 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Safe Multi-Agent Control with Decentralized Neural Barrier Certificates
Jan 31, 2021

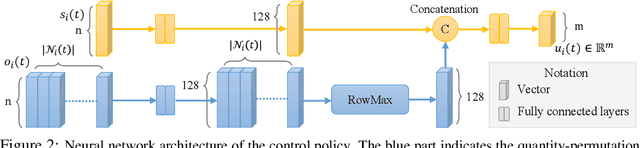
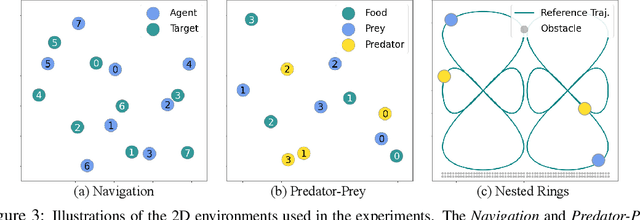
We study the multi-agent safe control problem where agents should avoid collisions to static obstacles and collisions with each other while reaching their goals. Our core idea is to learn the multi-agent control policy jointly with learning the control barrier functions as safety certificates. We propose a novel joint-learning framework that can be implemented in a decentralized fashion, with generalization guarantees for certain function classes. Such a decentralized framework can adapt to an arbitrarily large number of agents. Building upon this framework, we further improve the scalability by incorporating neural network architectures that are invariant to the quantity and permutation of neighboring agents. In addition, we propose a new spontaneous policy refinement method to further enforce the certificate condition during testing. We provide extensive experiments to demonstrate that our method significantly outperforms other leading multi-agent control approaches in terms of maintaining safety and completing original tasks. Our approach also shows exceptional generalization capability in that the control policy can be trained with 8 agents in one scenario, while being used on other scenarios with up to 1024 agents in complex multi-agent environments and dynamics.
Weakly Supervised 3D Object Detection from Point Clouds
Jul 28, 2020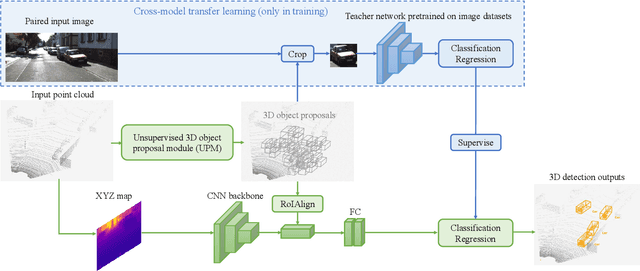
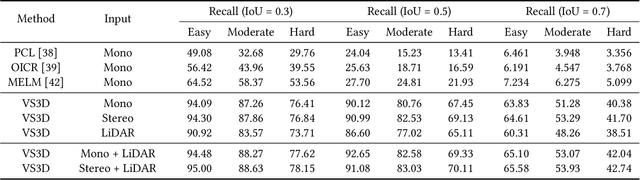
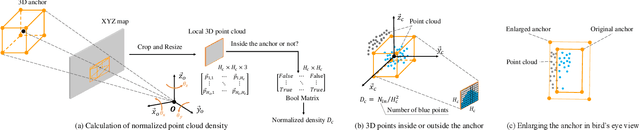
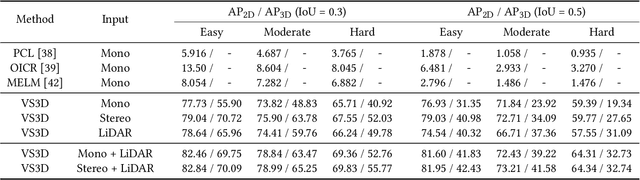
A crucial task in scene understanding is 3D object detection, which aims to detect and localize the 3D bounding boxes of objects belonging to specific classes. Existing 3D object detectors heavily rely on annotated 3D bounding boxes during training, while these annotations could be expensive to obtain and only accessible in limited scenarios. Weakly supervised learning is a promising approach to reducing the annotation requirement, but existing weakly supervised object detectors are mostly for 2D detection rather than 3D. In this work, we propose VS3D, a framework for weakly supervised 3D object detection from point clouds without using any ground truth 3D bounding box for training. First, we introduce an unsupervised 3D proposal module that generates object proposals by leveraging normalized point cloud densities. Second, we present a cross-modal knowledge distillation strategy, where a convolutional neural network learns to predict the final results from the 3D object proposals by querying a teacher network pretrained on image datasets. Comprehensive experiments on the challenging KITTI dataset demonstrate the superior performance of our VS3D in diverse evaluation settings. The source code and pretrained models are publicly available at https://github.com/Zengyi-Qin/Weakly-Supervised-3D-Object-Detection.
