 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSpeed Data Efficiency: Improving Deep Learning Model Quality and Training Efficiency via Efficient Data Sampling and Routing
Dec 07, 2022



Recent advances on deep learning models come at the price of formidable training cost. The increasing model size is one of the root cause, but another less-emphasized fact is that data scale is actually increasing at a similar speed as model scale, and the training cost is proportional to both of them. Compared to the rapidly evolving model architecture, how to efficiently use the training data (especially for the expensive foundation model pertaining) is both less explored and difficult to realize due to the lack of a convenient framework that focus on data efficiency capabilities. To this end, we present DeepSpeed Data Efficiency library, a framework that makes better use of data, increases training efficiency, and improves model quality. Specifically, it provides efficient data sampling via curriculum learning, and efficient data routing via random layerwise token dropping. DeepSpeed Data Efficiency takes extensibility, flexibility and composability into consideration, so that users can easily utilize the framework to compose multiple techniques and apply customized strategies. By applying our solution to GPT-3 1.3B and BERT-Large language model pretraining, we can achieve similar model quality with up to 2x less data and 2x less time, or achieve better model quality under similar amount of data and time.
Random-LTD: Random and Layerwise Token Dropping Brings Efficient Training for Large-scale Transformers
Nov 17, 2022



Large-scale transformer models have become the de-facto architectures for various machine learning applications, e.g., CV and NLP. However, those large models also introduce prohibitive training costs. To mitigate this issue, we propose a novel random and layerwise token dropping method (random-LTD), which skips the computation of a subset of the input tokens at all middle layers. Particularly, random-LTD achieves considerable speedups and comparable accuracy as the standard training baseline. Compared to other token dropping methods, random-LTD does not require (1) any importance score-based metrics, (2) any special token treatment (e.g., [CLS]), and (3) many layers in full sequence length training except the first and the last layers. Besides, a new LayerToken learning rate schedule is proposed for pretraining problems that resolve the heavy tuning requirement for our proposed training mechanism. Finally, we demonstrate that random-LTD can be applied to broader applications, including GPT and BERT pretraining as well as ViT and GPT finetuning tasks. Our results show that random-LTD can save about 33.3% theoretical compute cost and 25.6% wall-clock training time while achieving similar zero-shot evaluations on GPT-31.3B as compared to baseline.
BiFeat: Supercharge GNN Training via Graph Feature Quantization
Jul 29, 2022



