 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics informed cell representations for variational formulation of multiscale problems
May 27, 2024With the rapid advancement of graphical processing units, Physics-Informed Neural Networks (PINNs) are emerging as a promising tool for solving partial differential equations (PDEs). However, PINNs are not well suited for solving PDEs with multiscale features, particularly suffering from slow convergence and poor accuracy. To address this limitation of PINNs, this article proposes physics-informed cell representations for resolving multiscale Poisson problems using a model architecture consisting of multilevel multiresolution grids coupled with a multilayer perceptron (MLP). The grid parameters (i.e., the level-dependent feature vectors) and the MLP parameters (i.e., the weights and biases) are determined using gradient-descent based optimization. The variational (weak) form based loss function accelerates computation by allowing the linear interpolation of feature vectors within grid cells. This cell-based MLP model also facilitates the use of a decoupled training scheme for Dirichlet boundary conditions and a parameter-sharing scheme for periodic boundary conditions, delivering superior accuracy compared to conventional PINNs. Furthermore, the numerical examples highlight improved speed and accuracy in solving PDEs with nonlinear or high-frequency boundary conditions and provide insights into hyperparameter selection. In essence, by cell-based MLP model along with the parallel tiny-cuda-nn library, our implementation improves convergence speed and numerical accuracy.
Group-Aware Robot Navigation in Crowded Environments
Dec 22, 2020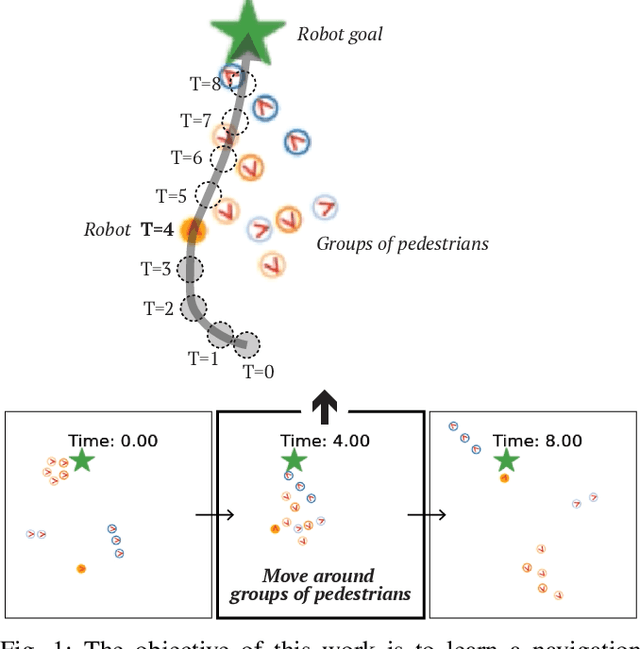

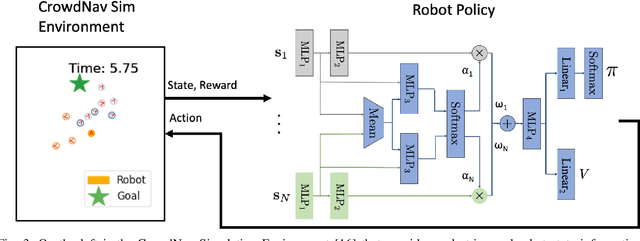
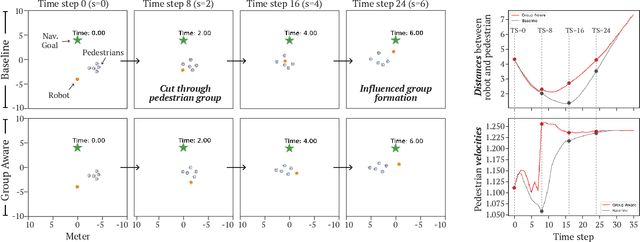
Human-aware robot navigation promises a range of applications in which mobile robots bring versatile assistance to people in common human environments. While prior research has mostly focused on modeling pedestrians as independent, intentional individuals, people move in groups; consequently, it is imperative for mobile robots to respect human groups when navigating around people. This paper explores learning group-aware navigation policies based on dynamic group formation using deep reinforcement learning. Through simulation experiments, we show that group-aware policies, compared to baseline policies that neglect human groups, achieve greater robot navigation performance (e.g., fewer collisions), minimize violation of social norms and discomfort, and reduce the robot's movement impact on pedestrians. Our results contribute to the development of social navigation and the integration of mobile robots into human environments.
