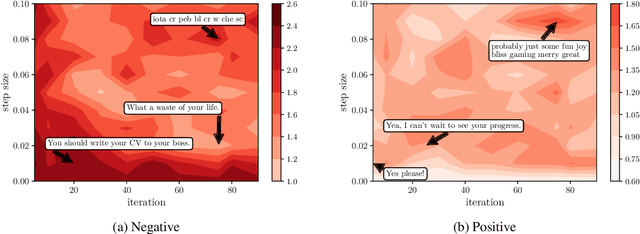
There has been considerable progress made towards conversational models that generate coherent and fluent responses; however, this often involves training large language models on large dialogue datasets, such as Reddit. These large conversational models provide little control over the generated responses, and this control is further limited in the absence of annotated conversational datasets for attribute specific generation that can be used for fine-tuning the model. In this paper, we first propose and evaluate plug-and-play methods for controllable response generation, which does not require dialogue specific datasets and does not rely on fine-tuning a large model. While effective, the decoding procedure induces considerable computational overhead, rendering the conversational model unsuitable for interactive usage. To overcome this, we introduce an approach that does not require further computation at decoding time, while also does not require any fine-tuning of a large language model. We demonstrate, through extensive automatic and human evaluation, a high degree of control over the generated conversational responses with regard to multiple desired attributes, while being fluent.
Cross-lingual Spoken Language Understanding with Regularized Representation Alignment
Sep 30, 2020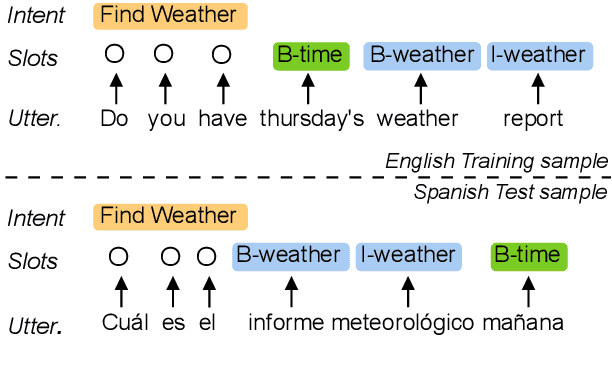
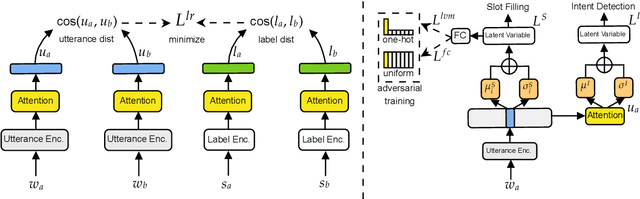
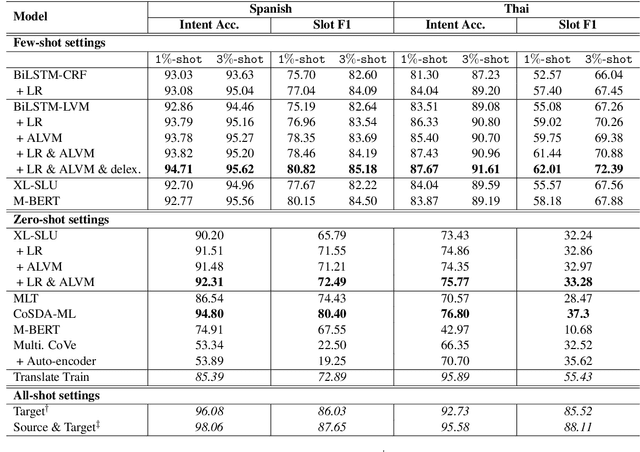
Despite the promising results of current cross-lingual models for spoken language understanding systems, they still suffer from imperfect cross-lingual representation alignments between the source and target languages, which makes the performance sub-optimal. To cope with this issue, we propose a regularization approach to further align word-level and sentence-level representations across languages without any external resource. First, we regularize the representation of user utterances based on their corresponding labels. Second, we regularize the latent variable model (Liu et al., 2019) by leveraging adversarial training to disentangle the latent variables. Experiments on the cross-lingual spoken language understanding task show that our model outperforms current state-of-the-art methods in both few-shot and zero-shot scenarios, and our model, trained on a few-shot setting with only 3\% of the target language training data, achieves comparable performance to the supervised training with all the training data.