Graph Neural Networks (GNNs) is a promising approach for applications with nonEuclidean data. However, training GNNs on large scale graphs with hundreds of millions nodes is both resource and time consuming. Different from DNNs, GNNs usually have larger memory footprints, and thus the GPU memory capacity and PCIe bandwidth are the main resource bottlenecks in GNN training. To address this problem, we present BiFeat: a graph feature quantization methodology to accelerate GNN training by significantly reducing the memory footprint and PCIe bandwidth requirement so that GNNs can take full advantage of GPU computing capabilities. Our key insight is that unlike DNN, GNN is less prone to the information loss of input features caused by quantization. We identify the main accuracy impact factors in graph feature quantization and theoretically prove that BiFeat training converges to a network where the loss is within $\epsilon$ of the optimal loss of uncompressed network. We perform extensive evaluation of BiFeat using several popular GNN models and datasets, including GraphSAGE on MAG240M, the largest public graph dataset. The results demonstrate that BiFeat achieves a compression ratio of more than 30 and improves GNN training speed by 200%-320% with marginal accuracy loss. In particular, BiFeat achieves a record by training GraphSAGE on MAG240M within one hour using only four GPUs.
DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale
Jun 30, 2022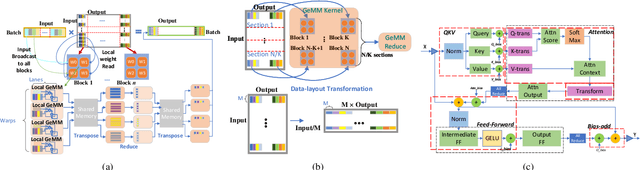
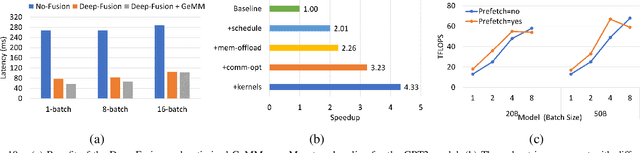
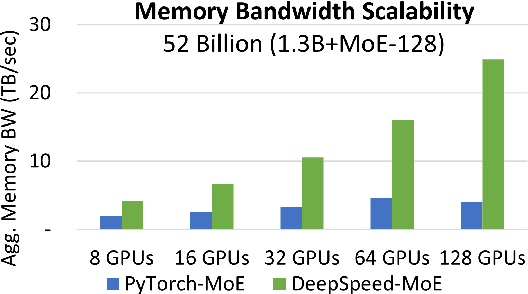
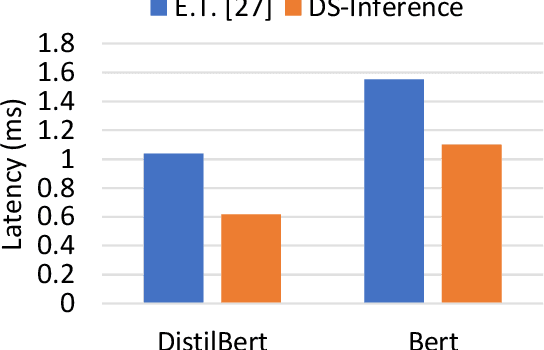
The past several years have witnessed the success of transformer-based models, and their scale and application scenarios continue to grow aggressively. The current landscape of transformer models is increasingly diverse: the model size varies drastically with the largest being of hundred-billion parameters; the model characteristics differ due to the sparsity introduced by the Mixture-of-Experts; the target application scenarios can be latency-critical or throughput-oriented; the deployment hardware could be single- or multi-GPU systems with different types of memory and storage, etc. With such increasing diversity and the fast-evolving pace of transformer models, designing a highly performant and efficient inference system is extremely challenging. In this paper, we present DeepSpeed Inference, a comprehensive system solution for transformer model inference to address the above-mentioned challenges. DeepSpeed Inference consists of (1) a multi-GPU inference solution to minimize latency while maximizing the throughput of both dense and sparse transformer models when they fit in aggregate GPU memory, and (2) a heterogeneous inference solution that leverages CPU and NVMe memory in addition to the GPU memory and compute to enable high inference throughput with large models which do not fit in aggregate GPU memory. DeepSpeed Inference reduces latency by up to 7.3X over the state-of-the-art for latency-oriented scenarios and increases throughput by over 1.5x for throughput-oriented scenarios. Moreover, it enables trillion parameter scale inference under real-time latency constraints by leveraging hundreds of GPUs, an unprecedented scale for inference. It can inference 25x larger models than with GPU-only solutions, while delivering a high throughput of 84 TFLOPS (over $50\%$ of A6000 peak).
Compressing Pre-trained Transformers via Low-Bit NxM Sparsity for Natural Language Understanding
Jun 30, 2022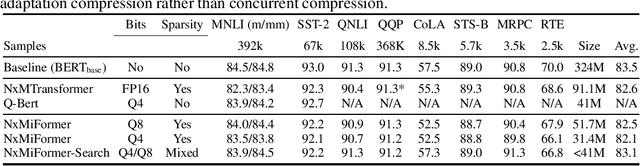
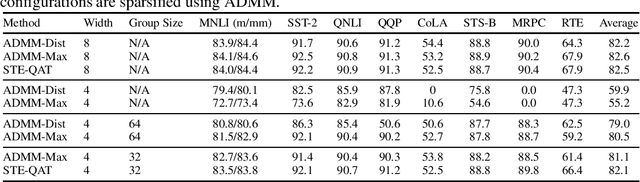

In recent years, large pre-trained Transformer networks have demonstrated dramatic improvements in many natural language understanding tasks. However, the huge size of these models brings significant challenges to their fine-tuning and online deployment due to latency and cost constraints. New hardware supporting both N:M semi-structured sparsity and low-precision integer computation is a promising solution to boost DNN model serving efficiency. However, there have been very few studies that systematically investigate to what extent pre-trained Transformer networks benefit from the combination of these techniques, as well as how to best compress each component of the Transformer. We propose a flexible compression framework NxMiFormer that performs simultaneous sparsification and quantization using ADMM and STE-based QAT. Furthermore, we present and inexpensive, heuristic-driven search algorithm that identifies promising heterogeneous compression configurations that meet a compression ratio constraint. When evaluated across the GLUE suite of NLU benchmarks, our approach can achieve up to 93% compression of the encoders of a BERT model while retaining 98.2% of the original model accuracy and taking full advantage of the hardware's capabilities. Heterogeneous configurations found the by the search heuristic maintain 99.5% of the baseline accuracy while still compressing the model by 87.5%.
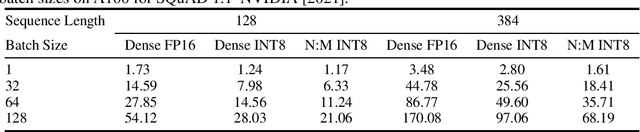
ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
Jun 04, 2022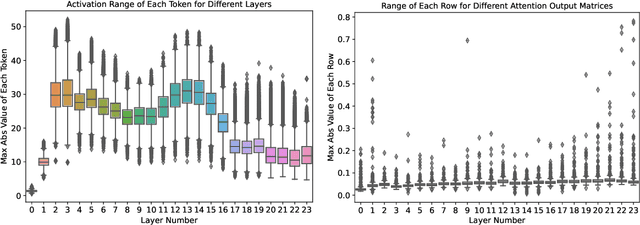