A Novel Co-design Peta-scale Heterogeneous Cluster for Deep Learning Training
May 18, 2018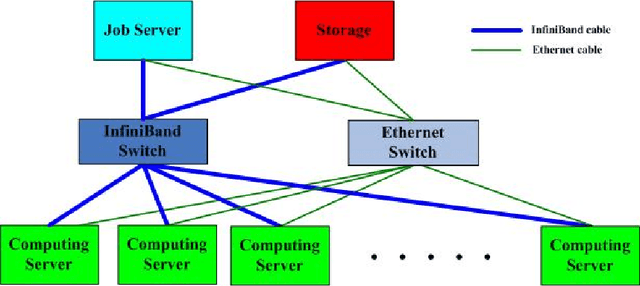
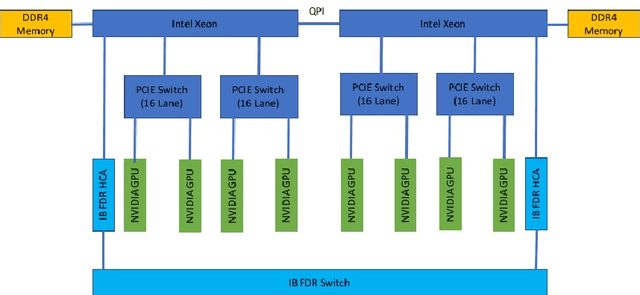
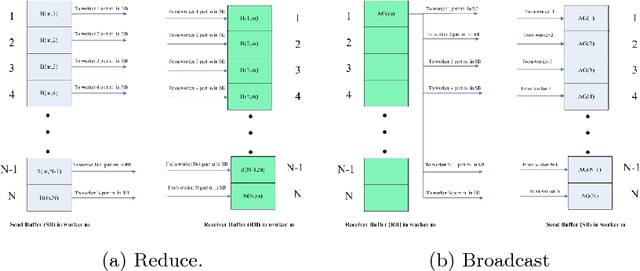
Large scale deep Convolution Neural Networks (CNNs) increasingly demands the computing power. It is key for researchers to own a great powerful computing platform to leverage deep learning (DL) advancing.On the other hand, as the commonly-used accelerator, the commodity GPUs cards of new generations are more and more expensive. Consequently, it is of importance to design an affordable distributed heterogeneous system that provides powerful computational capacity and develop a well-suited software that efficiently utilizes its computational capacity. In this paper, we present our co-design distributed system including a peta-scale GPU cluster, called "Manoa". Based on properties and topology of Manoa, we first propose job server framework and implement it, named "MiMatrix". The central node of MiMatrix, referred to as the job server, undertakes all of controlling, scheduling and monitoring, and I/O tasks without weight data transfer for AllReduce processing in each iteration. Therefore, MiMatrix intrinsically solves the bandwidth bottleneck of central node in parameter server framework that is widely used in distributed DL tasks. Meanwhile, we also propose a new AllReduce algorithm, GPUDirect RDMA-Aware AllReduce~(GDRAA), in which both computation and handshake message are O(1) and the number of synchronization is two in each iteration that is a theoretical minimum number. Owe to the dedicated co-design distributed system, MiMatrix efficiently makes use of the Manoa's computational capacity and bandwidth. We benchmark Manoa Resnet50 and Resenet101 on Imagenet-1K dataset. Some of results have demonstrated state-of-the-art.