 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Modular Framework for Single-View 3D Reconstruction of Indoor Environments
Paper and Code
Dec 17, 2025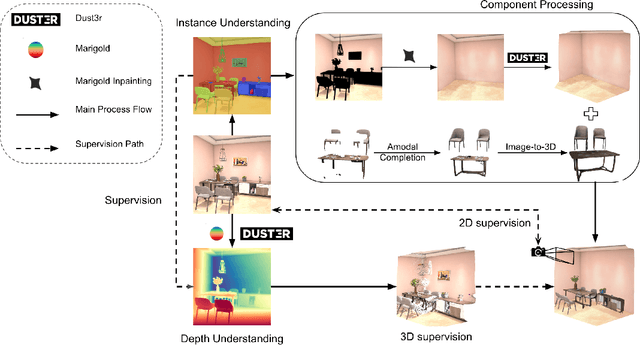

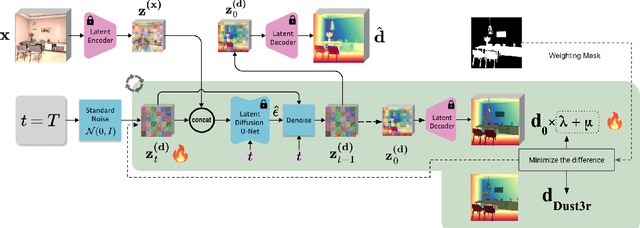
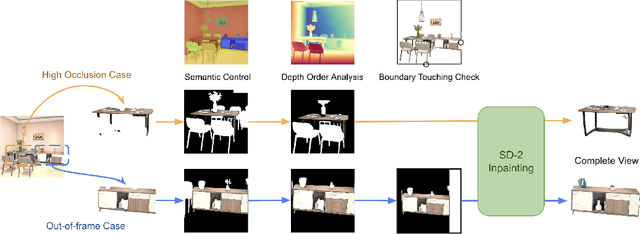
We propose a modular framework for single-view indoor scene 3D reconstruction, where several core modules are powered by diffusion techniques. Traditional approaches for this task often struggle with the complex instance shapes and occlusions inherent in indoor environments. They frequently overshoot by attempting to predict 3D shapes directly from incomplete 2D images, which results in limited reconstruction quality. We aim to overcome this limitation by splitting the process into two steps: first, we employ diffusion-based techniques to predict the complete views of the room background and occluded indoor instances, then transform them into 3D. Our modular framework makes contributions to this field through the following components: an amodal completion module for restoring the full view of occluded instances, an inpainting model specifically trained to predict room layouts, a hybrid depth estimation technique that balances overall geometric accuracy with fine detail expressiveness, and a view-space alignment method that exploits both 2D and 3D cues to ensure precise placement of instances within the scene. This approach effectively reconstructs both foreground instances and the room background from a single image. Extensive experiments on the 3D-Front dataset demonstrate that our method outperforms current state-of-the-art (SOTA) approaches in terms of both visual quality and reconstruction accuracy. The framework holds promising potential for applications in interior design, real estate, and augmented reality.