How to efficiently serve ever-larger trained natural language models in practice has become exceptionally challenging even for powerful cloud servers due to their prohibitive memory/computation requirements. In this work, we present an efficient and affordable post-training quantization approach to compress large Transformer-based models, termed as ZeroQuant. ZeroQuant is an end-to-end quantization and inference pipeline with three main components: (1) a fine-grained hardware-friendly quantization scheme for both weight and activations; (2) a novel affordable layer-by-layer knowledge distillation algorithm (LKD) even without the access to the original training data; (3) a highly-optimized quantization system backend support to remove the quantization/dequantization overhead. As such, we are able to show that: (1) ZeroQuant can reduce the precision for weights and activations to INT8 in a cost-free way for both BERT and GPT3-style models with minimal accuracy impact, which leads to up to 5.19x/4.16x speedup on those models compared to FP16 inference; (2) ZeroQuant plus LKD affordably quantize the weights in the fully-connected module to INT4 along with INT8 weights in the attention module and INT8 activations, resulting in 3x memory footprint reduction compared to the FP16 model; (3) ZeroQuant can be directly applied to two of the largest open-sourced language models, including GPT-J6B and GPT-NeoX20, for which our INT8 model achieves similar accuracy as the FP16 model but achieves up to 5.2x better efficiency.
Extreme Compression for Pre-trained Transformers Made Simple and Efficient
Jun 04, 2022

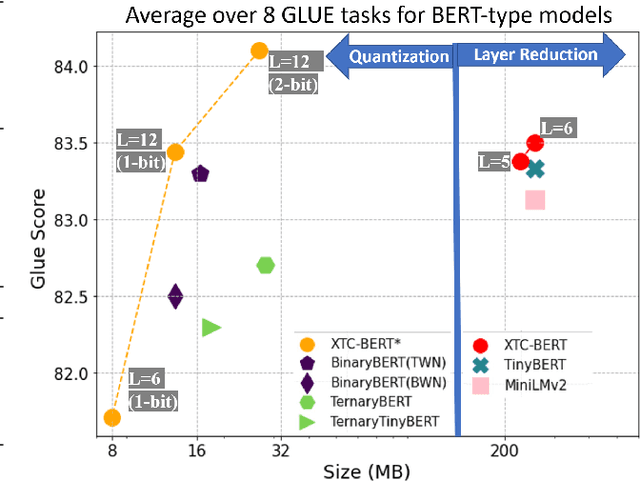

Extreme compression, particularly ultra-low bit precision (binary/ternary) quantization, has been proposed to fit large NLP models on resource-constraint devices. However, to preserve the accuracy for such aggressive compression schemes, cutting-edge methods usually introduce complicated compression pipelines, e.g., multi-stage expensive knowledge distillation with extensive hyperparameter tuning. Also, they oftentimes focus less on smaller transformer models that have already been heavily compressed via knowledge distillation and lack a systematic study to show the effectiveness of their methods. In this paper, we perform a very comprehensive systematic study to measure the impact of many key hyperparameters and training strategies from previous works. As a result, we find out that previous baselines for ultra-low bit precision quantization are significantly under-trained. Based on our study, we propose a simple yet effective compression pipeline for extreme compression, named XTC. XTC demonstrates that (1) we can skip the pre-training knowledge distillation to obtain a 5-layer BERT while achieving better performance than previous state-of-the-art methods, e.g., the 6-layer TinyBERT; (2) extreme quantization plus layer reduction is able to reduce the model size by 50x, resulting in new state-of-the-art results on GLUE tasks.
Maximizing Communication Efficiency for Large-scale Training via 0/1 Adam
Feb 12, 2022

