 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign and Nonlinear Modeling of a Modular Cable Driven Soft Robotic Arm
Jan 12, 2024We propose a novel multi-section cable-driven soft robotic arm inspired by octopus tentacles along with a new modeling approach. Each section of the modular manipulator is made of a soft tubing backbone, a soft silicon arm body, and two rigid endcaps, which connect adjacent sections and decouple the actuation cables of different sections. The soft robotic arm is made with casting after the rigid endcaps are 3D-printed, achieving low-cost and convenient fabrication. To capture the nonlinear effect of cables pushing into the soft silicon arm body, which results from the absence of intermediate rigid cable guides for higher compliance, an analytical static model is developed to capture the relationship between the bending curvature and the cable lengths. The proposed model shows superior prediction performance in experiments over that of a baseline model, especially under large bending conditions. Based on the nonlinear static model, a kinematic model of a multi-section arm is further developed and used to derive a motion planning algorithm. Experiments show that the proposed soft arm has high flexibility and a large workspace, and the tracking errors under the algorithm based on the proposed modeling approach are up to 52$\%$ smaller than those with the algorithm derived from the baseline model. The presented modeling approach is expected to be applicable to a broad range of soft cable-driven actuators and manipulators.
High-Precision Fruit Localization Using Active Laser-Camera Scanning: Robust Laser Line Extraction for 2D-3D Transformation
Nov 15, 2023Recent advancements in deep learning-based approaches have led to remarkable progress in fruit detection, enabling robust fruit identification in complex environments. However, much less progress has been made on fruit 3D localization, which is equally crucial for robotic harvesting. Complex fruit shape/orientation, fruit clustering, varying lighting conditions, and occlusions by leaves and branches have greatly restricted existing sensors from achieving accurate fruit localization in the natural orchard environment. In this paper, we report on the design of a novel localization technique, called Active Laser-Camera Scanning (ALACS), to achieve accurate and robust fruit 3D localization. The ALACS hardware setup comprises a red line laser, an RGB color camera, a linear motion slide, and an external RGB-D camera. Leveraging the principles of dynamic-targeting laser-triangulation, ALACS enables precise transformation of the projected 2D laser line from the surface of apples to the 3D positions. To facilitate laser pattern acquisitions, a Laser Line Extraction (LLE) method is proposed for robust and high-precision feature extraction on apples. Comprehensive evaluations of LLE demonstrated its ability to extract precise patterns under variable lighting and occlusion conditions. The ALACS system achieved average apple localization accuracies of 6.9 11.2 mm at distances ranging from 1.0 m to 1.6 m, compared to 21.5 mm by a commercial RealSense RGB-D camera, in an indoor experiment. Orchard evaluations demonstrated that ALACS has achieved a 95% fruit detachment rate versus a 71% rate by the RealSense camera. By overcoming the challenges of apple 3D localization, this research contributes to the advancement of robotic fruit harvesting technology.
Cross-modal Generative Model for Visual-Guided Binaural Stereo Generation
Nov 13, 2023Binaural stereo audio is recorded by imitating the way the human ear receives sound, which provides people with an immersive listening experience. Existing approaches leverage autoencoders and directly exploit visual spatial information to synthesize binaural stereo, resulting in a limited representation of visual guidance. For the first time, we propose a visually guided generative adversarial approach for generating binaural stereo audio from mono audio. Specifically, we develop a Stereo Audio Generation Model (SAGM), which utilizes shared spatio-temporal visual information to guide the generator and the discriminator to work separately. The shared visual information is updated alternately in the generative adversarial stage, allowing the generator and discriminator to deliver their respective guided knowledge while visually sharing. The proposed method learns bidirectional complementary visual information, which facilitates the expression of visual guidance in generation. In addition, spatial perception is a crucial attribute of binaural stereo audio, and thus the evaluation of stereo spatial perception is essential. However, previous metrics failed to measure the spatial perception of audio. To this end, a metric to measure the spatial perception of audio is proposed for the first time. The proposed metric is capable of measuring the magnitude and direction of spatial perception in the temporal dimension. Further, considering its function, it is feasible to utilize it instead of demanding user studies to some extent. The proposed method achieves state-of-the-art performance on 2 datasets and 5 evaluation metrics. Qualitative experiments and user studies demonstrate that the method generates space-realistic stereo audio.
