 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Cost and Constraints with Off-Policy Deep Reinforcement Learning
Nov 30, 2023By reusing data throughout training, off-policy deep reinforcement learning algorithms offer improved sample efficiency relative to on-policy approaches. For continuous action spaces, the most popular methods for off-policy learning include policy improvement steps where a learned state-action ($Q$) value function is maximized over selected batches of data. These updates are often paired with regularization to combat associated overestimation of $Q$ values. With an eye toward safety, we revisit this strategy in environments with "mixed-sign" reward functions; that is, with reward functions that include independent positive (incentive) and negative (cost) terms. This setting is common in real-world applications, and may be addressed with or without constraints on the cost terms. We find the combination of function approximation and a term that maximizes $Q$ in the policy update to be problematic in such environments, because systematic errors in value estimation impact the contributions from the competing terms asymmetrically. This results in overemphasis of either incentives or costs and may severely limit learning. We explore two remedies to this issue. First, consistent with prior work, we find that periodic resetting of $Q$ and policy networks can be used to reduce value estimation error and improve learning in this setting. Second, we formulate novel off-policy actor-critic methods for both unconstrained and constrained learning that do not explicitly maximize $Q$ in the policy update. We find that this second approach, when applied to continuous action spaces with mixed-sign rewards, consistently and significantly outperforms state-of-the-art methods augmented by resetting. We further find that our approach produces agents that are both competitive with popular methods overall and more reliably competent on frequently-studied control problems that do not have mixed-sign rewards.
Clipped-Objective Policy Gradients for Pessimistic Policy Optimization
Nov 10, 2023



To facilitate efficient learning, policy gradient approaches to deep reinforcement learning (RL) are typically paired with variance reduction measures and strategies for making large but safe policy changes based on a batch of experiences. Natural policy gradient methods, including Trust Region Policy Optimization (TRPO), seek to produce monotonic improvement through bounded changes in policy outputs. Proximal Policy Optimization (PPO) is a commonly used, first-order algorithm that instead uses loss clipping to take multiple safe optimization steps per batch of data, replacing the bound on the single step of TRPO with regularization on multiple steps. In this work, we find that the performance of PPO, when applied to continuous action spaces, may be consistently improved through a simple change in objective. Instead of the importance sampling objective of PPO, we instead recommend a basic policy gradient, clipped in an equivalent fashion. While both objectives produce biased gradient estimates with respect to the RL objective, they also both display significantly reduced variance compared to the unbiased off-policy policy gradient. Additionally, we show that (1) the clipped-objective policy gradient (COPG) objective is on average "pessimistic" compared to both the PPO objective and (2) this pessimism promotes enhanced exploration. As a result, we empirically observe that COPG produces improved learning compared to PPO in single-task, constrained, and multi-task learning, without adding significant computational cost or complexity. Compared to TRPO, the COPG approach is seen to offer comparable or superior performance, while retaining the simplicity of a first-order method.