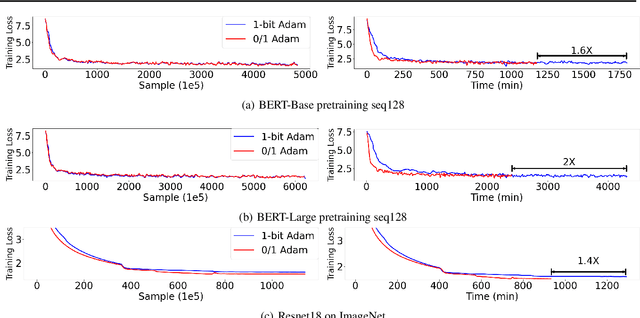
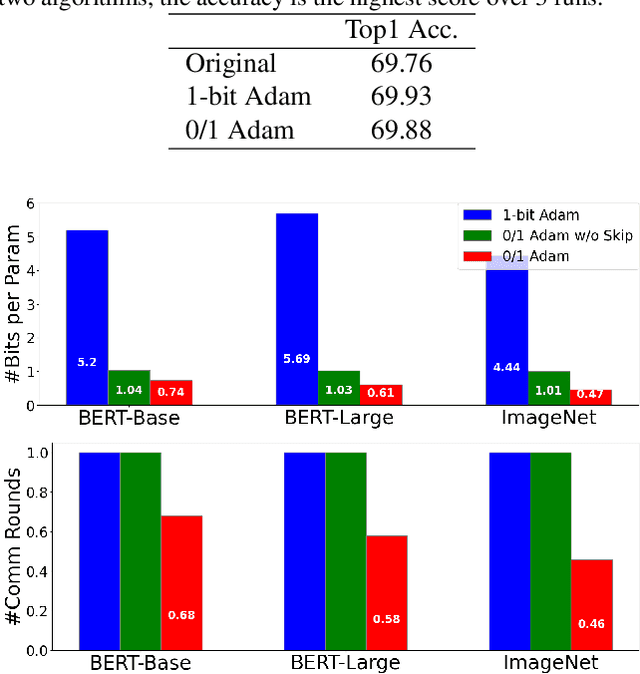
1-bit communication is an effective method to scale up model training, and has been studied extensively on SGD. Its benefits, however, remain an open question on Adam-based model training (e.g. BERT and GPT). In this paper, we propose 0/1 Adam, which improves upon the state-of-the-art 1-bit Adam via two novel designs: (1) adaptive variance state freezing, which eliminates the requirement of running expensive full-precision communication at early stage of training; (2) 1-bit sync, which allows skipping communication rounds with bit-free synchronization over Adam's optimizer states, momentum and variance. In theory, we provide convergence analysis for 0/1 Adam on smooth non-convex objectives, and show the complexity bound is better than original Adam under certain conditions. On various benchmarks such as BERT-Base/Large pretraining and ImageNet, we demonstrate on up to 128 GPUs that 0/1 Adam is able to reduce up to 90% of data volume, 54% of communication rounds, and achieve up to 2X higher throughput compared to the state-of-the-art 1-bit Adam while enjoying the same statistical convergence speed and end-to-end model accuracy on GLUE dataset and ImageNet validation set.
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model
Feb 04, 2022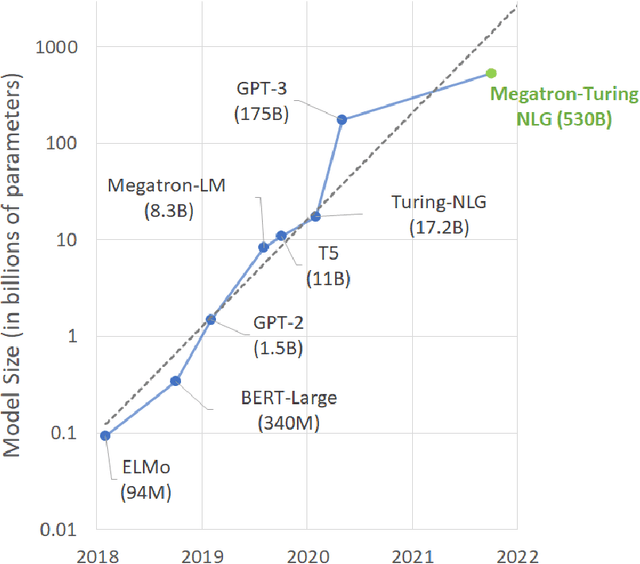
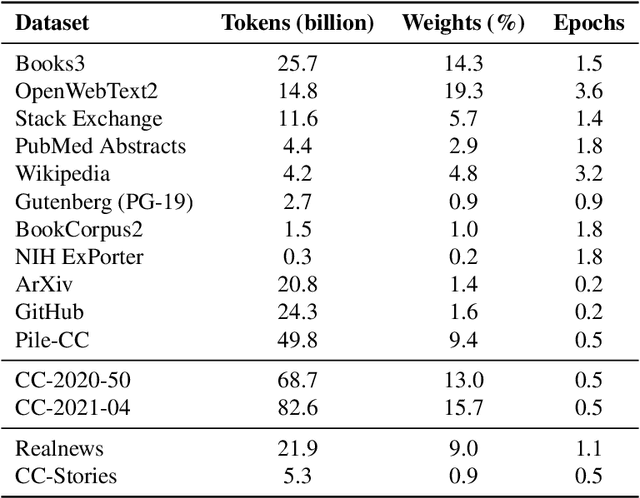
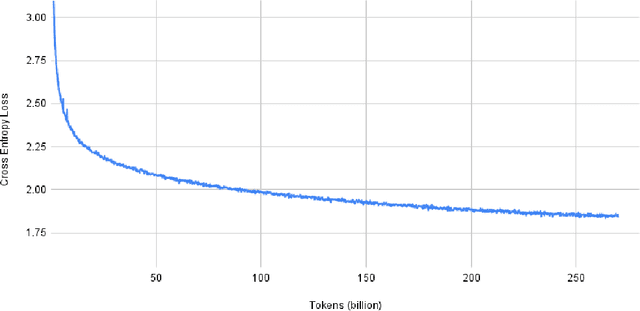
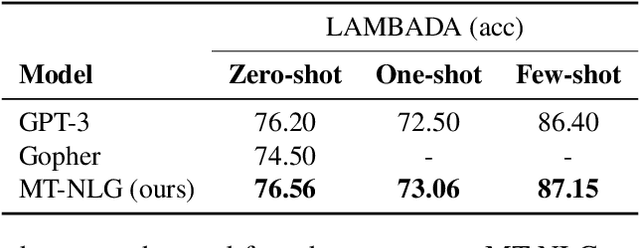
Pretrained general-purpose language models can achieve state-of-the-art accuracies in various natural language processing domains by adapting to downstream tasks via zero-shot, few-shot and fine-tuning techniques. Because of their success, the size of these models has increased rapidly, requiring high-performance hardware, software, and algorithmic techniques to enable training such large models. As the result of a joint effort between Microsoft and NVIDIA, we present details on the training of the largest monolithic transformer based language model, Megatron-Turing NLG 530B (MT-NLG), with 530 billion parameters. In this paper, we first focus on the infrastructure as well as the 3D parallelism methodology used to train this model using DeepSpeed and Megatron. Next, we detail the training process, the design of our training corpus, and our data curation techniques, which we believe is a key ingredient to the success of the model. Finally, we discuss various evaluation results, as well as other interesting observations and new properties exhibited by MT-NLG. We demonstrate that MT-NLG achieves superior zero-, one-, and few-shot learning accuracies on several NLP benchmarks and establishes new state-of-the-art results. We believe that our contributions will help further the development of large-scale training infrastructures, large-scale language models, and natural language generations.
ScaLA: Accelerating Adaptation of Pre-Trained Transformer-Based Language Models via Efficient Large-Batch Adversarial Noise
Jan 29, 2022