Active Laser-Camera Scanning for High-Precision Fruit Localization in Robotic Harvesting: System Design and Calibration
Nov 04, 2023Robust and effective fruit detection and localization is essential for robotic harvesting systems. While extensive research efforts have been devoted to improving fruit detection, less emphasis has been placed on the fruit localization aspect, which is a crucial yet challenging task due to limited depth accuracy from existing sensor measurements in the natural orchard environment with variable lighting conditions and foliage/branch occlusions. In this paper, we present the system design and calibration of an Active LAser-Camera Scanner (ALACS), a novel perception module for robust and high-precision fruit localization. The hardware of ALACS mainly consists of a red line laser, an RGB camera, and a linear motion slide, which are seamlessly integrated into an active scanning scheme where a dynamic-targeting laser-triangulation principle is employed. A high-fidelity extrinsic model is developed to pair the laser illumination and the RGB camera, enabling precise depth computation when the target is captured by both sensors. A random sample consensus-based robust calibration scheme is then designed to calibrate the model parameters based on collected data. Comprehensive evaluations are conducted to validate the system model and calibration scheme. The results show that the proposed calibration method can detect and remove data outliers to achieve robust parameter computation, and the calibrated ALACS system is able to achieve high-precision localization with millimeter-level accuracy.
SoybeanNet: Transformer-Based Convolutional Neural Network for Soybean Pod Counting from Unmanned Aerial Vehicle (UAV) Images
Oct 16, 2023



Soybeans are a critical source of food, protein and oil, and thus have received extensive research aimed at enhancing their yield, refining cultivation practices, and advancing soybean breeding techniques. Within this context, soybean pod counting plays an essential role in understanding and optimizing production. Despite recent advancements, the development of a robust pod-counting algorithm capable of performing effectively in real-field conditions remains a significant challenge This paper presents a pioneering work of accurate soybean pod counting utilizing unmanned aerial vehicle (UAV) images captured from actual soybean fields in Michigan, USA. Specifically, this paper presents SoybeanNet, a novel point-based counting network that harnesses powerful transformer backbones for simultaneous soybean pod counting and localization with high accuracy. In addition, a new dataset of UAV-acquired images for soybean pod counting was created and open-sourced, consisting of 113 drone images with more than 260k manually annotated soybean pods captured under natural lighting conditions. Through comprehensive evaluations, SoybeanNet demonstrated superior performance over five state-of-the-art approaches when tested on the collected images. Remarkably, SoybeanNet achieved a counting accuracy of $84.51\%$ when tested on the testing dataset, attesting to its efficacy in real-world scenarios. The publication also provides both the source code (\url{https://github.com/JiajiaLi04/Soybean-Pod-Counting-from-UAV-Images}) and the labeled soybean dataset (\url{https://www.kaggle.com/datasets/jiajiali/uav-based-soybean-pod-images}), offering a valuable resource for future research endeavors in soybean pod counting and related fields.
