 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent prospector v2.0: exploration drill planning under epistemic model uncertainty
Oct 14, 2024



Optimal Bayesian decision making on what geoscientific data to acquire requires stating a prior model of uncertainty. Data acquisition is then optimized by reducing uncertainty on some property of interest maximally, and on average. In the context of exploration, very few, sometimes no data at all, is available prior to data acquisition planning. The prior model therefore needs to include human interpretations on the nature of spatial variability, or on analogue data deemed relevant for the area being explored. In mineral exploration, for example, humans may rely on conceptual models on the genesis of the mineralization to define multiple hypotheses, each representing a specific spatial variability of mineralization. More often than not, after the data is acquired, all of the stated hypotheses may be proven incorrect, i.e. falsified, hence prior hypotheses need to be revised, or additional hypotheses generated. Planning data acquisition under wrong geological priors is likely to be inefficient since the estimated uncertainty on the target property is incorrect, hence uncertainty may not be reduced at all. In this paper, we develop an intelligent agent based on partially observable Markov decision processes that plans optimally in the case of multiple geological or geoscientific hypotheses on the nature of spatial variability. Additionally, the artificial intelligence is equipped with a method that allows detecting, early on, whether the human stated hypotheses are incorrect, thereby saving considerable expense in data acquisition. Our approach is tested on a sediment-hosted copper deposit, and the algorithm presented has aided in the characterization of an ultra high-grade deposit in Zambia in 2023.
Autonomous Attack Mitigation for Industrial Control Systems
Nov 03, 2021

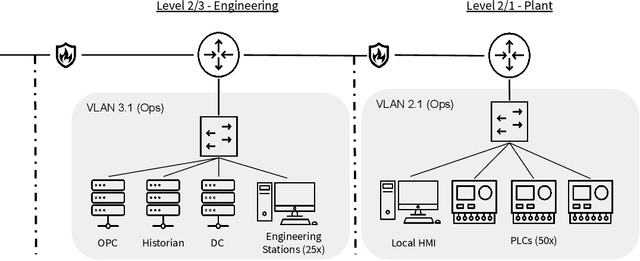

Defending computer networks from cyber attack requires timely responses to alerts and threat intelligence. Decisions about how to respond involve coordinating actions across multiple nodes based on imperfect indicators of compromise while minimizing disruptions to network operations. Currently, playbooks are used to automate portions of a response process, but often leave complex decision-making to a human analyst. In this work, we present a deep reinforcement learning approach to autonomous response and recovery in large industrial control networks. We propose an attention-based neural architecture that is flexible to the size of the network under protection. To train and evaluate the autonomous defender agent, we present an industrial control network simulation environment suitable for reinforcement learning. Experiments show that the learned agent can effectively mitigate advanced attacks that progress with few observable signals over several months before execution. The proposed deep reinforcement learning approach outperforms a fully automated playbook method in simulation, taking less disruptive actions while also defending more nodes on the network. The learned policy is also more robust to changes in attacker behavior than playbook approaches.