A Risk-Sensitive Approach to Policy Optimization
Aug 19, 2022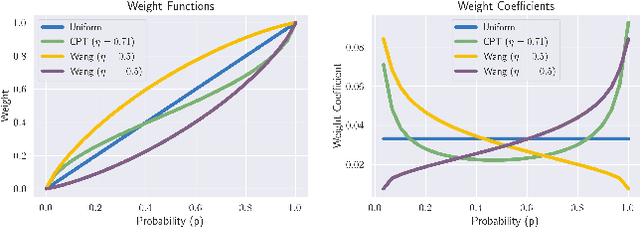
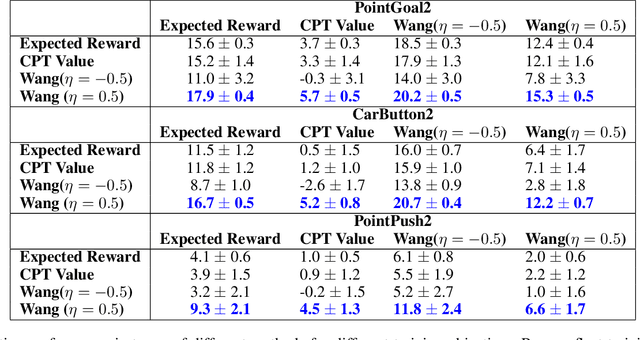
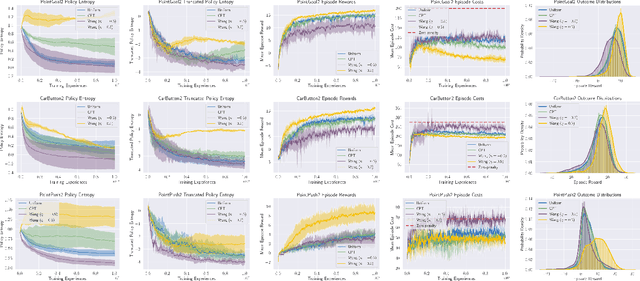
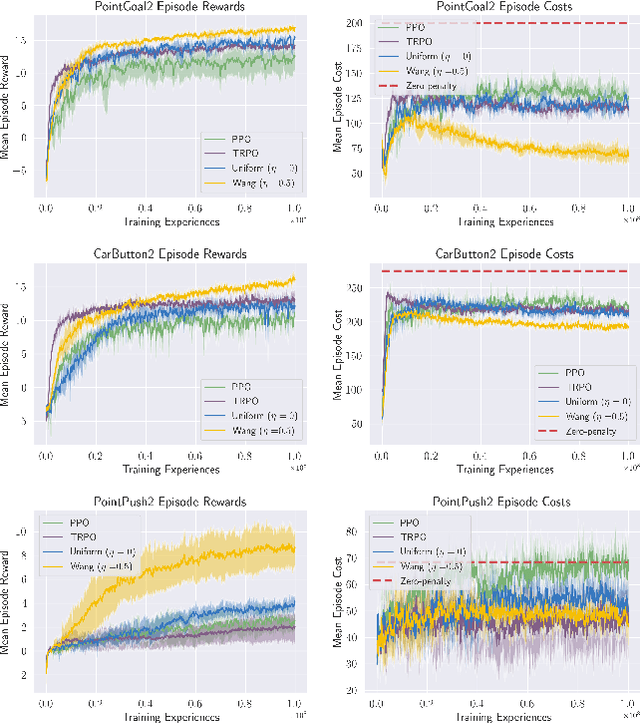
Standard deep reinforcement learning (DRL) aims to maximize expected reward, considering collected experiences equally in formulating a policy. This differs from human decision-making, where gains and losses are valued differently and outlying outcomes are given increased consideration. It also fails to capitalize on opportunities to improve safety and/or performance through the incorporation of distributional context. Several approaches to distributional DRL have been investigated, with one popular strategy being to evaluate the projected distribution of returns for possible actions. We propose a more direct approach whereby risk-sensitive objectives, specified in terms of the cumulative distribution function (CDF) of the distribution of full-episode rewards, are optimized. This approach allows for outcomes to be weighed based on relative quality, can be used for both continuous and discrete action spaces, and may naturally be applied in both constrained and unconstrained settings. We show how to compute an asymptotically consistent estimate of the policy gradient for a broad class of risk-sensitive objectives via sampling, subsequently incorporating variance reduction and regularization measures to facilitate effective on-policy learning. We then demonstrate that the use of moderately "pessimistic" risk profiles, which emphasize scenarios where the agent performs poorly, leads to enhanced exploration and a continual focus on addressing deficiencies. We test the approach using different risk profiles in six OpenAI Safety Gym environments, comparing to state of the art on-policy methods. Without cost constraints, we find that pessimistic risk profiles can be used to reduce cost while improving total reward accumulation. With cost constraints, they are seen to provide higher positive rewards than risk-neutral approaches at the prescribed allowable cost.