KETO: Learning Keypoint Representations for Tool Manipulation
Oct 30, 2019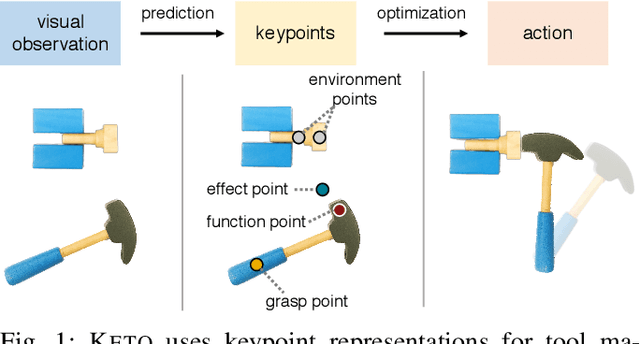
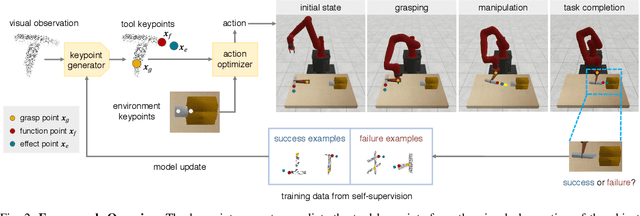
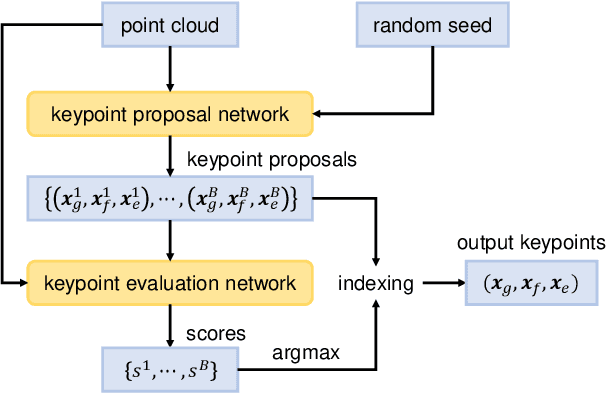
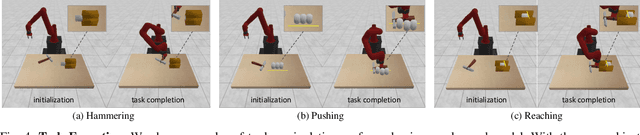
We aim to develop an algorithm for robots to manipulate novel objects as tools for completing different task goals. An efficient and informative representation would facilitate the effectiveness and generalization of such algorithms. For this purpose, we present KETO, a framework of learning keypoint representations of tool-based manipulation. For each task, a set of task-specific keypoints is jointly predicted from 3D point clouds of the tool object by a deep neural network. These keypoints offer a concise and informative description of the object to determine grasps and subsequent manipulation actions. The model is learned from self-supervised robot interactions in the task environment without the need for explicit human annotations. We evaluate our framework in three manipulation tasks with tool use. Our model consistently outperforms state-of-the-art methods in terms of task success rates. Qualitative results of keypoint prediction and tool generation are shown to visualize the learned representations.