Interpretable Local Tree Surrogate Policies
Sep 16, 2021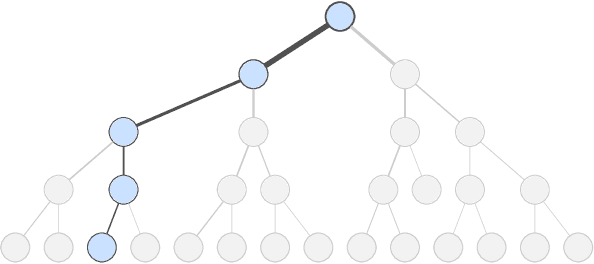
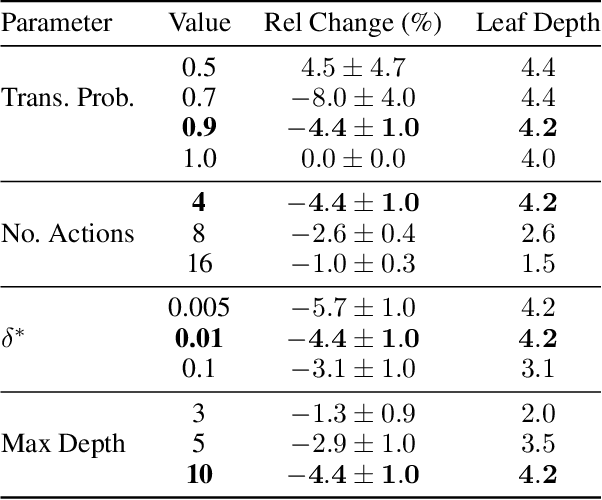
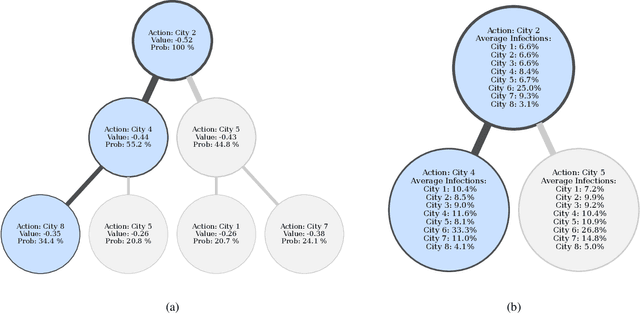
High-dimensional policies, such as those represented by neural networks, cannot be reasonably interpreted by humans. This lack of interpretability reduces the trust users have in policy behavior, limiting their use to low-impact tasks such as video games. Unfortunately, many methods rely on neural network representations for effective learning. In this work, we propose a method to build predictable policy trees as surrogates for policies such as neural networks. The policy trees are easily human interpretable and provide quantitative predictions of future behavior. We demonstrate the performance of this approach on several simulated tasks.
Reinforcement Learning for Industrial Control Network Cyber Security Orchestration
Jun 09, 2021
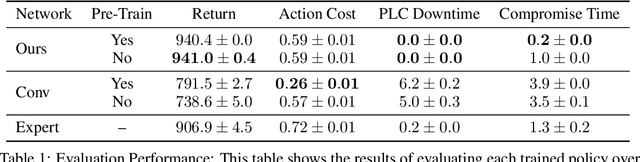
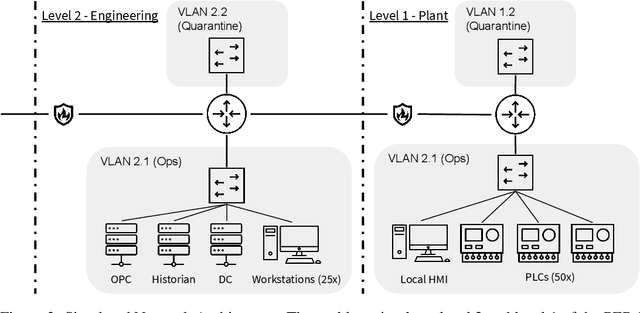
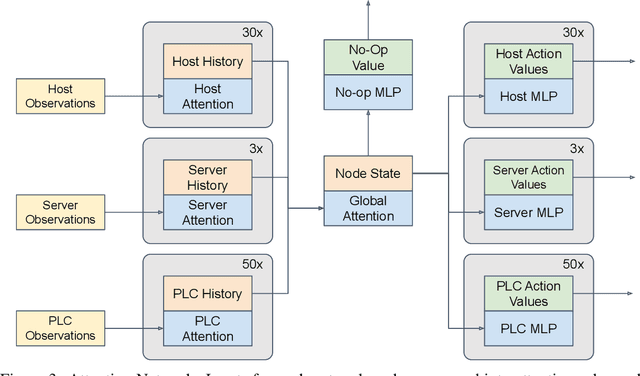
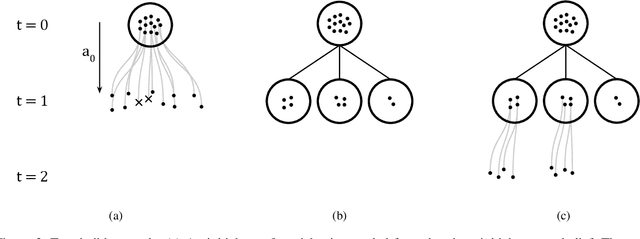
Defending computer networks from cyber attack requires coordinating actions across multiple nodes based on imperfect indicators of compromise while minimizing disruptions to network operations. Advanced attacks can progress with few observable signals over several months before execution. The resulting sequential decision problem has large observation and action spaces and a long time-horizon, making it difficult to solve with existing methods. In this work, we present techniques to scale deep reinforcement learning to solve the cyber security orchestration problem for large industrial control networks. We propose a novel attention-based neural architecture with size complexity that is invariant to the size of the network under protection. A pre-training curriculum is presented to overcome early exploration difficulty. Experiments show in that the proposed approaches greatly improve both the learning sample complexity and converged policy performance over baseline methods in simulation.