Triangular Dropout: Variable Network Width without Retraining
May 02, 2022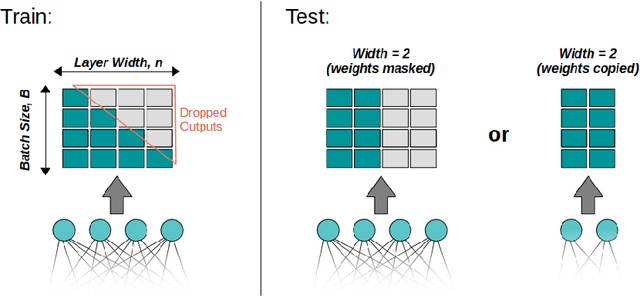
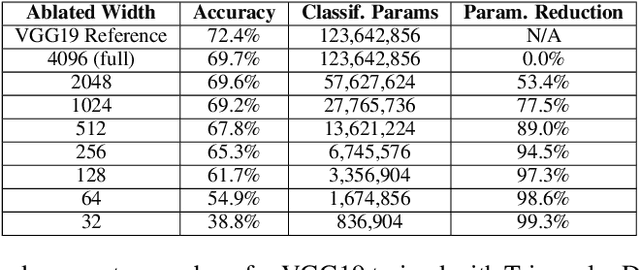
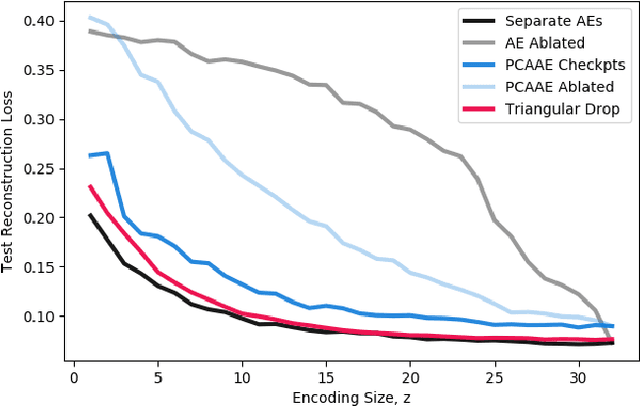
One of the most fundamental design choices in neural networks is layer width: it affects the capacity of what a network can learn and determines the complexity of the solution. This latter property is often exploited when introducing information bottlenecks, forcing a network to learn compressed representations. However, such an architecture decision is typically immutable once training begins; switching to a more compressed architecture requires retraining. In this paper we present a new layer design, called Triangular Dropout, which does not have this limitation. After training, the layer can be arbitrarily reduced in width to exchange performance for narrowness. We demonstrate the construction and potential use cases of such a mechanism in three areas. Firstly, we describe the formulation of Triangular Dropout in autoencoders, creating models with selectable compression after training. Secondly, we add Triangular Dropout to VGG19 on ImageNet, creating a powerful network which, without retraining, can be significantly reduced in parameters. Lastly, we explore the application of Triangular Dropout to reinforcement learning (RL) policies on selected control problems.