In recent years, large pre-trained Transformer-based language models have led to dramatic improvements in many natural language understanding tasks. To train these models with increasing sizes, many neural network practitioners attempt to increase the batch sizes in order to leverage multiple GPUs to improve training speed. However, increasing the batch size often makes the optimization more difficult, leading to slow convergence or poor generalization that can require orders of magnitude more training time to achieve the same model quality. In this paper, we explore the steepness of the loss landscape of large-batch optimization for adapting pre-trained Transformer-based language models to domain-specific tasks and find that it tends to be highly complex and irregular, posing challenges to generalization on downstream tasks. To tackle this challenge, we propose ScaLA, a novel and efficient method to accelerate the adaptation speed of pre-trained transformer networks. Different from prior methods, we take a sequential game-theoretic approach by adding lightweight adversarial noise into large-batch optimization, which significantly improves adaptation speed while preserving model generalization. Experiment results show that ScaLA attains 2.7--9.8$\times$ adaptation speedups over the baseline for GLUE on BERT-base and RoBERTa-large, while achieving comparable and sometimes higher accuracy than the state-of-the-art large-batch optimization methods. Finally, we also address the theoretical aspect of large-batch optimization with adversarial noise and provide a theoretical convergence rate analysis for ScaLA using techniques for analyzing non-convex saddle-point problems.