Measurable Monte Carlo Search Error Bounds
Jun 08, 2021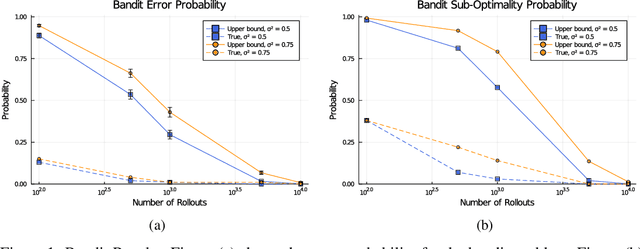
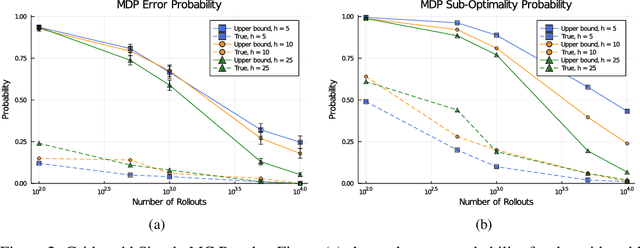
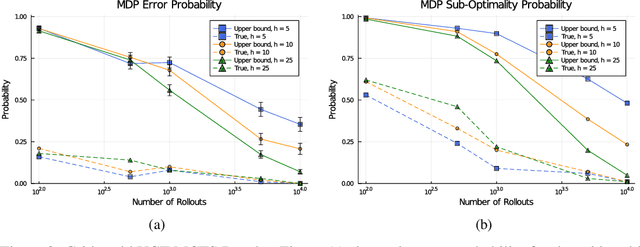
Monte Carlo planners can often return sub-optimal actions, even if they are guaranteed to converge in the limit of infinite samples. Known asymptotic regret bounds do not provide any way to measure confidence of a recommended action at the conclusion of search. In this work, we prove bounds on the sub-optimality of Monte Carlo estimates for non-stationary bandits and Markov decision processes. These bounds can be directly computed at the conclusion of the search and do not require knowledge of the true action-value. The presented bound holds for general Monte Carlo solvers meeting mild convergence conditions. We empirically test the tightness of the bounds through experiments on a multi-armed bandit and a discrete Markov decision process for both a simple solver and Monte Carlo tree search.