Meta Arcade: A Configurable Environment Suite for Meta-Learning
Dec 01, 2021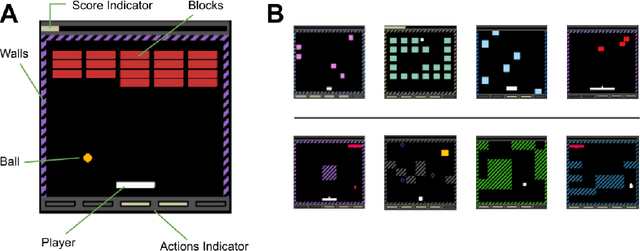
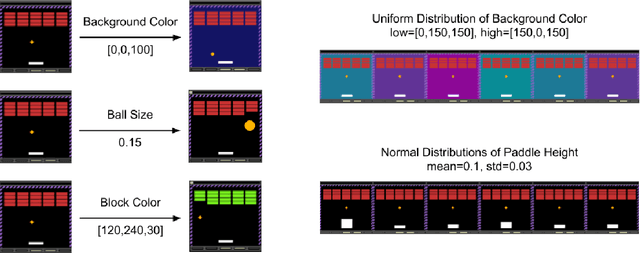
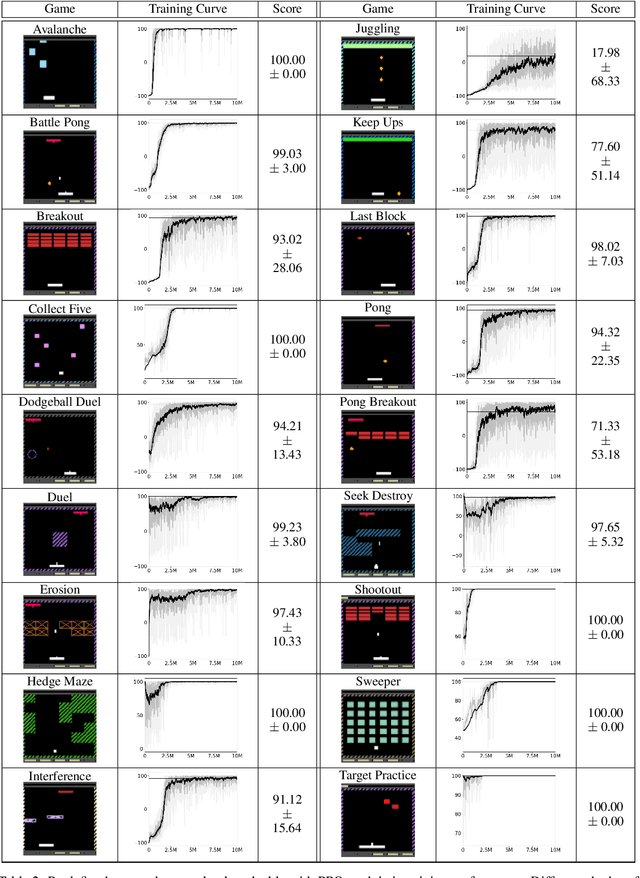
Most approaches to deep reinforcement learning (DRL) attempt to solve a single task at a time. As a result, most existing research benchmarks consist of individual games or suites of games that have common interfaces but little overlap in their perceptual features, objectives, or reward structures. To facilitate research into knowledge transfer among trained agents (e.g. via multi-task and meta-learning), more environment suites that provide configurable tasks with enough commonality to be studied collectively are needed. In this paper we present Meta Arcade, a tool to easily define and configure custom 2D arcade games that share common visuals, state spaces, action spaces, game components, and scoring mechanisms. Meta Arcade differs from prior environments in that both task commonality and configurability are prioritized: entire sets of games can be constructed from common elements, and these elements are adjustable through exposed parameters. We include a suite of 24 predefined games that collectively illustrate the possibilities of this framework and discuss how these games can be configured for research applications. We provide several experiments that illustrate how Meta Arcade could be used, including single-task benchmarks of predefined games, sample curriculum-based approaches that change game parameters over a set schedule, and an exploration of transfer learning between games.