Foundation Models in Smart Agriculture: Basics, Opportunities, and Challenges
Aug 18, 2023



The past decade has witnessed the rapid development of ML and DL methodologies in agricultural systems, showcased by great successes in variety of agricultural applications. However, these conventional ML/DL models have certain limitations: They heavily rely on large, costly-to-acquire labeled datasets for training, require specialized expertise for development and maintenance, and are mostly tailored for specific tasks, thus lacking generalizability. Recently, foundation models have demonstrated remarkable successes in language and vision tasks across various domains. These models are trained on a vast amount of data from multiple domains and modalities. Once trained, they can accomplish versatile tasks with just minor fine-tuning and minimal task-specific labeled data. Despite their proven effectiveness and huge potential, there has been little exploration of applying FMs to agriculture fields. Therefore, this study aims to explore the potential of FMs in the field of smart agriculture. In particular, we present conceptual tools and technical background to facilitate the understanding of the problem space and uncover new research directions in this field. To this end, we first review recent FMs in the general computer science domain and categorize them into four categories: language FMs, vision FMs, multimodal FMs, and reinforcement learning FMs. Subsequently, we outline the process of developing agriculture FMs and discuss their potential applications in smart agriculture. We also discuss the unique challenges associated with developing AFMs, including model training, validation, and deployment. Through this study, we contribute to the advancement of AI in agriculture by introducing AFMs as a promising paradigm that can significantly mitigate the reliance on extensive labeled datasets and enhance the efficiency, effectiveness, and generalization of agricultural AI systems.
Label-Efficient Learning in Agriculture: A Comprehensive Review
May 24, 2023



The past decade has witnessed many great successes of machine learning (ML) and deep learning (DL) applications in agricultural systems, including weed control, plant disease diagnosis, agricultural robotics, and precision livestock management. Despite tremendous progresses, one downside of such ML/DL models is that they generally rely on large-scale labeled datasets for training, and the performance of such models is strongly influenced by the size and quality of available labeled data samples. In addition, collecting, processing, and labeling such large-scale datasets is extremely costly and time-consuming, partially due to the rising cost in human labor. Therefore, developing label-efficient ML/DL methods for agricultural applications has received significant interests among researchers and practitioners. In fact, there are more than 50 papers on developing and applying deep-learning-based label-efficient techniques to address various agricultural problems since 2016, which motivates the authors to provide a timely and comprehensive review of recent label-efficient ML/DL methods in agricultural applications. To this end, we first develop a principled taxonomy to organize these methods according to the degree of supervision, including weak supervision (i.e., active learning and semi-/weakly- supervised learning), and no supervision (i.e., un-/self- supervised learning), supplemented by representative state-of-the-art label-efficient ML/DL methods. In addition, a systematic review of various agricultural applications exploiting these label-efficient algorithms, such as precision agriculture, plant phenotyping, and postharvest quality assessment, is presented. Finally, we discuss the current problems and challenges, as well as future research directions. A well-classified paper list can be accessed at https://github.com/DongChen06/Label-efficient-in-Agriculture.
ABatRe-Sim: A Comprehensive Framework for Automated Battery Recycling Simulation
Mar 14, 2023



With the rapid surge in the number of on-road Electric Vehicles (EVs), the amount of spent lithium-ion (Li-ion) batteries is also expected to explosively grow. The spent battery packs contain valuable metal and materials that should be recovered, recycled, and reused. However, only less than 5% of the Li-ion batteries are currently recycled, due to a multitude of challenges in technology, logistics and regulation. Existing battery recycling is performed manually, which can pose a series of risks to the human operator as a consequence of remaining high voltage and chemical hazards. Therefore, there is a critical need to develop an automated battery recycling system. In this paper, we present ABatRe-sim, an open-source robotic battery recycling simulator, to facilitate the research and development in efficient and effective battery recycling au-omation. Specifically, we develop a detailed CAD model of the battery pack (with screws, wires, and battery modules), which is imported into Gazebo to enable robot-object interaction in the robot operating system (ROS) environment. It also allows the simulation of battery packs of various aging conditions. Furthermore, perception, planning, and control algorithms are developed to establish the benchmark to demonstrate the interface and realize the basic functionalities for further user customization. Discussions on the utilization and future extensions of the simulator are also presented.