Obstacle Avoidance Using a Monocular Camera
Dec 03, 2020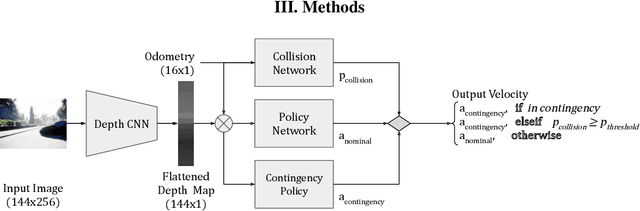
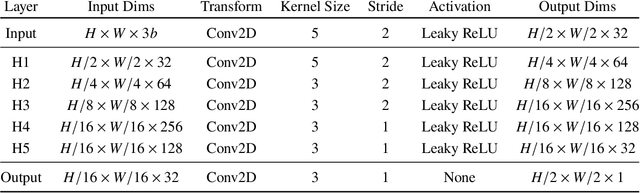

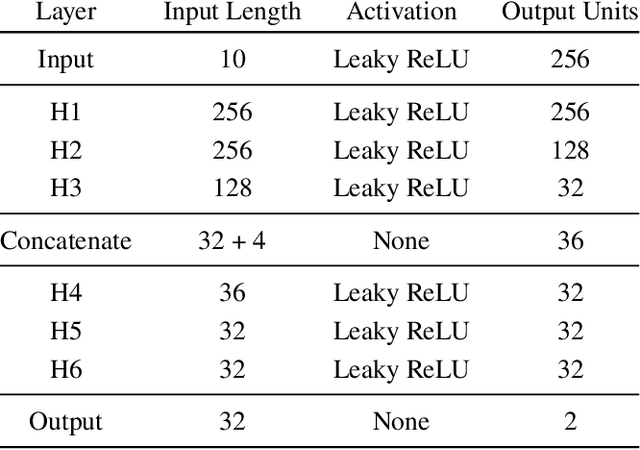
A collision avoidance system based on simple digital cameras would help enable the safe integration of small UAVs into crowded, low-altitude environments. In this work, we present an obstacle avoidance system for small UAVs that uses a monocular camera with a hybrid neural network and path planner controller. The system is comprised of a vision network for estimating depth from camera images, a high-level control network, a collision prediction network, and a contingency policy. This system is evaluated on a simulated UAV navigating an obstacle course in a constrained flight pattern. Results show the proposed system achieves low collision rates while maintaining operationally relevant flight speeds.
Improved POMDP Tree Search Planning with Prioritized Action Branching
Oct 07, 2020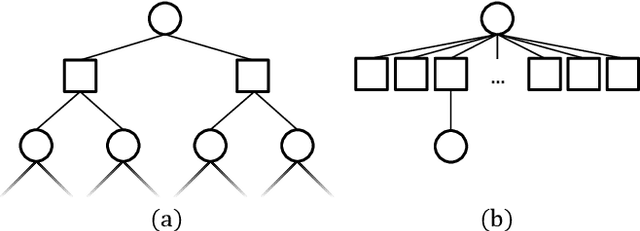
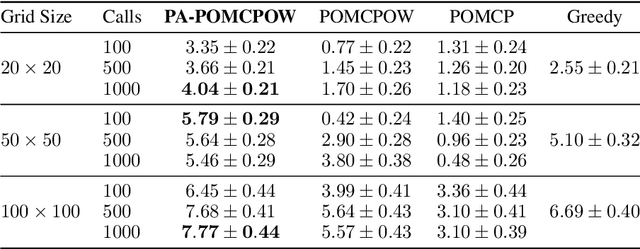
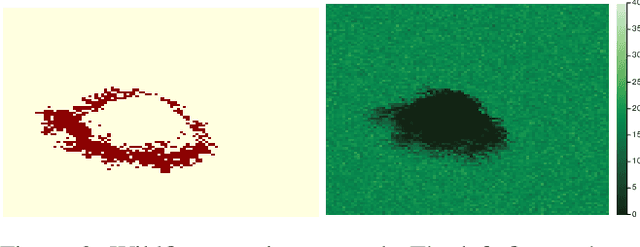
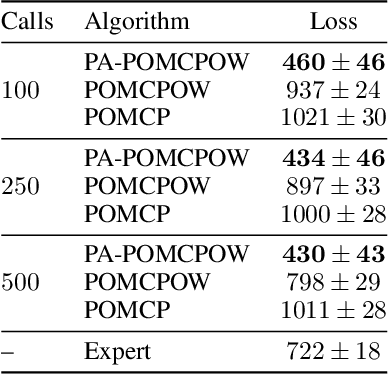
Online solvers for partially observable Markov decision processes have difficulty scaling to problems with large action spaces. This paper proposes a method called PA-POMCPOW to sample a subset of the action space that provides varying mixtures of exploitation and exploration for inclusion in a search tree. The proposed method first evaluates the action space according to a score function that is a linear combination of expected reward and expected information gain. The actions with the highest score are then added to the search tree during tree expansion. Experiments show that PA-POMCPOW is able to outperform existing state-of-the-art solvers on problems with large discrete action spaces.