Group-Aware Robot Navigation in Crowded Environments
Dec 22, 2020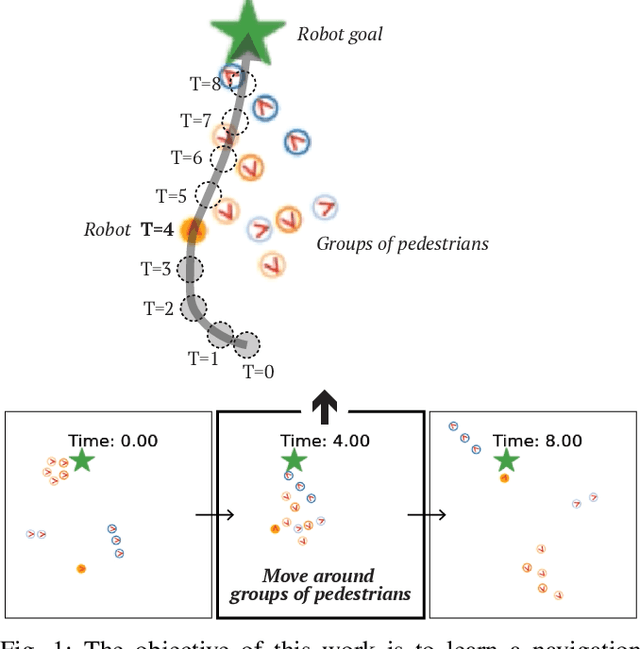

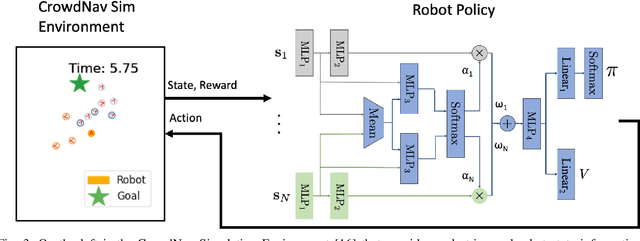
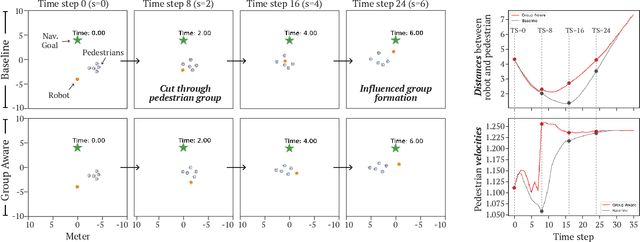
Human-aware robot navigation promises a range of applications in which mobile robots bring versatile assistance to people in common human environments. While prior research has mostly focused on modeling pedestrians as independent, intentional individuals, people move in groups; consequently, it is imperative for mobile robots to respect human groups when navigating around people. This paper explores learning group-aware navigation policies based on dynamic group formation using deep reinforcement learning. Through simulation experiments, we show that group-aware policies, compared to baseline policies that neglect human groups, achieve greater robot navigation performance (e.g., fewer collisions), minimize violation of social norms and discomfort, and reduce the robot's movement impact on pedestrians. Our results contribute to the development of social navigation and the integration of mobile robots into human environments.
Objectness-Guided Open Set Visual Search and Closed Set Detection
Dec 11, 2020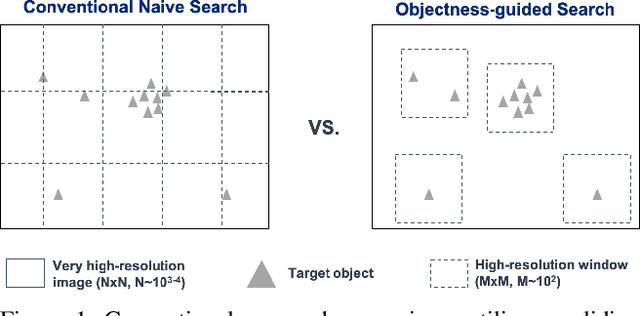

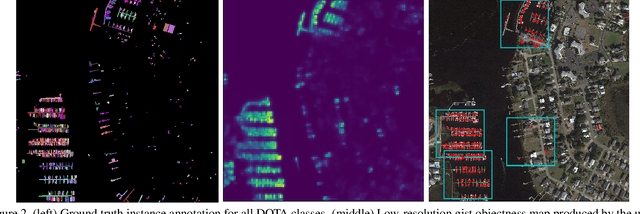
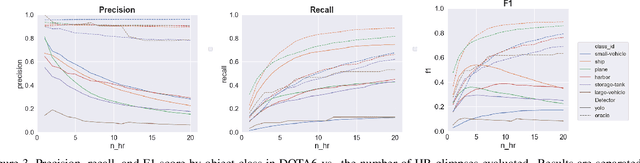
Searching for small objects in large images is currently challenging for deep learning systems, but is a task with numerous applications including remote sensing and medical imaging. Thorough scanning of very large images is computationally expensive, particularly at resolutions sufficient to capture small objects. The smaller an object of interest, the more likely it is to be obscured by clutter or otherwise deemed insignificant. We examine these issues in the context of two complementary problems: closed-set object detection and open-set target search. First, we present a method for predicting pixel-level objectness from a low resolution gist image, which we then use to select regions for subsequent evaluation at high resolution. This approach has the benefit of not being fixed to a predetermined grid, allowing fewer costly high-resolution glimpses