Triangulation Learning Network: from Monocular to Stereo 3D Object Detection
Jun 04, 2019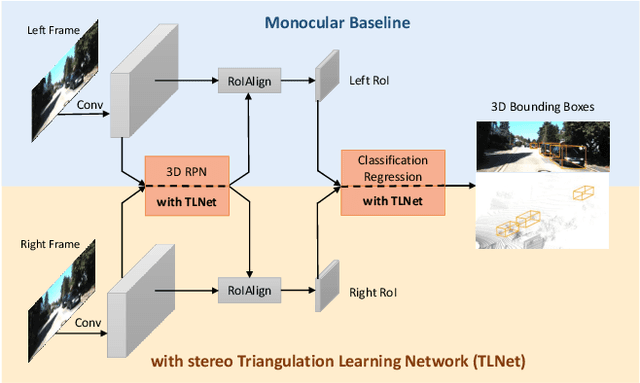
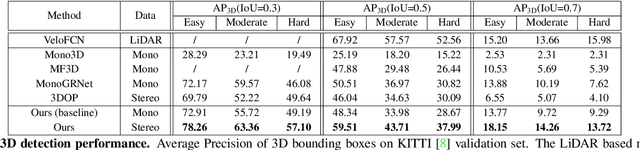
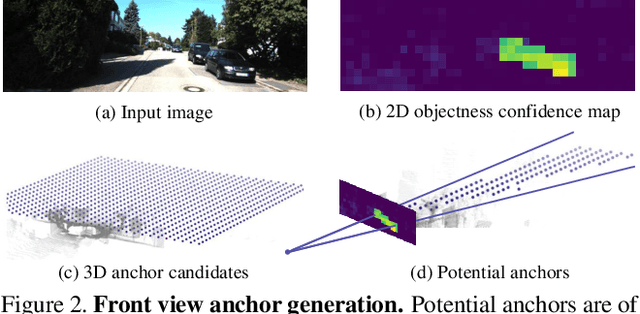
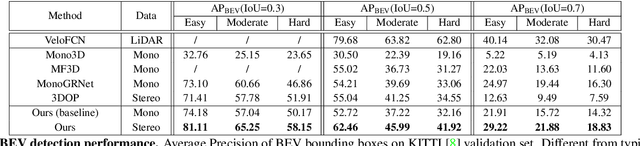
In this paper, we study the problem of 3D object detection from stereo images, in which the key challenge is how to effectively utilize stereo information. Different from previous methods using pixel-level depth maps, we propose employing 3D anchors to explicitly construct object-level correspondences between the regions of interest in stereo images, from which the deep neural network learns to detect and triangulate the targeted object in 3D space. We also introduce a cost-efficient channel reweighting strategy that enhances representational features and weakens noisy signals to facilitate the learning process. All of these are flexibly integrated into a solid baseline detector that uses monocular images. We demonstrate that both the monocular baseline and the stereo triangulation learning network outperform the prior state-of-the-arts in 3D object detection and localization on the challenging KITTI dataset.
MonoGRNet: A Geometric Reasoning Network for Monocular 3D Object Localization
Nov 26, 2018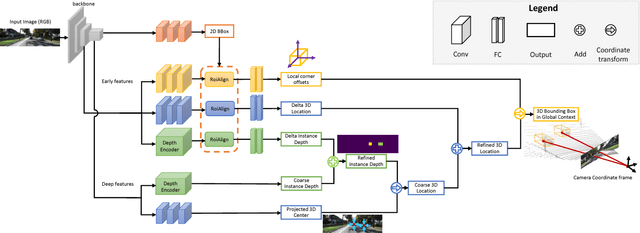

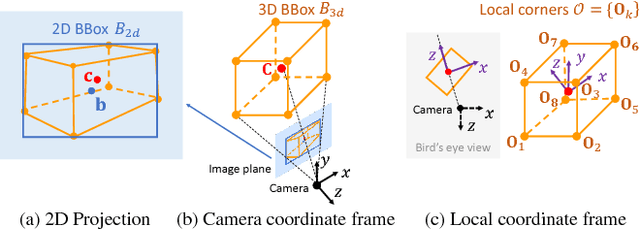
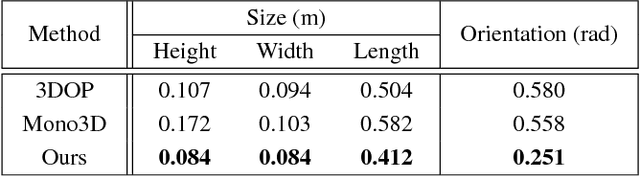
Localizing objects in the real 3D space, which plays a crucial role in scene understanding, is particularly challenging given only a single RGB image due to the geometric information loss during imagery projection. We propose MonoGRNet for the amodal 3D object localization from a monocular RGB image via geometric reasoning in both the observed 2D projection and the unobserved depth dimension. MonoGRNet is a single, unified network composed of four task-specific subnetworks, responsible for 2D object detection, instance depth estimation (IDE), 3D localization and local corner regression. Unlike the pixel-level depth estimation that needs per-pixel annotations, we propose a novel IDE method that directly predicts the depth of the targeting 3D bounding box's center using sparse supervision. The 3D localization is further achieved by estimating the position in the horizontal and vertical dimensions. Finally, MonoGRNet is jointly learned by optimizing the locations and poses of the 3D bounding boxes in the global context. We demonstrate that MonoGRNet achieves state-of-the-art performance on challenging datasets.