Bayesian Optimized Monte Carlo Planning
Oct 07, 2020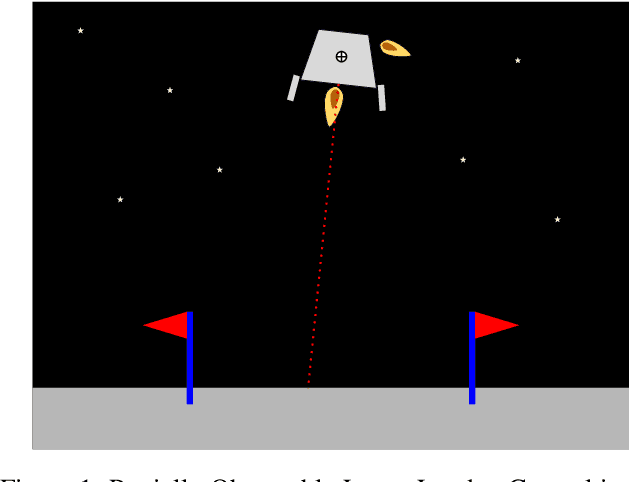
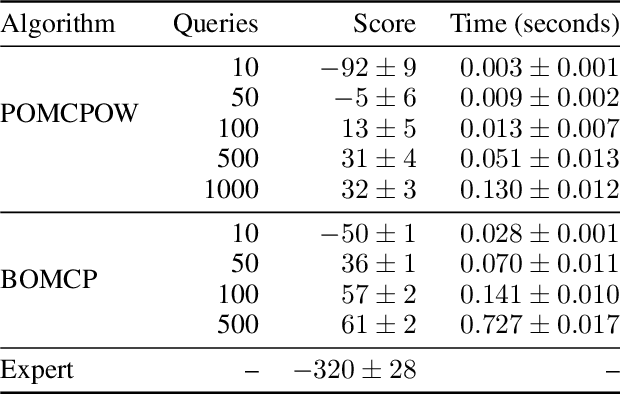
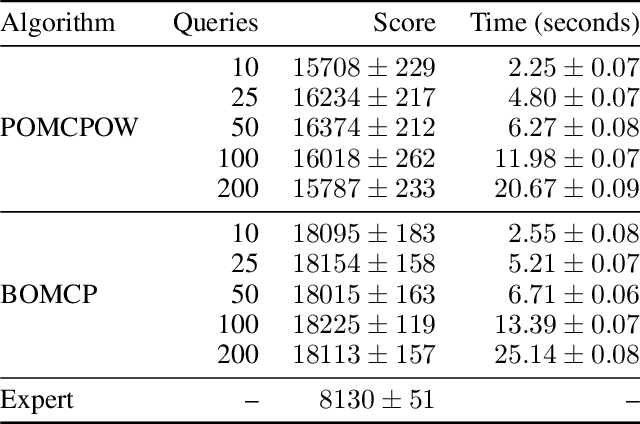
Online solvers for partially observable Markov decision processes have difficulty scaling to problems with large action spaces. Monte Carlo tree search with progressive widening attempts to improve scaling by sampling from the action space to construct a policy search tree. The performance of progressive widening search is dependent upon the action sampling policy, often requiring problem-specific samplers. In this work, we present a general method for efficient action sampling based on Bayesian optimization. The proposed method uses a Gaussian process to model a belief over the action-value function and selects the action that will maximize the expected improvement in the optimal action value. We implement the proposed approach in a new online tree search algorithm called Bayesian Optimized Monte Carlo Planning (BOMCP). Several experiments show that BOMCP is better able to scale to large action space POMDPs than existing state-of-the-art tree search solvers.