than existing methods. Second, we propose a novel strategy for open-set visual search that seeks to find all objects in an image of the same class as a given target reference image. We interpret both detection problems through a probabilistic, Bayesian lens, whereby the objectness maps produced by our method serve as priors in a maximum-a-posteriori approach to the detection step. We evaluate the end-to-end performance of both the combination of our patch selection strategy with this target search approach and the combination of our patch selection strategy with standard object detection methods. Both our patch selection and target search approaches are seen to significantly outperform baseline strategies.
On the Complexity of Reconnaissance Blind Chess
Nov 07, 2018
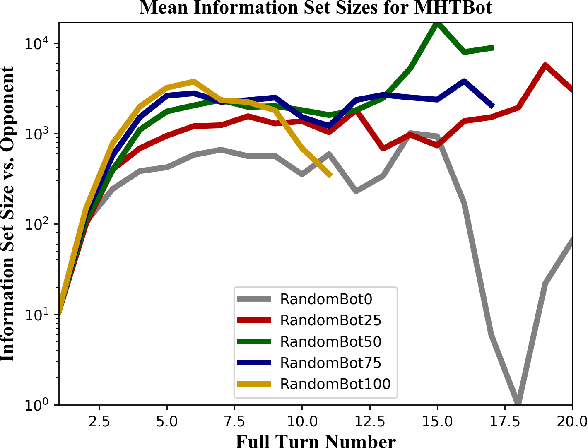

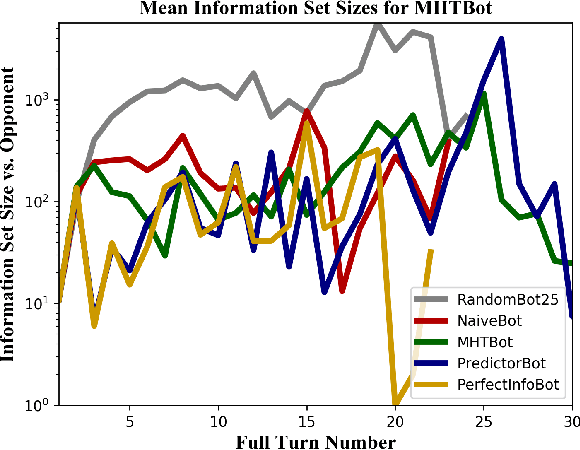
This paper provides a complexity analysis for the game of reconnaissance blind chess (RBC), a recently-introduced variant of chess where each player does not know the positions of the opponent's pieces a priori but may reveal a subset of them through chosen, private sensing actions. In contrast to commonly studied imperfect information games like poker and Kriegspiel, an RBC player does not know what the opponent knows or has chosen to learn, exponentially expanding the size of the game's information sets (i.e., the number of possible game states that are consistent with what a player has observed). Effective RBC sensing and moving strategies must account for the uncertainty of both players, an essential element of many real-world decision-making problems. Here we evaluate RBC from a game theoretic perspective, tracking the proliferation of information sets from the perspective of selected canonical bot players in tournament play. We show that, even for effective sensing strategies, the game sizes of RBC compare to those of Go while the average size of a player's information set throughout an RBC game is much greater than that of a player in Heads-up Limit Hold 'Em. We compare these measures of complexity among different playing algorithms and provide cursory assessments of the various sensing and moving strategies.
