 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaomi MiMo-VL-Miloco Technical Report
Dec 22, 2025



We open-source MiMo-VL-Miloco-7B and its quantized variant MiMo-VL-Miloco-7B-GGUF, a pair of home-centric vision-language models that achieve strong performance on both home-scenario understanding and general multimodal reasoning. Built on the MiMo-VL-7B backbone, MiMo-VL-Miloco-7B is specialized for smart-home environments, attaining leading F1 scores on gesture recognition and common home-scenario understanding, while also delivering consistent gains across video benchmarks such as Video-MME, Video-MMMU, and Charades-STA, as well as language understanding benchmarks including MMMU-Pro and MMLU-Pro. In our experiments, MiMo-VL-Miloco-7B outperforms strong closed-source and open-source baselines on home-scenario understanding and several multimodal reasoning benchmarks. To balance specialization and generality, we design a two-stage training pipeline that combines supervised fine-tuning with reinforcement learning based on Group Relative Policy Optimization, leveraging efficient multi-domain data. We further incorporate chain-of-thought supervision and token-budget-aware reasoning, enabling the model to learn knowledge in a data-efficient manner while also performing reasoning efficiently. Our analysis shows that targeted home-scenario training not only enhances activity and gesture understanding, but also improves text-only reasoning with only modest trade-offs on document-centric tasks. Model checkpoints, quantized GGUF weights, and our home-scenario evaluation toolkit are publicly available at https://github.com/XiaoMi/xiaomi-mimo-vl-miloco to support research and deployment in real-world smart-home applications.
REVISOR: Beyond Textual Reflection, Towards Multimodal Introspective Reasoning in Long-Form Video Understanding
Nov 17, 2025Self-reflection mechanisms that rely on purely text-based rethinking processes perform well in most multimodal tasks. However, when directly applied to long-form video understanding scenarios, they exhibit clear limitations. The fundamental reasons for this lie in two points: (1)long-form video understanding involves richer and more dynamic visual input, meaning rethinking only the text information is insufficient and necessitates a further rethinking process specifically targeting visual information; (2) purely text-based reflection mechanisms lack cross-modal interaction capabilities, preventing them from fully integrating visual information during reflection. Motivated by these insights, we propose REVISOR (REflective VIsual Segment Oriented Reasoning), a novel framework for tool-augmented multimodal reflection. REVISOR enables MLLMs to collaboratively construct introspective reflection processes across textual and visual modalities, significantly enhancing their reasoning capability for long-form video understanding. To ensure that REVISOR can learn to accurately review video segments highly relevant to the question during reinforcement learning, we designed the Dual Attribution Decoupled Reward (DADR) mechanism. Integrated into the GRPO training strategy, this mechanism enforces causal alignment between the model's reasoning and the selected video evidence. Notably, the REVISOR framework significantly enhances long-form video understanding capability of MLLMs without requiring supplementary supervised fine-tuning or external models, achieving impressive results on four benchmarks including VideoMME, LongVideoBench, MLVU, and LVBench.
AdaptGCD: Multi-Expert Adapter Tuning for Generalized Category Discovery
Oct 29, 2024Different from the traditional semi-supervised learning paradigm that is constrained by the close-world assumption, Generalized Category Discovery (GCD) presumes that the unlabeled dataset contains new categories not appearing in the labeled set, and aims to not only classify old categories but also discover new categories in the unlabeled data. Existing studies on GCD typically devote to transferring the general knowledge from the self-supervised pretrained model to the target GCD task via some fine-tuning strategies, such as partial tuning and prompt learning. Nevertheless, these fine-tuning methods fail to make a sound balance between the generalization capacity of pretrained backbone and the adaptability to the GCD task. To fill this gap, in this paper, we propose a novel adapter-tuning-based method named AdaptGCD, which is the first work to introduce the adapter tuning into the GCD task and provides some key insights expected to enlighten future research. Furthermore, considering the discrepancy of supervision information between the old and new classes, a multi-expert adapter structure equipped with a route assignment constraint is elaborately devised, such that the data from old and new classes are separated into different expert groups. Extensive experiments are conducted on 7 widely-used datasets. The remarkable improvements in performance highlight the effectiveness of our proposals.