Learning Knowledge Bases with Parameters for Task-Oriented Dialogue Systems
Sep 28, 2020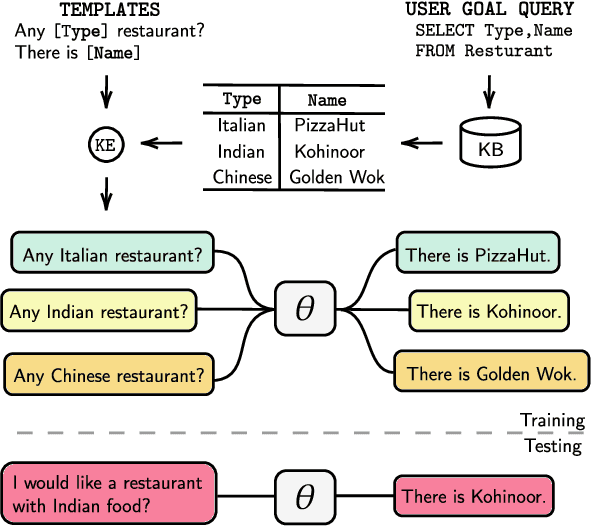

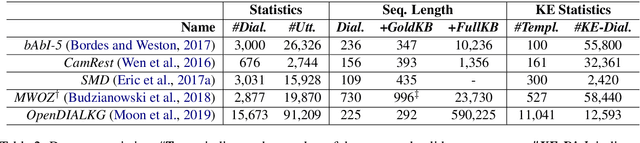
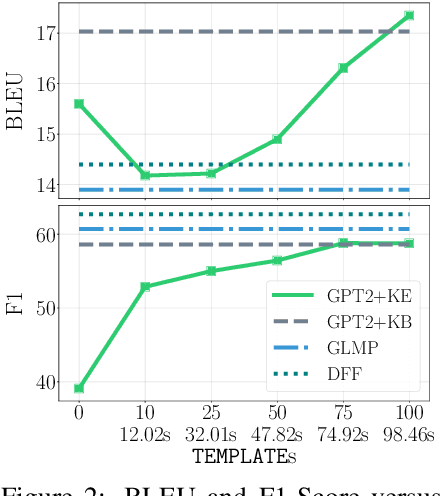
Task-oriented dialogue systems are either modularized with separate dialogue state tracking (DST) and management steps or end-to-end trainable. In either case, the knowledge base (KB) plays an essential role in fulfilling user requests. Modularized systems rely on DST to interact with the KB, which is expensive in terms of annotation and inference time. End-to-end systems use the KB directly as input, but they cannot scale when the KB is larger than a few hundred entries. In this paper, we propose a method to embed the KB, of any size, directly into the model parameters. The resulting model does not require any DST or template responses, nor the KB as input, and it can dynamically update its KB via fine-tuning. We evaluate our solution in five task-oriented dialogue datasets with small, medium, and large KB size. Our experiments show that end-to-end models can effectively embed knowledge bases in their parameters and achieve competitive performance in all evaluated datasets.
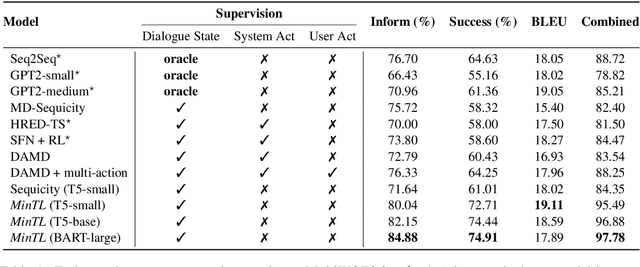
MinTL: Minimalist Transfer Learning for Task-Oriented Dialogue Systems
Sep 28, 2020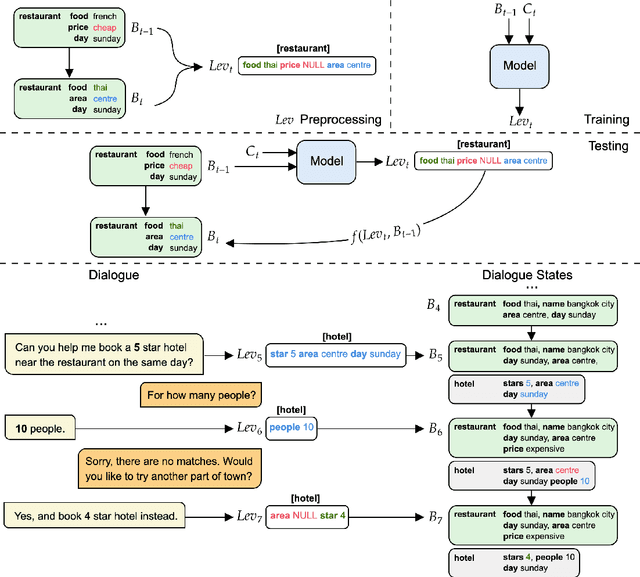
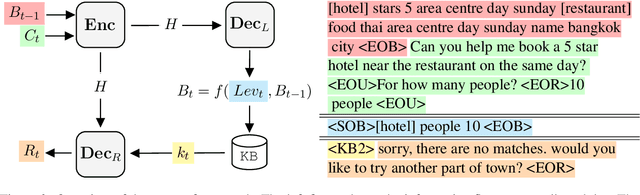
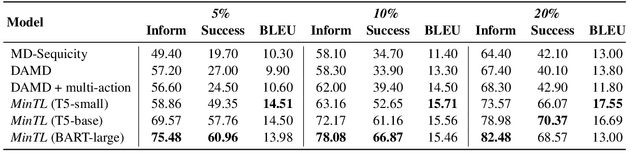
In this paper, we propose Minimalist Transfer Learning (MinTL) to simplify the system design process of task-oriented dialogue systems and alleviate the over-dependency on annotated data. MinTL is a simple yet effective transfer learning framework, which allows us to plug-and-play pre-trained seq2seq models, and jointly learn dialogue state tracking and dialogue response generation. Unlike previous approaches, which use a copy mechanism to "carryover" the old dialogue states to the new one, we introduce Levenshtein belief spans (Lev), that allows efficient dialogue state tracking with a minimal generation length. We instantiate our learning framework with two pre-trained backbones: T5 and BART, and evaluate them on MultiWOZ. Extensive experiments demonstrate that: 1) our systems establish new state-of-the-art results on end-to-end response generation, 2) MinTL-based systems are more robust than baseline methods in the low resource setting, and they achieve competitive results with only 20\% training data, and 3) Lev greatly improves the inference efficiency.