Towards Recurrent Autoregressive Flow Models
Jun 17, 2020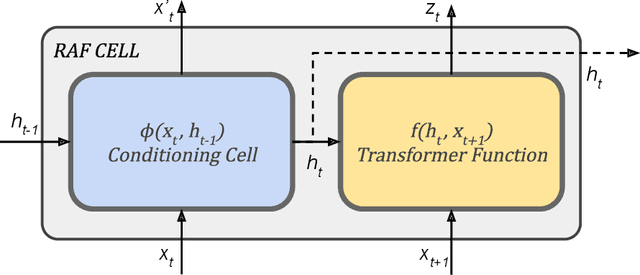

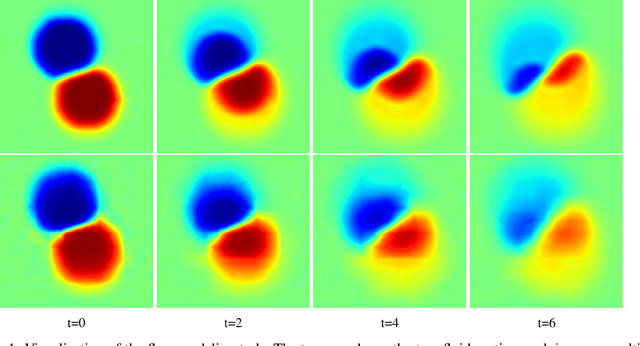
Stochastic processes generated by non-stationary distributions are difficult to represent with conventional models such as Gaussian processes. This work presents Recurrent Autoregressive Flows as a method toward general stochastic process modeling with normalizing flows. The proposed method defines a conditional distribution for each variable in a sequential process by conditioning the parameters of a normalizing flow with recurrent neural connections. Complex conditional relationships are learned through the recurrent network parameters. In this work, we present an initial design for a recurrent flow cell and a method to train the model to match observed empirical distributions. We demonstrate the effectiveness of this class of models through a series of experiments in which models are trained on three complex stochastic processes. We highlight the shortcomings of our current formulation and suggest some potential solutions.
Exchangeable Input Representations for Reinforcement Learning
Mar 19, 2020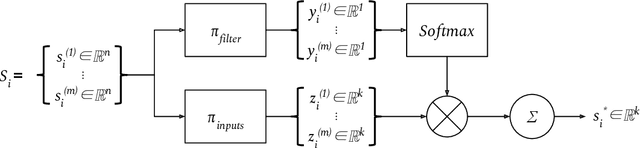
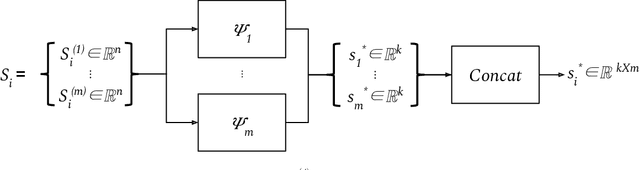
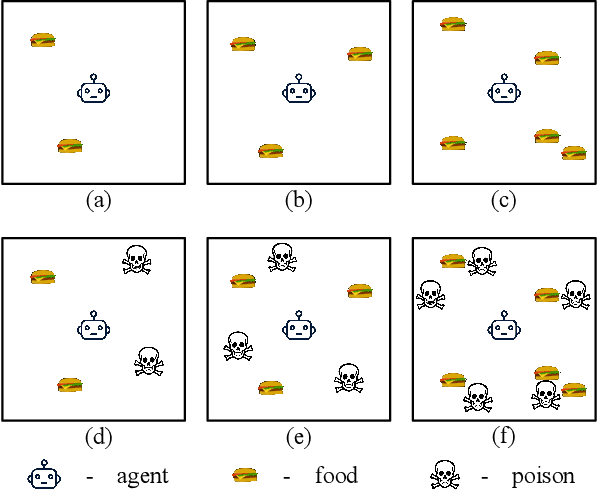

Poor sample efficiency is a major limitation of deep reinforcement learning in many domains. This work presents an attention-based method to project neural network inputs into an efficient representation space that is invariant under changes to input ordering. We show that our proposed representation results in an input space that is a factor of $m!$ smaller for inputs of $m$ objects. We also show that our method is able to represent inputs over variable numbers of objects. Our experiments demonstrate improvements in sample efficiency for policy gradient methods on a variety of tasks. We show that our representation allows us to solve problems that are otherwise intractable when using na\"ive approaches.