MEPG: A Minimalist Ensemble Policy Gradient Framework for Deep Reinforcement Learning
Sep 22, 2021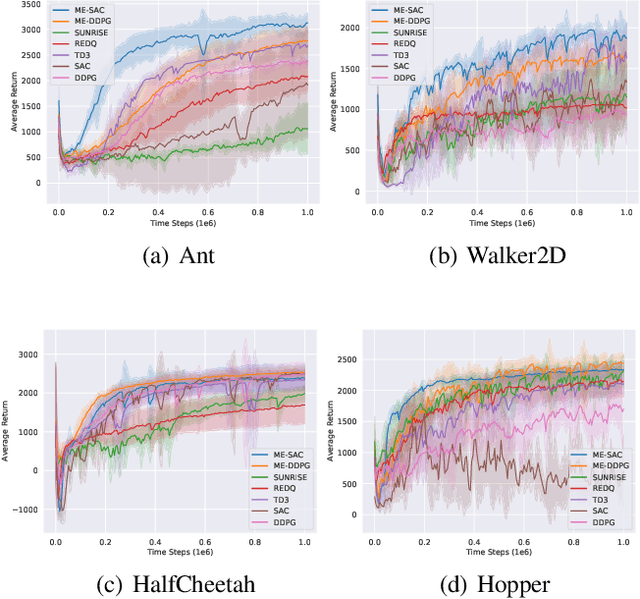
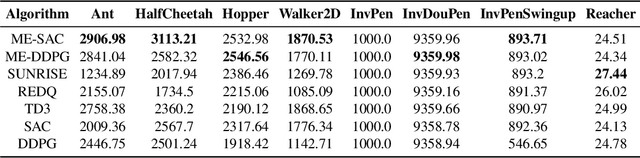
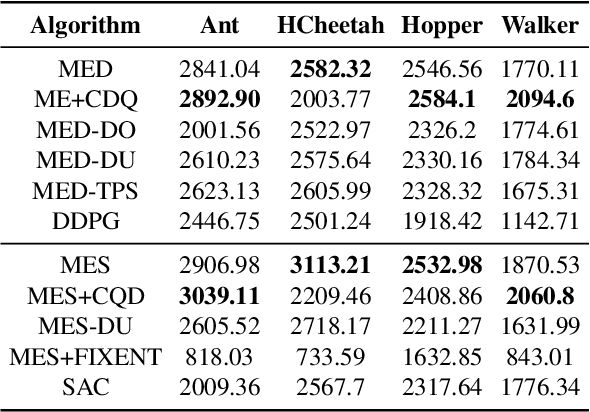
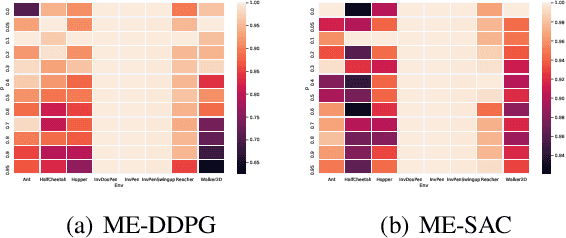
Ensemble reinforcement learning (RL) aims to mitigate instability in Q-learning and to learn a robust policy, which introduces multiple value and policy functions. In this paper, we consider finding a novel but simple ensemble Deep RL algorithm to solve the resource consumption issue. Specifically, we consider integrating multiple models into a single model. To this end, we propose the \underline{M}inimalist \underline{E}nsemble \underline{P}olicy \underline{G}radient framework (MEPG), which introduces minimalist ensemble consistent Bellman update. And we find one value network is sufficient in our framework. Moreover, we theoretically show that the policy evaluation phase in the MEPG is mathematically equivalent to a deep Gaussian Process. To verify the effectiveness of the MEPG framework, we conduct experiments on the gym simulator, which show that the MEPG framework matches or outperforms the state-of-the-art ensemble methods and model-free methods without additional computational resource costs.