O2RNet: Occluder-Occludee Relational Network for Robust Apple Detection in Clustered Orchard Environments
Mar 08, 2023Automated apple harvesting has attracted significant research interest in recent years due to its potential to revolutionize the apple industry, addressing the issues of shortage and high costs in labor. One key technology to fully enable efficient automated harvesting is accurate and robust apple detection, which is challenging due to complex orchard environments that involve varying lighting conditions and foliage/branch occlusions. Furthermore, clustered apples are common in the orchard, which brings additional challenges as the clustered apples may be identified as one apple. This will cause issues in localization for subsequent robotic operations. In this paper, we present the development of a novel deep learning-based apple detection framework, Occluder-Occludee Relational Network (O2RNet), for robust detection of apples in such clustered environments. This network exploits the occuluder-occludee relationship modeling head by introducing a feature expansion structure to enable the combination of layered traditional detectors to split clustered apples and foliage occlusions. More specifically, we collect a comprehensive apple orchard image dataset under different lighting conditions (overcast, front lighting, and back lighting) with frequent apple occlusions. We then develop a novel occlusion-aware network for apple detection, in which a feature expansion structure is incorporated into the convolutional neural networks to extract additional features generated by the original network for occluded apples. Comprehensive evaluations are performed, which show that the developed O2RNet outperforms state-of-the-art models with a higher accuracy of 94\% and a higher F1-score of 0.88 on apple detection.
Deep Data Augmentation for Weed Recognition Enhancement: A Diffusion Probabilistic Model and Transfer Learning Based Approach
Oct 18, 2022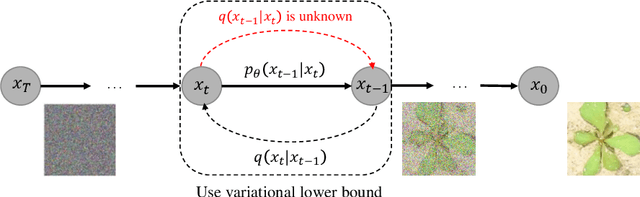
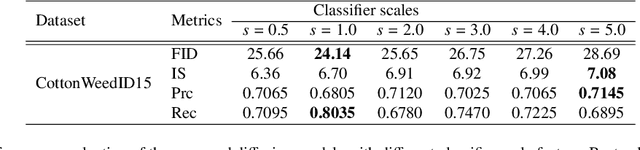
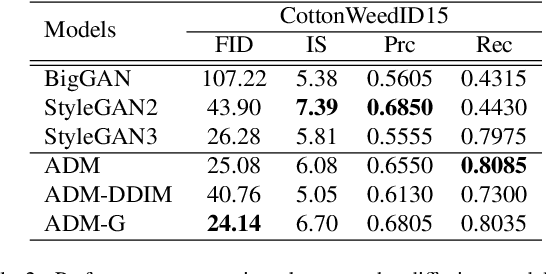

Weed management plays an important role in many modern agricultural applications. Conventional weed control methods mainly rely on chemical herbicides or hand weeding, which are often cost-ineffective, environmentally unfriendly, or even posing a threat to food safety and human health. Recently, automated/robotic weeding using machine vision systems has seen increased research attention with its potential for precise and individualized weed treatment. However, dedicated, large-scale, and labeled weed image datasets are required to develop robust and effective weed identification systems but they are often difficult and expensive to obtain. To address this issue, data augmentation approaches, such as generative adversarial networks (GANs), have been explored to generate highly realistic images for agricultural applications. Yet, despite some progress, those approaches are often complicated to train or have difficulties preserving fine details in images. In this paper, we present the first work of applying diffusion probabilistic models (also known as diffusion models) to generate high-quality synthetic weed images based on transfer learning. Comprehensive experimental results show that the developed approach consistently outperforms several state-of-the-art GAN models, representing the best trade-off between sample fidelity and diversity and highest FID score on a common weed dataset, CottonWeedID15. In addition, the expanding dataset with synthetic weed images can apparently boost model performance on four deep learning (DL) models for the weed classification tasks. Furthermore, the DL models trained on CottonWeedID15 dataset with only 10% of real images and 90% of synthetic weed images achieve a testing accuracy of over 94%, showing high-quality of the generated weed samples. The codes of this study are made publicly available at https://github.com/DongChen06/DMWeeds.