Combining Deep Universal Features, Semantic Attributes, and Hierarchical Classification for Zero-Shot Learning
Dec 08, 2017
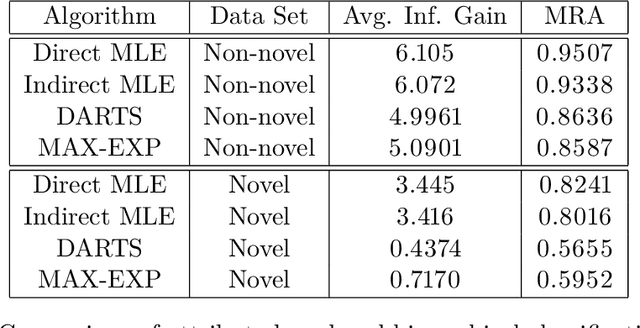
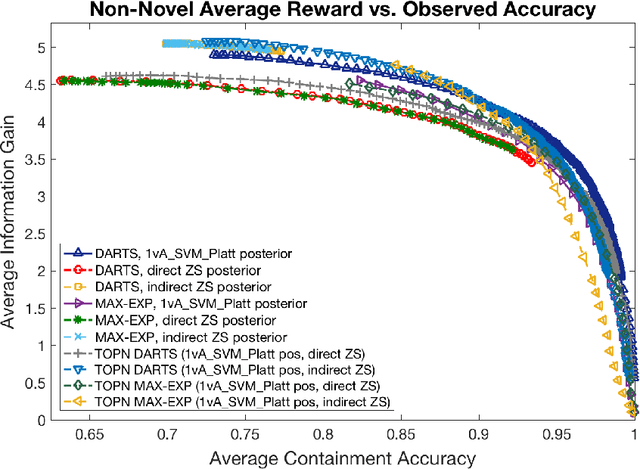
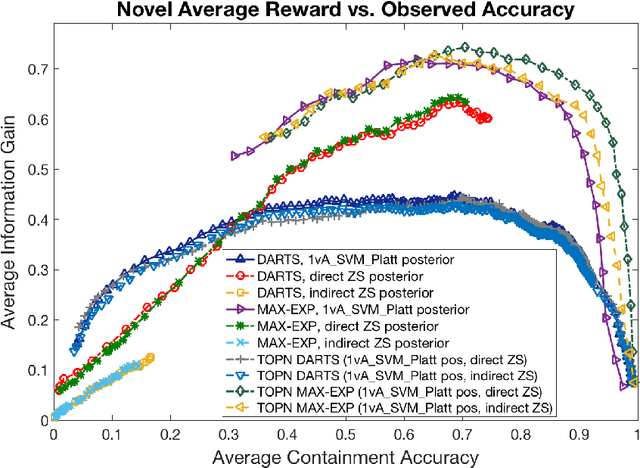
We address zero-shot (ZS) learning, building upon prior work in hierarchical classification by combining it with approaches based on semantic attribute estimation. For both non-novel and novel image classes we compare multiple formulations of the problem, starting with deep universal features in each case. We investigate the effect of using different posterior probabilities as inputs to the hierarchical classifier, comparing the performances of posteriors derived from distances to SVM classifier boundaries with those of posteriors based on semantic attribute estimation. Using a dataset consisting of 150 object classes from the ImageNet ILSVRC2012 data set, we find that the hierarchical classification method that maximizes expected reward for non-novel classes differs from the method that maximizes expected reward for novel classes. We also show that using input posteriors based on semantic attributes improves the expected reward for novel classes.